hadoop文件格式和压缩
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hadoop文件格式和压缩相关的知识,希望对你有一定的参考价值。
参考技术A Hadoop中的文件格式大致上分为面向行和面向列两类:面向行:TextFile、SequenceFile、MapFile、Avro Datafile
二进制格式文件大小比文本文件大。
生产环境常用,作为原始表的存储格式,会占用更多磁盘资源,对它的 解析开销一般会比二进制格式高 几十倍以上。
Hadoop API 提供的一种二进制文件,它将数据以<key,value>的形式序列化到文件中。这种二进制文件内部使用Hadoop 的标准的Writable 接口实现序列化和反序列化。它与Hadoop API中的MapFile 是互相兼容的。
MapFile即为排序后的SequeneceFile,它会额外生成一个索引文件提供按键的查找。文件不支持复写操作,不能向已存在的SequenceFile(MapFile)追加存储记录,在执行文件写操作的时候,该文件是不可读取的。
Avro是一种用于支持数据密集型的二进制文件格式。它的文件格式更为紧凑,若要读取大量数据时,Avro能够提供更好的序列化和反序列化性能。并且Avro数据文件天生是带Schema定义的,所以它不需要开发者在API 级别实现自己的Writable对象。最近多个Hadoop 子项目都支持Avro 数据格式,如Pig 、Hive、Flume、Sqoop和Hcatalog。
面向列:Parquet 、RCFile、ORCFile
RCFile是Hive推出的一种专门面向列的数据格式。 它遵循“先按列划分,再垂直划分”的设计理念。当查询过程中,针对它并不关心的列时,它会在IO上跳过这些列。
ORCFile (Optimized Record Columnar File)提供了一种比RCFile更加高效的文件格式。其内部将数据划分为默认大小为250M的Stripe。每个Stripe包括索引、数据和Footer。索引存储每一列的最大最小值,以及列中每一行的位置。
Parquet 是一种支持嵌套结构的列式存储格式。Parquet 的存储模型主要由行组(Row Group)、列块(Column Chuck)、页(Page)组成。
1、行组,Row Group:Parquet 在水平方向上将数据划分为行组,默认行组大小与 HDFS Block 块大小对齐,Parquet 保证一个行组会被一个 Mapper 处理。
2、列块,Column Chunk:行组中每一列保存在一个列块中,一个列块具有相同的数据类型,不同的列块可以使用不同的压缩。
3、页,Page:Parquet 是页存储方式,每一个列块包含多个页,一个页是最小的编码的单位,同一列块的不同页可以使用不同的编码方式。
一般原始表数据使用文本格式存储,其他的都是列式存储。
目前在Hadoop中常用的几种压缩格式:lzo,gzip,snappy,bzip2,主要特性对比如下:
其性能对比如下:
2.1 lzo
hadoop中最流行的压缩格式,压缩/解压速度也比较快,合理的压缩率,支持split。适用于较大文本的处理。
对于lzo压缩,常用的有LzoCodec和lzopCodec,可以对sequenceFile和TextFile进行压缩。对TextFile压缩后,mapred对压缩后的文件默认是不能够进行split操作,需要对该lzo压缩文件进行index操作,生成lzo.index文件,map操作才可以进行split。如果设置LzoCodec,那么就生成.lzo后缀的文件,可以用LzoIndexer 进行支持split的index计算,如果设置LzopCodec,那么生成.lzo_deflate后缀的文件,不支持建立index。
Hadoop 储存格式 和 压缩方式
之前 经常把 Hadoop 储存格式 和 压缩方式弄混,今天系统的看了一下。
储存格式指的是Hdfs 中存储文件的格式,常用的有SequnceFile、RCFile、Parquet和TextFile。
压缩方式用在MR中,有3个地方可以用到:
1)input起点
2)map处理之后
3) reduce处理之后进行存储
首先压缩的优点缺点:
优点:减少存储空间(HDFS),降低网络带宽,减少磁盘IO。
缺点:既然存在优点,那必然存在缺点,那就是CPU啦,压缩和解压肯定要消耗CPU的,如果CPU过高那肯定会导致集群负载过高,从而导致你的计算缓慢,job阻塞,文件读取变慢一系列原因。
常用的压缩方式有4种:
优点:压缩比在四种压缩方式中较高;hadoop本身支持,在应用中处理gzip格式的文件就和直接处理文本一样;有hadoop native库;大部分linux系统都自带gzip命令,使用方便。
缺点:不支持split。
优点:压缩/解压速度也比较快,合理的压缩率;支持split,是hadoop中最流行的压缩格式;支持hadoop native库;需要在linux系统下自行安装lzop命令,使用方便。
缺点:压缩率比gzip要低;hadoop本身不支持,需要安装;lzo虽然支持split,但需要对lzo文件建索引,否则hadoop也是会把lzo文件看成一个普通文件(为了支持split需要建索引,需要指定inputformat为lzo格式)。
优点:压缩速度快;支持hadoop native库。
缺点:不支持split;压缩比低;hadoop本身不支持,需要安装;linux系统下没有对应的命令。
优点:支持split;具有很高的压缩率,比gzip压缩率都高;hadoop本身支持,但不支持native;在linux系统下自带bzip2命令,使用方便。
缺点:压缩/解压速度慢;不支持native。
它们之间的性能比较如下:
压缩比 : bzip2>gzip>lzo = snappy ,bzip2最节省空间
解压速度 :lzo = snappy > gzip > bzip2 , lzo解压速度是最快的
另外Google研发的snappy的压缩格式,嵌入在hadoop中,因为其可靠性和性能的均衡性,非常受到大家欢迎。
所以在Mr的压缩方式优化
map输入:要考虑切片,可以使用lzo/bzip2
map输出: 要考虑速度,可以使用snappy/lzo
reduce输出: 如果是另一个map输入,要考虑切片,如果永久保存要考虑永久保存问题
总结:
1. 不同的场景选择不同的压缩方式,肯定没有一个一劳永逸的方法,如果选择高压缩比,那么对于cpu的性能要求要高,同时压缩、解压时间耗费也多;选择压缩比低的,对于磁盘io、网络io的时间要多,空间占据要多;对于支持分割的,可以实现并行处理。
2. 分片的理解:举个例子,一个未压缩的文件有1GB大小,hdfs默认的block大小是64MB,那么这个文件就会被分为16个block作为mapreduce的输入,每一个单独使用一个map任务。如果这个文件是已经使用gzip压缩的呢,如果分成16个块,每个块做成一个输入,显然是不合适的,因为gzip压缩流的随即读是不可能的。实际上,当mapreduce处理压缩格式的文件的时候它会认识到这是一个gzip的压缩文件,而gzip又不支持随即读,它就会把16个块分给一个map去处理,这里就会有很多非本地处理的map任务,整个过程耗费的时间就会相当长。
lzo压缩格式也会是同样的问题,但是通过使用hadoop lzo库的索引工具以后,lzo就可以支持splittable。bzip2也是支持splittable的。
首先Hadoop中的文件格式大致上分为面向行和面向列两类:
(1). 行式存储:一条数据保存为一行,读取一行中的任何值都需要把整行数据都读取出来(如:SequenceFile, MapFile, Avro Datafile),这种方式在磁盘读取的开销比较大,这无法避免。
(2). 列式存储:整个文件被切割为若干列数据,每一列中数据保存在一起(如:Parquet, RCFile, ORCFile, CarbonData , IndexR)。这种方式会占用更多的内存空间,需要将行数据缓存起来。
常用的储存格式:
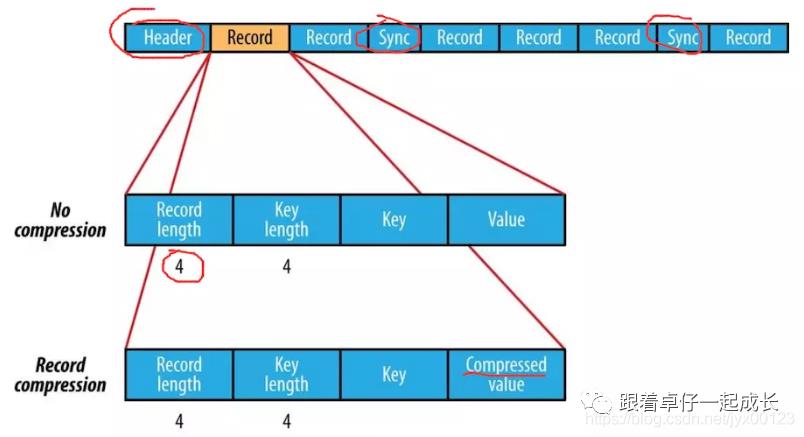
(1).SequenceFile 是key-value 格式进行存储(顺序文件格式,可进行切割),最终形成的是一个二进制文件, 需用hadoop提供的api进行写入存储。(hive:key为空,使用value 存放实际的值)。
使用SqunceFile保存后文件都要比保存之前要大一些。由于SequnceFile文件头中定义了其元数据,元数据的内容根据压缩方式在决定;压缩都是选取block 级别进行的,每一个block都包含key的长度和value的长度,另外每4K字节会有一个sync-marker的标记。
文件结构如下:
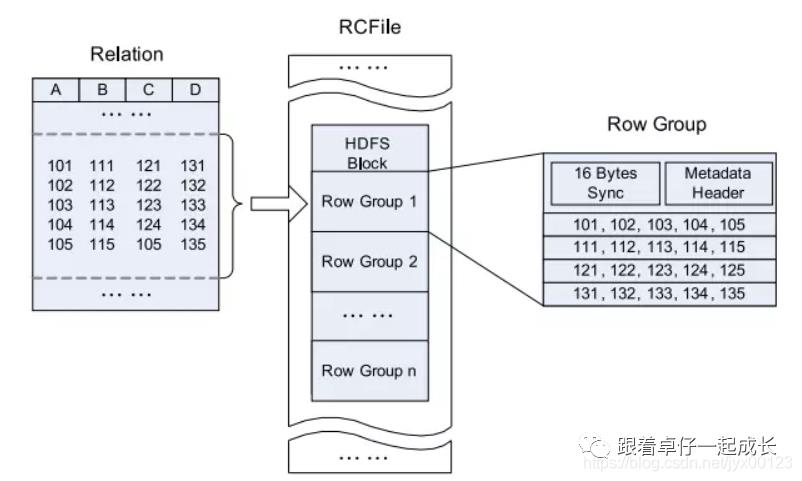
(2). RCFile 是Hive推出的一种专门面向列的数据格式。它遵循“先按列划分,再垂直划分”的设计理念。这种存储方式会保存每个列的每个字段的长度,连续储存在头部元数据块中,而且每隔一定块大小重写一次头部的元数据块。
由于HDFS Block 的头部并没有定义每个列从哪个row group起始到哪个row group结束。所以在读取所有列的情况下,RCFile的性能反而没有SequenceFile高;而且头部对字段长度使用了Run Length Encoding进行压缩,所以RCFile 比SequenceFile又小一些。
(3). ORCFile 提供了一种比RCFile更加高效的文件格式。其内部将数据划分为默认大小为250M的Stripe。每个Stripe包括索引、数据和Footer。索引存储每一列的最大最小值,以及列中每一行的位置。
现在应该是最常用的储存格式。
(4). Parquet 一种通用的面向列的存储格式。特别擅长处理深度嵌套的数据。
Parquet在2015年称为 Apache 顶级项目,后来被 Spark 项目吸收,作为 Spark 的默认数据源,在不指定读取和存储格式时,默认读写 Parquet 格式的文件。
列式存储的数据源一行一行来的,那Parquet是如何保存文件的呢?
首先在内存中缓存一些数据,等缓存到一定量后,将各个列的数据放在一起打包,这样各个包就可以按一定顺序写到一个文件中。这也就是列式存储的精髓:按列缓存打包。详细来讲,Parquet 在每一列内分成一个个的数据包,这个数据包就叫 Page,在Page 的开头存储元数据PageHeader,然后才是数据。查询时,可通过PageHearder来进行过滤。
更进一步来说,Parquet会先将多个 Page 放在一起存储,称为Column Chunk,作为每一列的组成单元,每个 Column Chunk都有其对应的ColumnChunk Metadata,在不同的Column Chunk内记录数据中不同的属性;我们将多个Column Chunk称为Row Group,同样,不同的Row Group也有各自对应的Row Group Metadata,最终被放在File Metadata中。
Page 的分割标准可以按数据点数(如每1000行数据打成一个 Page),也可以按空间占用(如每列的数据攒到8KB合成一个 Page)。
各个引擎适合的存储格式:
Hive适配最好的是RCfile文件格式,
spark SQL是Parquet,
Impala适配最好的是Parquet。
以上是关于hadoop文件格式和压缩的主要内容,如果未能解决你的问题,请参考以下文章