python高并发怎么解决
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python高并发怎么解决相关的知识,希望对你有一定的参考价值。
参考技术A某个时间段内,数据涌来,这就是并发。如果数据量很大,就是高并发
高并发的解决方法:
1、队列、缓冲区
假设只有一个窗口,陆续涌入食堂的人,排队打菜是比较好的方式
所以,排队(队列)是一种天然解决并发的办法
排队就是把人排成 队列,先进先出,解决了资源使用的问题
排成的队列,其实就是一个缓冲地带,就是 缓冲区
假设女生优先,每次都从这个队伍中优先选出女生出来先打饭,这就是 优先队列
例如queue模块的类Queue、LifoQueue、PriorityQueue(小顶堆实现)
2、争抢
只开一个窗口,有可能没有秩序,也就是谁挤进去就给谁打饭
挤到窗口的人占据窗口,直到打到饭菜离开
其他人继续争抢,会有一个人占据着窗口,可以视为锁定窗口,窗口就不能为其他人提供服务了。
这是一种锁机制
谁抢到资源就上锁,排他性的锁,其他人只能等候
争抢也是一种高并发解决方案,但是,这样可能不好,因为有可能有人很长时间抢不到
3、预处理
如果排长队的原因,是由于每个人打菜等候时间长,因为要吃的菜没有,需要现做,没打着饭不走开,锁定着窗口
食堂可以提前统计大多数人最爱吃的菜品,将最爱吃的80%的热门菜,提前做好,保证供应,20%的冷门菜,现做
这样大多数人,就算锁定窗口,也很快打到饭菜走了,快速释放窗口
一种提前加载用户需要的数据的思路,预处理 思想,缓存常用
更多Python知识,请关注:Python自学网!!
怎么理解分布式高并发多线程?(含面试题和答案解析)
看到分布式、高并发、多线程这三个词的时候,很多人是不是都认为分布式=高并发=多线程?当面试官问到高并发系统可以采用哪些手段来解决,或者被问到分布式系统如何解决一致性的问题,是不是一脸懵逼?
确实,在一开始接触的时候,不少人都会分布式、高并发、多线程将三者混淆,误以为所谓的分布式高并发的系统就是能同时供海量用户访问,而采用多线程手段不就是可以提供系统的并发能力吗?实际上,他们三个总是相伴而生,但侧重点又有不同。

接下来我就看看分布式、高并发、多线程这三者之间到底有什么区别?
什么是分布式?
分布式更多的一个概念,是为了解决单个物理服务器容量和性能瓶颈问题而采用的优化手段。该领域需要解决的问题极多,在不同的技术层面上,又包括:分布式文件系统、分布式缓存、分布式数据库、分布式计算等,一些名词如Hadoop、zookeeper、MQ等都跟分布式有关。从理念上讲,分布式的实现有两种形式:
水平扩展:当一台机器扛不住流量时,就通过添加机器的方式,将流量平分到所有服务器上,所有机器都可以提供相当的服务;
垂直拆分:前端有多种查询需求时,一台机器扛不住,可以将不同的需求分发到不同的机器上,比如A机器处理余票查询的请求,B机器处理支付的请求。
什么是高并发?
相对于分布式来讲,高并发在解决的问题上会集中一些,其反应的是同时有多少量:比如在线直播服务,同时有上万人观看。
高并发可以通过分布式技术去解决,将并发流量分到不同的物理服务器上。但除此之外,还可以有很多其他优化手段:比如使用缓存系统,将所有的,静态内容放到CDN等;还可以使用多线程技术将一台服务器的服务能力最大化。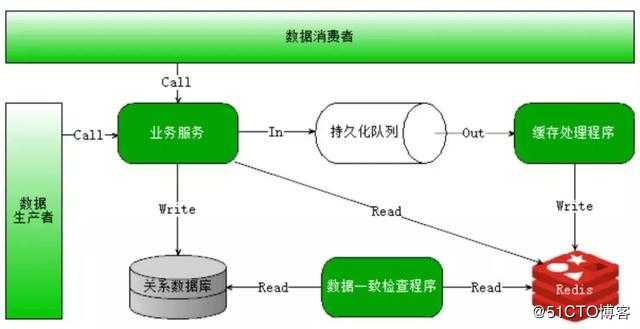
什么是多线程?
多线程是指从软件或者硬件上实现多个线程并发执行的技术,它更多的是解决CPU调度多个进程的问题,从而让这些进程看上去是同时执行(实际是交替运行的)。
这几个概念中,多线程解决的问题是最明确的,手段也是比较单一的,基本上遇到的最大问题就是线程安全。在JAVA语言中,需要对JVM内存模型、指令重排等深入了解,才能写出一份高质量的多线程代码。
总结一下:
分布式是从物理资源的角度去将不同的机器组成一个整体对外服务,技术范围非常广且难度非常大,有了这个基础,高并发、高吞吐等系统很容易构建;
高并发是从业务角度去描述系统的能力,实现高并发的手段可以采用分布式,也可以采用诸如缓存、CDN等,当然也包括多线程;
多线程则聚焦于如何使用编程语言将CPU调度能力最大化。
下面给大家分享一些面试官常问的分布式、高并发、多线程的面试题
1、分布式系统怎么做服务治理
针对互联网业务的特点,eg 突发的流量高峰、网络延时、机房故障等,重点针对大规模跨机房的海量服务进行运行态治理,保障线上服务的高SLA,满足用户的体验,常用的策略包括限流降级、服务嵌入迁出、服务动态路由和灰度发布等
2、对分布式事务的理解
本质上来说,分布式事务就是为了保证不同数据库的数据一致性。
事务的ACID特性 原子性 一致性 隔离性 持久性
消息事务+最终一致性
CC提供了一个编程框架,将整个业务逻辑分为三块:Try、Confirm和Cancel三个操作。以在线下单为例,Try阶段会去扣库存,Confirm阶段则是去更新订单状态,如果更新订单失败,则进入Cancel阶段,会去恢复库存。总之,TCC就是通过代码人为实现了两阶段提交,不同的业务场景所写的代码都不一样,复杂度也不一样,因此,这种模式并不能很好地被复用。
3、如何实现负载均衡,有哪些算法可以实现?
经常会用到以下四种算法:随机(random)、轮训(round-robin)、一致哈希(consistent-hash)和主备(master-slave)。
4、分布式集群下如何做到唯一序列号
Redis生成ID 这主要依赖于Redis是单线程的,所以也可以用生成全局唯一的ID。可以用Redis的原子操作 INCR和INCRBY来实现。
5. 什么是进程
进程是指运行中的应用程序,每个进程都有自己独立的地址空间(内存空间)。
比如用户点击桌面的IE浏览器,就启动了一个进程,操作系统就会为该进程分配独立的地址空间。当用户再次点击左边的IE浏览器,又启动了一个进程,操作系统将为新的进程分配新的独立的地址空间。目前操作系统都支持多进程。
6. 什么是线程
进程是表示自愿分配的基本单位。而线程则是进程中执行运算的最小单位,即执行处理机调度的基本单位。通俗来讲:一个程序有一个进程,而一个进程可以有多个线程。
7. 线程和进程有什么区别
线程是进程的子集,一个进程可以有很多线程,每条线程并行执行不同的任务。不同的进程使用不同的内存空间,而所有的线程共享一片相同的内存空间。
8. 多线程的几种实现方式
(1) 继承Thread类创建线程
Thread类本质上是实现了Runnable接口的一个实例,代表一个线程的实例。启动线程的唯一方法就是通过Thread类的start()实例方法。start()方法将启动一个新线程,并执行run()方法。这种方式实现多线程比较简单,通过自己的类直接继承Thread,并重写run()方法,就可以启动新线程并执行自己定义的run()方法。
(2) 实现Runnable接口创建线程
如果自己的类已经继承了两一个类,就无法再继承Thread,因此可以实现一个Runnable接口
(3) 实现Callable接口通过FutureTask包装器来创建Thread线程
(4) 使用ExecutorService、Callable、Future实现有返回结果的线程
ExecutorService、Callable、Future三个接口实际上都是属于Executor框架。返回结果的线程是在JDK1.5中引入的新特征,有了这种特征就不需要再为了得到返回值而大费周折了。
可返回值的任务必须实现Callable接口;无返回值的任务必须实现Runnabel接口。
执行Callable任务后,可以获取一个Future对象,在该对象上调用get()方法就可以获取到Callable任务返回的Object了。(get()方法是阻塞的,线程无返回结果,该方法就一直等待)
9. 多线程中忙循环是什么
忙循环就是程序员用循环让一个线程等待,不像传统方法wait()、sleep()或者yied()它们都放弃了CPU控制,而忙循环不会放弃CPU,它就是在运行一个空循环。这么做的目的是为了保留CPU缓存,在多核系统中,一个等待线程醒来的时候可能会在另一个内核运行,这样会重建缓存。为了避免重建缓存和减少等待重建的时间就可以使用它了。
10. 什么是java内存模型
java内存模型定义了java虚拟机在计算机内存中的工作方式。JMM决定了一个线程对共享变量的写入何时对另一个线程可见。从抽象的角度来看,JMM定义了线程和主内存之间的抽象关系:线程之间的共享变量存储在主内存中,每一个线程都有一个私有的本地内存,本地内存中存储了该线程以读/写共享变量的副本。
11. 为什么要用线程池?
线程池提供了一种限制和管理资源(包括执行一个任务)。 每个线程池还维护一些基本统计信息,例如已完成任务的数量。
这里借用《Java并发编程的艺术》提到的来说一下使用线程池的好处:
降低资源消耗。 通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
提高响应速度。 当任务到达时,任务可以不需要的等到线程创建就能立即执行。
提高线程的可管理性。 线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
12、什么是乐观锁和悲观锁
1)乐观锁:就像它的名字一样,对于并发间操作产生的线程安全问题持乐观状态,乐观锁认为竞争不总是会发生,因此它不需要持有锁,将比较-替换这两个动作作为一个原子操作尝试去修改内存中的变量,如果失败则表示发生冲突,那么就应该有相应的重试逻辑。
2)悲观锁:还是像它的名字一样,对于并发间操作产生的线程安全问题持悲观状态,悲观锁认为竞争总是会发生,因此每次对某资源进行操作时,都会持有一个独占的锁,就像synchronized,不管三七二十一,直接上了锁就操作资源了。
13、高并发、任务执行时间短的业务怎样使用线程池?并发不高、任务执行时间长的业务怎样使用线程池?并发高、业务执行时间长的业务怎样使用线程池?
1)高并发、任务执行时间短的业务,线程池线程数可以设置为CPU核数+1,减少线程上下文的切换
2)并发不高、任务执行时间长的业务要区分开看:
a)假如是业务时间长集中在IO操作上,也就是IO密集型的任务,因为IO操作并不占用CPU,所以不要让所有的CPU闲下来,可以加大线程池中的线程数目,让CPU处理更多的业务
b)假如是业务时间长集中在计算操作上,也就是计算密集型任务,这个就没办法了,和(1)一样吧,线程池中的线程数设置得少一些,减少线程上下文的切换
c)并发高、业务执行时间长,解决这种类型任务的关键不在于线程池而在于整体架构的设计,看看这些业务里面某些数据是否能做缓存是第一步,增加服务器是第二步,至于线程池的设置,设置参考其他有关线程池的文章。最后,业务执行时间长的问题,也可能需要分析一下,看看能不能使用中间件对任务进行拆分和解耦。
欢迎大家一起交流,喜欢文章记得点个赞,感谢支持!
以上是关于python高并发怎么解决的主要内容,如果未能解决你的问题,请参考以下文章