奇异分解(SVD)理论介绍
Posted yifanrensheng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了奇异分解(SVD)理论介绍相关的知识,希望对你有一定的参考价值。
一、前言
奇异值分解(Singular Value Decomposition,以下简称SVD)是在机器学习领域广泛应用的算法,主要应用如下:
信息检索(LSA:隐性语义索引,LSA:隐性语义分析),分解后的奇异值代表了文章的主题或者概念,信息检索的时候同义词,或者说同一主题下的词会映射为同一主题,这样就可以提高搜索效率
数据压缩:通过奇异值分解,选择能量较大的前N个奇异值来代替所有的数据信息,这样可以降低噪声,节省空间。
推荐系统:主要是降噪,矩阵变换至低维空间(分解后还原的矩阵元素值作为原本缺失值的一种近似),方便计算(目前没有意识到它对推荐精确度的提升有什么具体作用)。
二、奇异值与特征值基础知识:


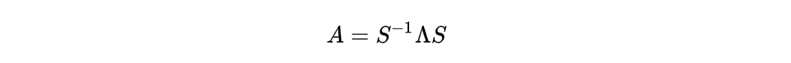
特征值分解的方法比较简单,有趣的是探究什么样的矩阵可以进行特征值分解以及矩阵进行特征值分解之后展现出的矩阵有意思的性质。特征向量矩阵S 是一个正交矩阵,一般写作 Q,也就是实对称矩阵的特征值分解可以写作:
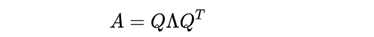
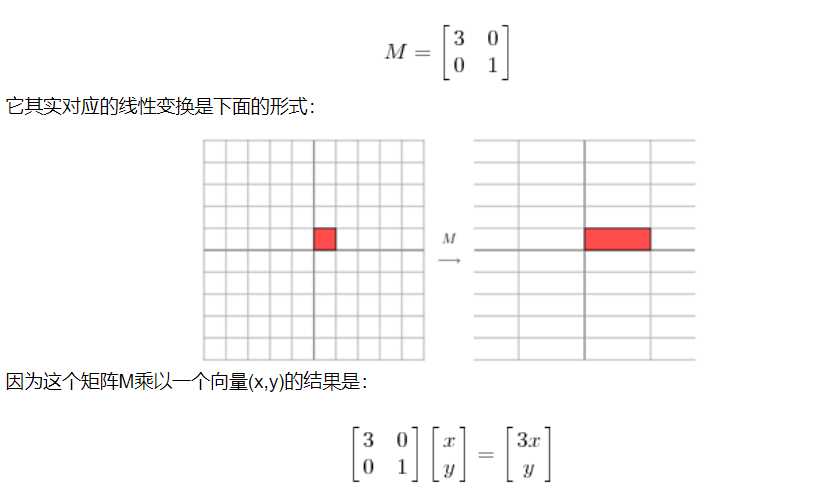
首先,要明确的是,一个矩阵其实相当于一个线性变换,因为一个矩阵乘以一个向量后得到的向量,其实就相当于将这个向量进行了线性变换。比如说下面的一个矩阵:
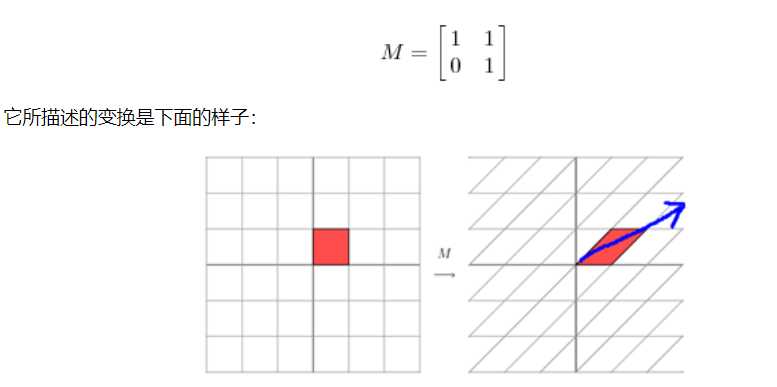
这其实是在平面上对一个轴进行的拉伸变换(如蓝色的箭头所示),在图中,蓝色的箭头是一个最主要的变化方向(变化方向可能有不止一个),如果我们想要描述好一个变换,那我们就描述好这个变换主要的变化方向就好了。
特征值分解也有很多的局限,比如说变换的矩阵必须是方阵。我们看到的大部分矩阵都不是方阵,故引入了以下的奇异分解
三、奇异分解
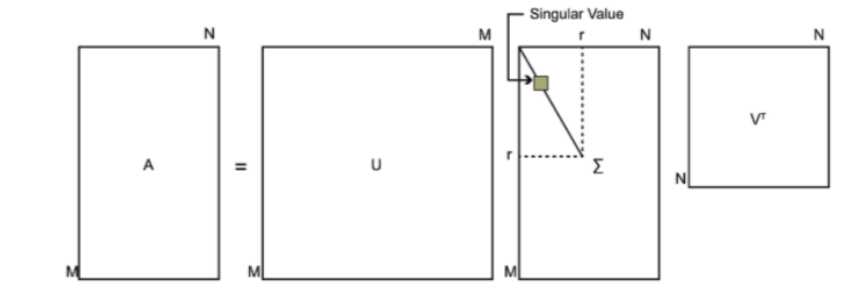
综述:SVD又称奇异值分解,是线性代数中一种矩阵分解的技术,它能够将任意一个m*n的矩阵A分解成为U、S、V,U是m*m的正交矩阵,S是m*n的矩阵,V是n*n的正交矩阵(分解成为U、S、V,U是m*k的正交矩阵,S是k*k的矩阵,V是k*n的正交矩阵,k为),且A=U*S*V。通过SVD方式将矩阵A分解后,如果只保留前k个最大的奇异值,就实现了对矩阵降维的目的。我们之所以能够通过保留前k个最大的奇异值来实现降维,是因为在很多情况下,前10%甚至1%的奇异值的和就占了全部的奇异值之和的99%以上的比例。尽管我们能够通过降维来减少运算量,但是k值的选取是我们需要面对的重要问题。如果k值选的过大,那么降维的意义就不大;如果k值选的过小,那么降维之后就有可能丢失重要信息。下面通过一个例子来具体说明SVD算法在推荐系统中的应用。
奇异值:
如图一所示假设有 m×n的矩阵 A ,那么 SVD 就是要找到如下式的这么一个分解,将 A 分解为 3 个矩阵的乘积:
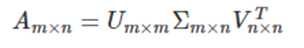
其中,Σ就是一个非负实对角矩阵。U 和 V都是正交矩阵 (Orthogonal Matrix),在复数域内的话就是酉矩阵(Unitary Matrix),即
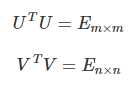
换句话说,就是说 U 的转置等于 U 的逆,V 的转置等于 V的逆:
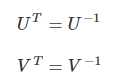
具体证明:

另外,为了简化计算,可以将上图做进一步调整,如下所示:
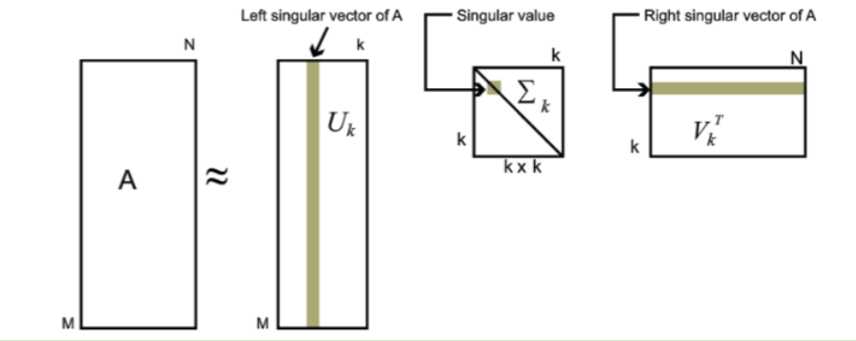


这里我们取的是 m 和 n 维标准正交基来构成矩阵 U 和 V ,此外根据取值数量的不同,还有紧奇异值分解与截断奇异值分解,分别表示只取 r 组(矩阵的秩)以及前 k 大的奇异值。这是用于压缩的关键。如上面两个图所示。
满秩奇异值分解的另一种解读:
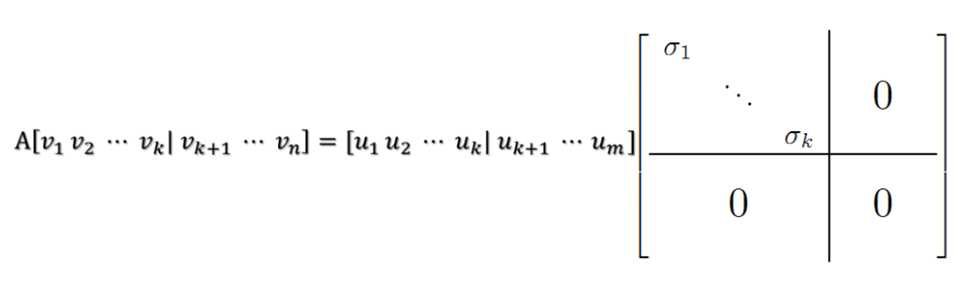
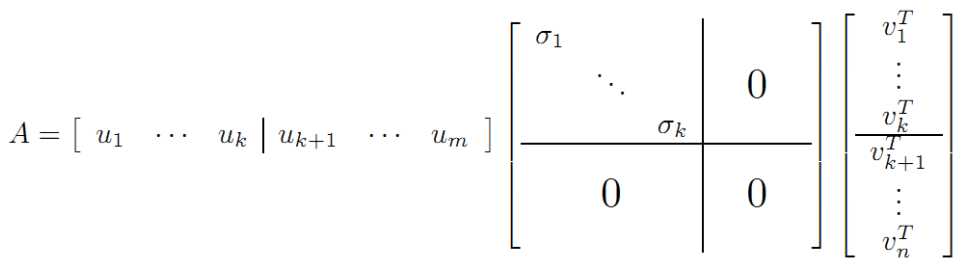
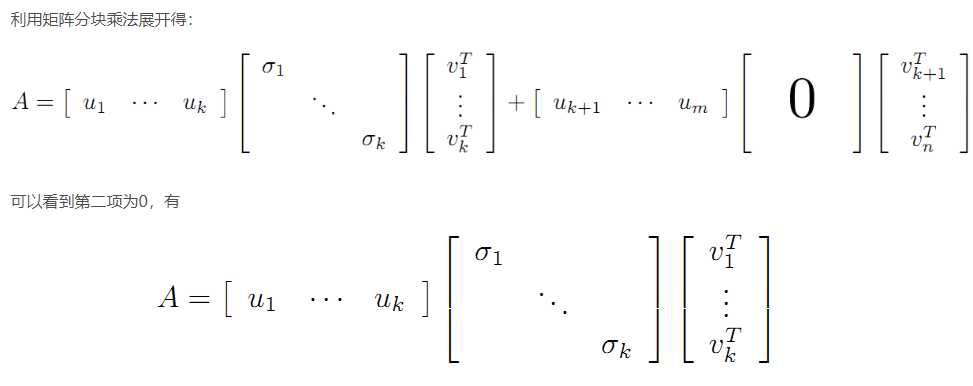
四、奇异值的计算
U 和 V 的列分别叫做 A的 左奇异向量(left-singular vectors)和 右奇异向量(right-singular vectors),Σ的对角线上的值叫做 A 的奇异值(singular values)。
其实整个求解 SVD 的过程就是求解这 3 个矩阵的过程,而求解这 3 个矩阵的过程就是求解特征值和特征向量的过程,问题就在于 求谁的特征值和特征向量。

但奇异值的计算是一个难题,是一个O(N^3)的算法。在单机的情况下当然是没问题的,matlab在一秒钟内就可以算出1000 * 1000的矩阵的所有奇异值,但是当矩阵的规模增长的时候,计算的复杂度呈3次方增长,就需要并行计算参与了。Google的吴军老师在数学之美系列谈到SVD的时候,说起Google实现了SVD的并行化算法,说这是对人类的一个贡献,但是也没有给出具体的计算规模,也没有给出太多有价值的信息。
其实SVD还是可以用并行的方式去实现的,在解大规模的矩阵的时候,一般使用迭代的方法,当矩阵的规模很大(比如说上亿)的时候,迭代的次数也可能会上亿次,如果使用Map-Reduce框架去解,则每次Map-Reduce完成的时候,都会涉及到写文件、读文件的操作。个人猜测Google云计算体系中除了Map-Reduce以外应该还有类似于MPI的计算模型,也就是节点之间是保持通信,数据是常驻在内存中的,这种计算模型比Map-Reduce在解决迭代次数非常多的时候,要快了很多倍。
Lanczos迭代就是一种解对称方阵部分特征值的方法(之前谈到了,解A‘* A得到的对称方阵的特征值就是解A的右奇异向量),是将一个对称的方程化为一个三对角矩阵再进行求解。按网上的一些文献来看,Google应该是用这种方法去做的奇异值分解的。请见Wikipedia上面的一些引用的论文,如果理解了那些论文,也"几乎"可以做出一个SVD了。
由于奇异值的计算是一个很枯燥,纯数学的过程,而且前人的研究成果(论文中)几乎已经把整个程序的流程图给出来了。更多的关于奇异值计算的部分,将在后面的参考文献中给出,这里不再深入,我还是focus在奇异值的应用中去。
五、降维示例应用:
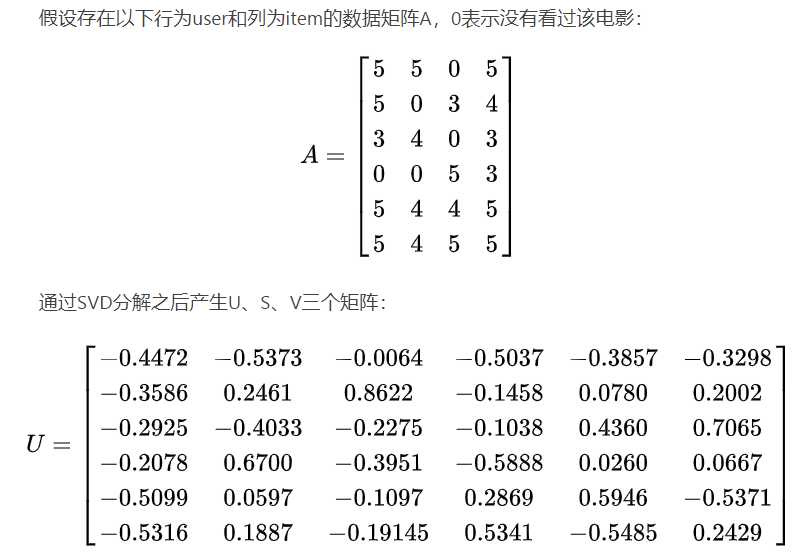
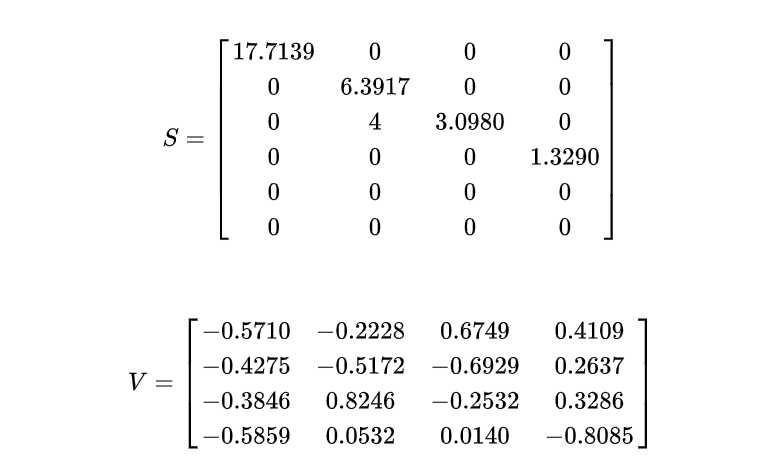
此时,我们选取k=2来对U,S,V进行降维,k=2即表示我们默认该数据集含有两个隐形因子:

此时我们通过降维后的U、S、V相乘来得到A‘:

通过矩阵A和A‘的比较,我们可以很直观的看出这两个矩阵十分相似。
文章参考:
https://zhuanlan.zhihu.com/p/69540876 --基本思路
https://www.cnblogs.com/LeftNotEasy/archive/2011/01/19/svd-and-applications.html --基本思路
https://blog.csdn.net/zhongkejingwang/article/details/43053513 --满秩分解的说明
https://www.cnblogs.com/pinard/p/6251584.html#!comments --较详细的说明
https://www.cnblogs.com/xiaohuahua108/p/6137783.html --SVD案例分析
以上是关于奇异分解(SVD)理论介绍的主要内容,如果未能解决你的问题,请参考以下文章