python 将多个数据图绘制到一张图上
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python 将多个数据图绘制到一张图上相关的知识,希望对你有一定的参考价值。
我有一大组数据,每一行生成了一个拟合曲线,但是每次都得手动把上一行生成的关掉才会出现下一行的,请问如何能在一张图中画出所有拟合曲线,以便于作比较
参考技术A 假设有9张图, 化成3行3列plt.subplot(331)
plt.plot(...)
plt.subplot(332)
plt.plot(...)
...
plt.subplot(339)
plt.plot(...)
python 将多个模型的ROC曲线绘制在一张图里(含图例)
一. 多条ROC曲线绘制函数
def multi_models_roc(names, sampling_methods, colors, X_test, y_test, save=True, dpin=100):
"""
将多个机器模型的roc图输出到一张图上
Args:
names: list, 多个模型的名称
sampling_methods: list, 多个模型的实例化对象
save: 选择是否将结果保存(默认为png格式)
Returns:
返回图片对象plt
"""
plt.figure(figsize=(20, 20), dpi=dpin)
for (name, method, colorname) in zip(names, sampling_methods, colors):
y_test_preds = method.predict(X_test)
y_test_predprob = method.predict_proba(X_test)[:,1]
fpr, tpr, thresholds = roc_curve(y_test, y_test_predprob, pos_label=1)
plt.plot(fpr, tpr, lw=5, label=' (AUC=:.3f)'.format(name, auc(fpr, tpr)),color = colorname)
plt.plot([0, 1], [0, 1], '--', lw=5, color = 'grey')
plt.axis('square')
plt.xlim([0, 1])
plt.ylim([0, 1])
plt.xlabel('False Positive Rate',fontsize=20)
plt.ylabel('True Positive Rate',fontsize=20)
plt.title('ROC Curve',fontsize=25)
plt.legend(loc='lower right',fontsize=20)
if save:
plt.savefig('multi_models_roc.png')
return plt
二.绘制效果
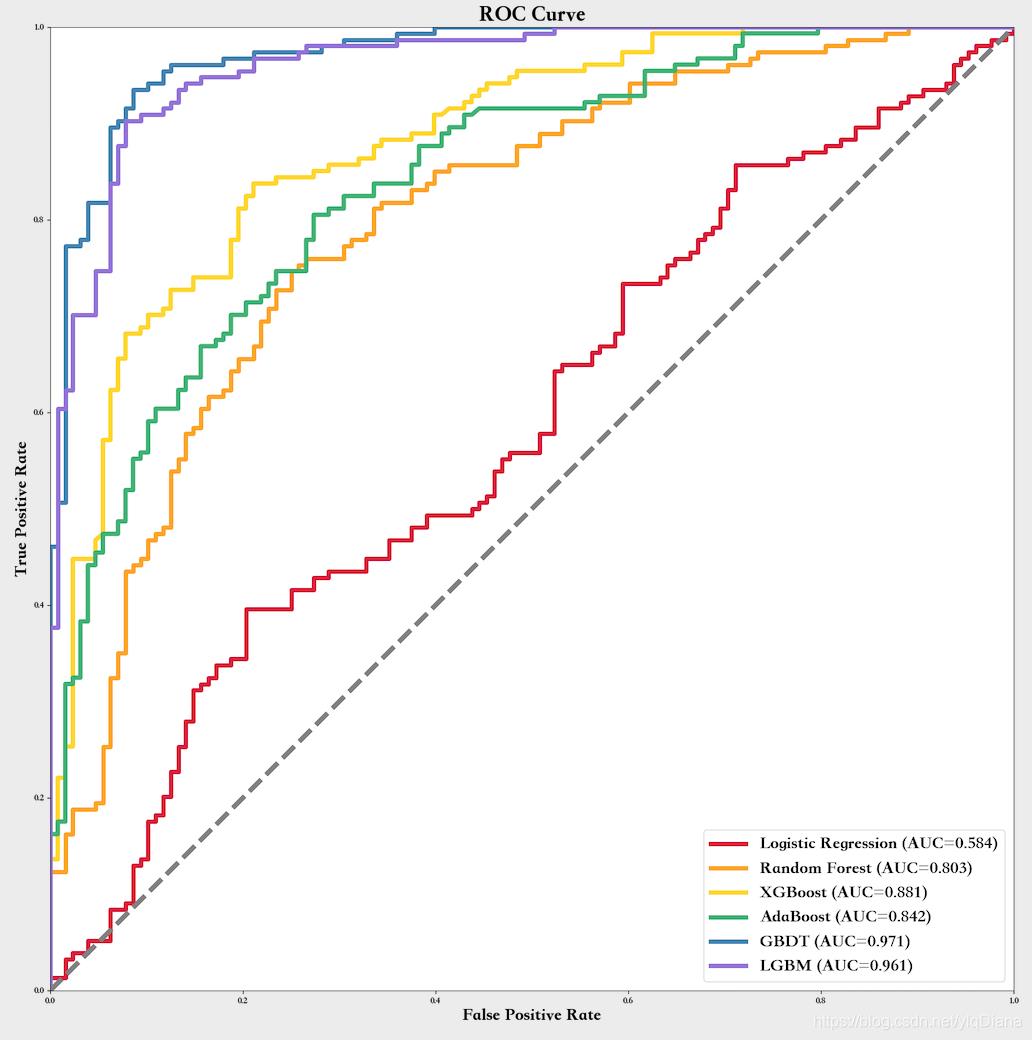
三.调用格式与方法
调用方法时,需要把模型本身(如clf_xx)、模型名字(如GBDT)和对应颜色(如crimson)按照顺序、以列表形式传入函数作为参数。
names = ['Logistic Regression',
'Random Forest',
'XGBoost',
'AdaBoost',
'GBDT',
'LGBM']
sampling_methods = [clf_lr,
clf_rf,
clf_xgb,
clf_adb,
clf_gbdt,
clf_lgbm
]
colors = ['crimson',
'orange',
'gold',
'mediumseagreen',
'steelblue',
'mediumpurple'
]
#ROC curves
train_roc_graph = multi_models_roc(names, sampling_methods, colors, X_train, y_train, save = True)
train_roc_graph.savefig('ROC_Train_all.png')
四. 详细解释和说明
1.关键函数
(1)plt.figure(figsize=(20, 20), dpi=dpin)
在for循环外绘制图片的大体框架。figsize控制图片大小,dpin控制图片的信息量(其实可以理解为清晰度?documentation的说明是The resolution of the figure in dots-per-inch)
(2)zip()
函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。
(3)roc_curve()
fpr, tpr, thresholds = roc_curve(y_test, y_test_predprob, pos_label=1)
该函数的传入参数为目标特征的真实值y_test和模型的预测值y_test_predprob。需要为pos_label赋值,指明正样本的值。
该函数的返回值 fpr、tpr和thresholds 均为ndarray, 为对应每一个不同的阈值下计算出的不同的真阳性率和假阳性率。这些值,就对应着ROC图中的各个点。
(4)auc()
plt.plot(fpr, tpr, lw=5, label=' (AUC=:.3f)'.format(name, auc(fpr, tpr)),color = colorname)
函数auc(),传入参数为fpr和tpr,返回结果为模型auc值,即曲线下面积值。
以上代码在使用fpr和tpr绘制ROC曲线的同时,也确定了标签(图例)的内容和格式。
2. 参数解释
(1)sampling_methods
是包含多个模型名字的list。所有模型不需要fit过再传入函数,只需要定义好即可。
clf = RandomForestClassifier(n_estimators = 100, max_depth=3, min_samples_split=0.2, random_state=0)
(2)X_test, y_test
X_test 和 y_test 两个参数用于传入函数后计算各个模型的预测值。
y_test_predprob = method.predict_proba(X_test)[:,1]
fpr, tpr, thresholds = roc_curve(y_test, y_test_predprob, pos_label=1)
如果需要绘制的是训练集的ROC曲线,则可以在对应参数位置分别传入X_trian和y_train即可。
(3)names 和 colors
这两个参数均为字符串列表形式。注意,这两个列表的值要和模型参数中的模型顺序一一对应。
如有需要绘制更多的模型,只需要对应增加列表中的值即可。
五.需要注意的小小坑
1.同一张图片的同一种方法只能调用一次!!!
plt.legend(loc='lower right')
plt.legend(fontsize=10)
如果像上图中的我一样,把同一张图片plt的方法legend()调用两次,那么下一个的方法中的参数就会将上一个的参数覆盖!这种情况下,我就发现第一个方法赋值的location完全不起作用……
这个时候就需要将这个函数整合如下图~(其实本来就是应该这么写的,我也不知道为啥我脑子一抽写了两个,可能是R的ggplot给我的美好印象挥之不去吧)
plt.legend(loc='lower right',fontsize=10)
六.答疑和补充
根据小伙伴的评论提问,在这里进行一下解释说明:
1.函数的适用问题
这个函数是适用于所有数据集的,只需要导入数据集后进行训练集和测试集的划分即可。(我在“调用格式与方法”部分调用函数使用的是X_train 和y_train,绘制出的则是不同模型在训练集表现的ROC曲线)
划分训练集和测试集的代码如下(以使用8:2划分训练集测试集为例)
# 8:2划分训练集测试集
X, y = df.drop(target,axis=1), df[target]
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.8, random_state=0)
df:导入的数据集
target:目标特征(y)
train_size:训练集占比80%
random_state: 随机数种子,不同随机数种子划分的训练集和测试集会有不同。
2.完整数据和代码
有很多小伙伴问我要完整的数据集和代码,我在这里做下说明。这个函数是完整的、可以直接使用的,如涉及到具体的数据集,完整的流程是这样的:
(1)导入包
可能涉及到的包的调用代码:
import pandas as pd
import numpy as np
from sklearn.metrics import roc_auc_score,roc_curve,auc
from sklearn import metrics
from sklearn.model_selection import train_test_split
(2)导入数据集
df = pd.read_csv(r'你的数据集所在地址')
(3)划分训练集和测试集
# 以下是我常用的8:2划分训练集测试集,数据量大的话也可以9:1
X, y = df.drop(target,axis=1), df[target]
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.8, random_state=0)
(4)建立模型
接下来就需要建立模型啦~ 需要建多少都没有问题,只需要对应调整调用函数时的names和sampling_methods就可以了。下面以随机森林模型为例
#调用模型包
from sklearn.ensemble import RandomForestClassifier
#建立模型
#可以根据需要调整模型内参数来达到更优的效果
clf_rf = RandomForestClassifier(n_estimators = 100, max_depth=3, min_samples_split=0.2, random_state=0)
clf_rf.fit(X_train, y_train)
在这一步也可以用以下代码来先简要看看模型效果:
yprob_train_rf = clf_rf.predict_proba(X_train)[:,1]
print("RF训练集AUC",roc_auc_score(y_true=y_train, y_score=yprob_train_rf))
yprob_test_rf = clf_rf.predict_proba(X_test)[:,1]
print("RF测试集AUC",roc_auc_score(y_true=y_test, y_score=yprob_test_rf))
test_roc_rf = roc_auc_score(y_true=y_test, y_score=yprob_test_rf)
(5)把第一部分的函数复制粘贴~
(6)根据建立的模型修改第二部分的调用格式
(7)保存ROC图片即可
3.ROC图片的修改和调整
有小伙伴问关于ROC图片的坐标轴刻度的修改问题,在这里简单补充一下:
坐标轴的范围是由xlim和ylim控制的,坐标轴的刻度是由xticks和yticks控制的,需要修改坐标轴刻度大小只需要增加到“xlim”语句后面就可以啦。
plt.xlim([0, 1])
plt.ylim([0, 1])
#增加到如下语句后,注意缩进
#方法一,直接手动设置
plt.xticks([0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1.0])
plt.yticks([0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1.0])
#方法二,间隔相同的可以利用arange函数
plt.xticks(np.arange(0, 1, step=0.1))
plt.yticks(np.arange(0, 1, step=0.1))
以上是关于python 将多个数据图绘制到一张图上的主要内容,如果未能解决你的问题,请参考以下文章
python matplotlib怎么在一张图上画多条曲线?Python处理多个csv文件生成叠加曲线图——综合示例:平滑处理图注图例图题范围缩放