关系型数据库同步
Posted hnxxcxg
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了关系型数据库同步相关的知识,希望对你有一定的参考价值。
关系型数据库同步
1)、全量同步
比如从oracle数据库中同步一张表的数据到mysql中,通常的做法就是分页查询源端的表,然后通过数据库引擎批量(比如JDBC)插入到目标表,这个地方需要注意的是,分页查询时,一定要按照主键id来排序分页,避免重复插入。
2)、基于数据文件导出和导入的全量同步,这种同步方式一般只适用于同种数据库之间的同步,如果是不同的数据库,这种方式可能会存在问题。
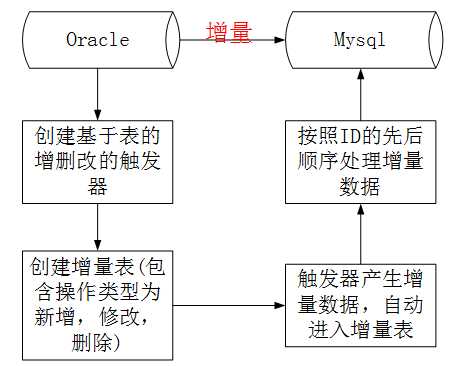
3)、基于触发器的增量同步
增量同步一般是做实时的同步,早期很多数据同步都是基于关系型数据库的触发器trigger来做的。
使用触发器实时同步数据的步骤:
A、 基于原表创触发器,触发器包含insert,modify,delete 三种类型的操作,数据库的触发器分Before和After两种情况,一种是在insert,modify,delete 三种类型的操作发生之前触发(比如记录日志操作,一般是Before),一种是在insert,modify,delete 三种类型的操作之后触发。
B、 创建增量表,增量表中的字段和原表中的字段完全一样,但是需要多一个操作类型字段(分表代表insert,modify,delete 三种类型的操作),并且需要一个唯一自增ID,代表数据原表中数据操作的顺序,这个自增id非常重要,不然数据同步就会错乱。
C、 原表中出现insert,modify,delete 三种类型的操作时,通过触发器自动产生增量数据,插入增量表中。
D、处理增量表中的数据,处理时,一定是按照自增id的顺序来处理,这种效率会非常低,没办法做批量操作,不然数据会错乱。 有人可能会说,是不是可以把insert操作合并在一起,modify合并在一起,delete操作合并在一起,然后批量处理,我给的答案是不行,因为数据的增删改是有顺序的,合并后,就没有顺序了,同一条数据的增删改顺序一旦错了,那数据同步就肯定错了。
市面上很多数据交换产品都是基于这种思想来做的。
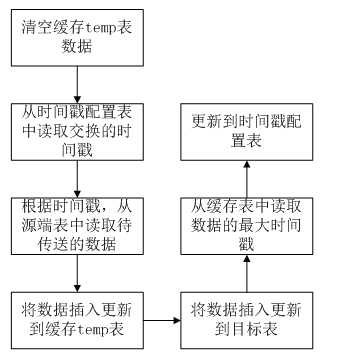
4)、基于时间戳的增量同步
A、首先我们需要一张临时temp表,用来存取每次读取的待同步的数据,也就是把每次从原表中根据时间戳读取到数据先插入到临时表中,每次在插入前,先清空临时表的数据
B、我们还需要创建一个时间戳配置表,用于存放每次读取的处理完的数据的最后的时间戳。
C、每次从原表中读取数据时,先查询时间戳配置表,然后就知道了查询原表时的开始时间戳。
D、根据时间戳读取到原表的数据,插入到临时表中,然后再将临时表中的数据插入到目标表中。
E、从缓存表中读取出数据的最大时间戳,并且更新到时间戳配置表中。缓存表的作用就是使用sql获取每次读取到的数据的最大的时间戳,当然这些都是完全基于sql语句在kettle中来配置,才需要这样的一张临时表。
以上是关于关系型数据库同步的主要内容,如果未能解决你的问题,请参考以下文章
20.elasticsearch-jdbc实现MySQL同步到ElasticSearch(ES与关系型数据库同步)
ES 译文之如何使用 Logstash 实现关系型数据库与 ElasticSearch 之间的数据同步
同步关系数据库时出现 Microsoft Sync 框架问题