TI C6000 数据存储处理与性能优化
Posted ncdxlxk
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TI C6000 数据存储处理与性能优化相关的知识,希望对你有一定的参考价值。

存储器之于CPU好比仓库之于车间。车间加工过程中的原材料、半成品、成品等均需入出仓库,生产效率再快,如果仓库周转不善,也必然造成生产阻塞。如同仓库需要合理地规划管理一般,数据存储也需要恰当的处理技巧来提升CPU的运算性能。
本文基于TI C6000系列DSP,介绍了与运算性能优化有关的存储器知识。针对具体的数据存储问题,给出相应的代码优化策略,并将容易混淆的概念集中讨论。
名词说明
-
EMIF: External Memory Interface
-
PMC: Program Memory Controller
-
DMC: Data Memory Controller
-
SPC: Section Program Counter
存储体冲突Vs存储别名模糊[1]
1. 存储体(bank)冲突
C6000系列各DSP的片内存储器结构有所不同,其中大多数采用交叉存取式存储体结构,如图1所示,方框中数字表示字节地址。因为每个bank都是一个单口存储器,所以每个周期对每个bank只能有一次访问。例如两个short型数据a和b,a存放在地址1-2中,b存放在地址8-9中,则程序中不能安排a和b并行存/取,否则会导致存储器存取延迟,使流水线暂停一个周期,在暂停周期中进行第二次读/写存储器,这就是存储体冲突现象。

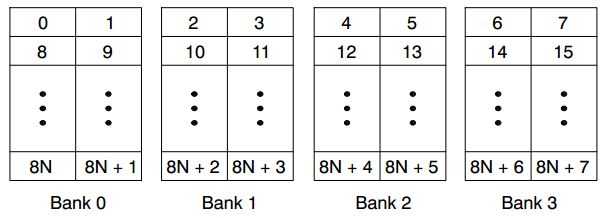
图1 4bank交叉存取式存储器
以16bit short型点积计算为例:
int dotp(short a[], short b[]);
一个高效的软件流水核如下。在最后两条指令中,用LDW“字加载”命令,一个周期中同时加载a[0]、a[1]、b[0]、b[1]。

要使软件流水不被阻塞,则需保证数组a和b的并行加载不发生存储体冲突。
-
冲突例子:a首地址=0;b首地址=8N
-
不冲突例子:a首地址=0;b首地址=8N+4
但是,完全控制数组和其它对象在存储器空间的起始位置并不总是可以做到,尤其是当一个指针作为参数传递给函数时,调用这个函数的指针参数可能指向不同的存储器位置。
如果不能知道数组a和b在存储体中的排列信息,则只能肯定a[0-1]和a[2-3]不会发生存储体冲突,同理于b[0-1]和b[2-3]。因此,可以通过循环展开的方式,安排a[0-1]和a[2-3]、b[0-1]和b[2-3]进行同时存取,避免了可能的存储体冲突。循环展开后的软件流水核如下:

另外,在线性汇编中,可以通过“.mptr”伪指令,给编译器提供数据的存储相关信息,让编译器自动分析是否会产生存储体冲突并调整指令编排。
2. 存储别名模糊(alias)
当多个不同的变量名都指向相同的存储区域,这时就发生别名模糊,也就是说,对这些变量进行操作的指令可能存在存储相关性。指令间的相关性限制了指令的编排,包括软件流水编排。
汇编优化器假定所有的存储器引用,都是别名化的(aliased),它把控制权交给用户,由用户提供存储是否别名的信息。编程者可通过一个编译选项/“restrict”关键词/两条线性汇编伪指令来提供存储别名的信息。
-
-mt编译选项:表示代码中没有存储别名现象。要仔细判断是否能使用-mt,如果代码使用了别名技术而又设置了-mt选项,可能会出现意想不到的结果。
-
restrict关键词:在C编程中,对数组或指针变量用restrict进行声明,提示编译器该变量指向的存储区域不会与其它变量指向的存储区域发生重叠。
-
.mdep伪指令:用于明确声明存储器相关。
-
.no_mdep伪指令:告诉汇编优化器函数体中没有存储器相关性出现。
*不要把“存储别名模糊(存储器相关)”和“存储体冲突”两个概念混淆,它们有着不同的含义和影响。别名模糊影响程序的正确性(当然也可能影响性能),存储体冲突影响程序的性能。存储器相关对于指令编排影响大于存储体冲突。
存储器模式Vs数据终结方式[1,2]
1. 存储器模式
C6000编译器支持两种存储器模式:小存储器模式和大存储器模式。
-
小存储器模式:.bss段限制在32kB内,CPU可用直接寻址方式访问.bss段中的所有对象而无需改变DP(B14)的值。
-
大存储器模式:不限制.bss段大小,但CPU只能通过寄存器间接寻址访问.bss中的数据,也即需要先将对象地址读入寄存器中,这带来额外的操作。
当全局/静态变量(存放于.bss段)超过32kB,而又希望使用小存储器模式获得快的访问速度,有两种解决办法:
-
对于大的数组定义,使用far关键字,如此数据不占用.bss段空间,而放入.far段。
-
使用-ml/-ml0选项,编译器自动对集合数据类型(如结构体和数组)使用far存取。
2. 数据终结方式
指的是多字节数据内部高低有效位的存放顺序。C6000支持两种终结方式:小端终结方式和大端终结方式。
-
小端终结(Little-Endian):数据高有效位字节存放在地址高位字节(高位高地址)。
-
大端终结(Big-Endian):数据高有效位字节存放在地址低位字节(高位低地址)。
内存边界对齐[1,3]
C67X DSP支持单次存/取16bit(半字)、32bit(字)、64bit(双字)数据,但前提是数据的存放分别满足半字对齐、字对齐和双字对齐。目前C64X支持在非对齐情况下单次存/取32bit和64bit宽度的数据。
所谓半字对齐指的是数据地址的最低1位为0;字对齐指的是数据地址的最低2位为0;双字对齐指的是数据地址的最低3位为0。
对不支持非对齐单次存/取的器件来说,如果让CPU用多字节存/取指令一次操作非对齐的数据,将会产生额外操作,有些处理器甚至无法处理而产生错误!下图给出了一个处理示例,从图中可见,原本单次可以完成的操作由于数据未能对齐而花费了5次操作。
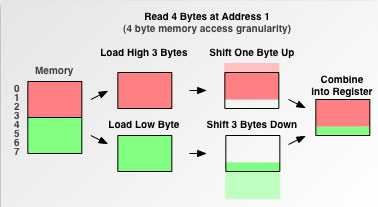
图2 对非对齐数据进行多字节访问
在C64X中,数组均默认安排8字节(双字)对齐;在C62X和C67X中,数组按4字节/8字节对齐。
结构体的对齐方式由其最大数据类型成员决定,结构体占用的存储空间总是最大成员类型大小的倍数(注意并不是简单地乘以成员个数)。如下两个结构体A和B,它们所占的存储空间分别是8、12。
struct A { short x; short y; int z; }; struct B { short x; int y; short z; };
数据集边界对齐并不意味着它里面的每一个元素的地址都为对齐长度的倍数,而是保证数据集的起始地址和<结束地址+1>为对齐长度的倍数。
对齐的存储器访问
在C/C++代码中,有三个pragma预编译语句可以用来指示编译器将具体的数据按指定的方式进行对齐存储。
-
DATA_ALIGN:将数据进行2的整数次幂对齐
-
DATA_MEM_BANK:将数据对齐到指定的bank
-
STRUCT_ALIGN(C特有):用于指定结构体、联合体进行2的整数次幂对齐
使用_nassert()内联函数能够指示编译器某一数据的内存对齐状态。如
_nassert( ((int)sum & 0x3) == 0);
告诉编译器sum为字边界对齐,有了这个信息,编译器就可以放心地安排SIMD(单指令多数据)指令对数据进行操作,但_nassert本身不产生任何操作。
可以使用_amemXX()和_amemXX_const()内联函数对对齐的字和半字进行访问。一般这类内存访问可以与_hi()、_lo()和_itod()等数据解包和打包内联函数联合使用。
非对齐的存储器访问
C64X支持非对齐的字和双字访问,其对边界对齐和非边界对齐数据访问的比较如下表所示:
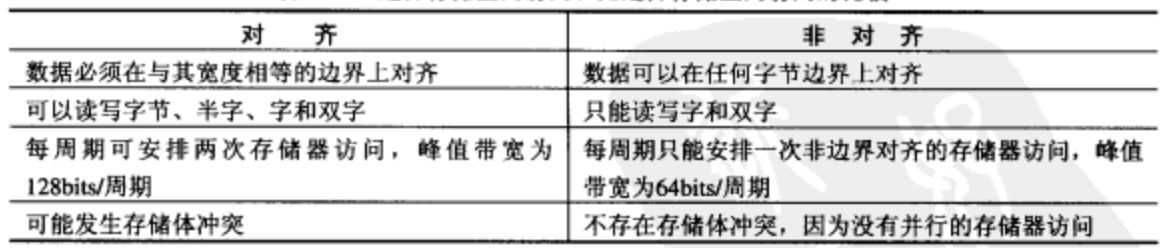
从上表可以看出,C64X在每时钟周期只能进行一次非边界对齐的存储器访问,因此,只要可能应尽量使用边界对齐的存储器访问方式。
在C/C++代码中,可以使用_memXX()和_memXX_const()内联函数对非对齐的字和半字进行访问。一般这类内存访问可以与_hi()、_lo()和_itod()等数据解包和打包内联函数联合使用,下面是一个使用示例:

C6000 Cache(缓存)[4,5]
为什么需要Cache?
大容量的存储器(如DRAM)访问速度受到限制,一般比CPU时钟速度慢很多;小容量的存储器(如SRAM)能提供快速的访问速度。因此很多高性能的处理器都提供分层的存储访问架构。
如图3所示,左右分别是平坦式存储器架构和2层cache的多层存储架构。在左边的架构中,即使CPU能运行在600MHz,但由于片内/片外存储器只能运行在300MHz/100MHz,CPU在访问存储时需插入等待周期。
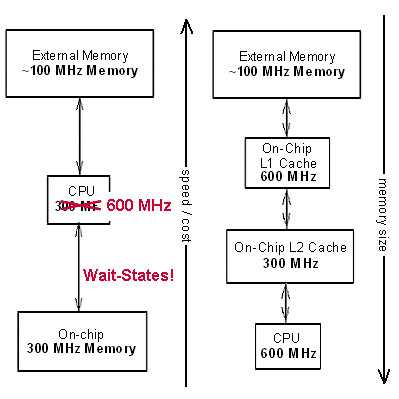
图3 平坦式和层级式存储器架构
Cache部分工作状态说明
-
Cache hit(缓存命中):对于已经缓存的程序/数据,访问将引起缓存命中,缓存中的指令/数据立即送入CPU而无需等待。
-
Cache miss(缓存缺失):发生缺失时,首先通过EMIF读入需要的指令/数据,指令/数据在送入CPU的同时被存入Cache,读入程序/数据的过程CPU被挂起。
-
Cache flush(缓存命中):清空Cache已经缓存的数据。
-
Cache freeze(缓存冻结):Cache内容不再改变,发生缺失时,从EMIF中读入的指令包不会同时存入Cache。
-
Cache bypass(缓存旁路):Cache内容不再改变,任何程序/数据都将从缓存外存储器访问。
C6000的存储架构
C6000系列DSP在片内RAM和CPU之间提供两层Cache L1和L2,每层Cache又分为独立的程序Cache和数据Cache。其中L1是固定的,L2可以被重映射为普通片内RAM。
对程序/数据进行访问时,CPU首先到L1 Cache中寻找,命中则直接访问,如果产生缺失,则继续在L2Cache中寻找,如果还未命中,则到片内RAM或片外RAM中寻址数据。
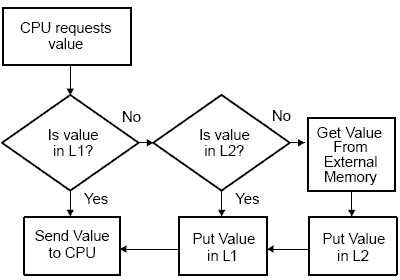
图4 C6000 CPU的程序/数据访问流程
访问定位的规律
由图4可知,要保证CPU的存储访问效率,只有在CPU在大部分的访问都是只针对最靠近它的存储区时才有效。幸运的是,根据访问定位的规律,这一条可以保证。访问的定位规律表明程序在一个相对小的时间窗口对仅需要一个相对较小size的数据和代码。数据定位的两条规律:
-
空间关联性:当一个数据被访问时,它临近的数据又很大可能会被后续的存储访问。
-
时间关联性:一个存储区被访问时,在下一个临近的时间点还会被访问。
优化cache性能
从访问定位规律出发,可总结出优化cache性能的一些基本准则:
-
让函数尽可能充分的对数据处理以提高数据的重用。
-
组织数据和代码以提高cache命中率。
-
合理的空间划分来平衡程序cache和数据cache。
-
组合那些对相同数据进行处理的函数在一个存储区域。
段[1,6]
目标文件(.obj)的最小单位称为段,它是占据一个连续空间的代码块或者数据块。连接器的功能之一就是把段重定位到目标系统的存储器映像图中。所有段都可以独立重定位,用户可以把任一段置入目标存储器任一指定块内。
一个COFF文件包含三个默认段:.text、.data、.bss。用户还可以创建、命名、连接自己的段,也可以继续在各个段中继续划分子段。
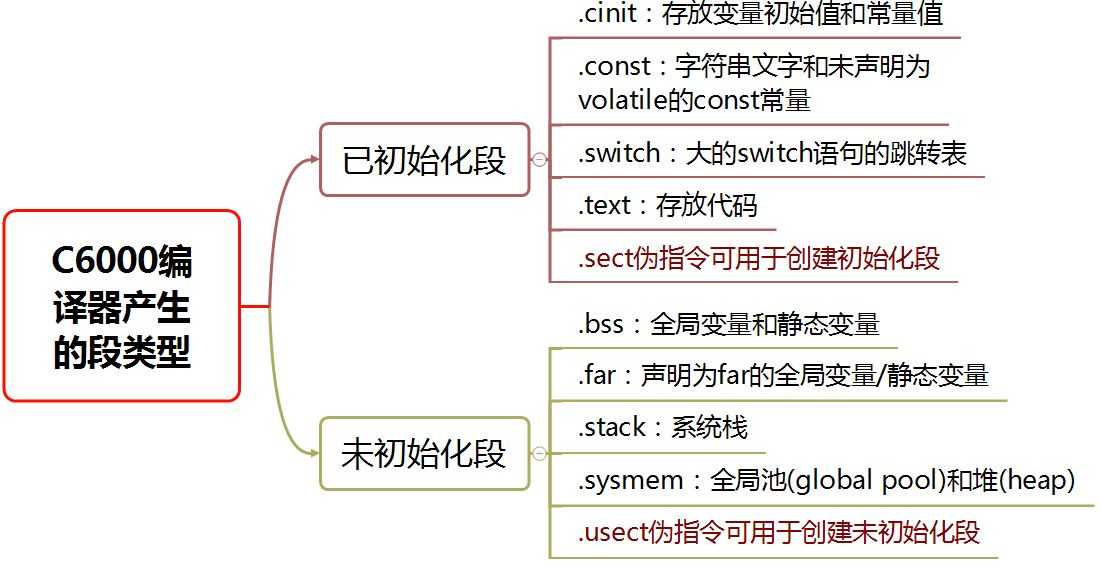
在C/C++代码中,有两个预编译语句可用来将特定的代码或数据分配到指定的段中:
-
CODE_SECTION:为代码分配段。
-
DATA_SECTION:为数据分配段。
栈和堆[1,6]
栈(.stack)和堆(.heap)是为处理器运行时提供支持的两个存储区。
栈是由编译器在需要时分配的,不需要时自动清除的变量存储区。它用于存放局部变量、函数参数等临时数据。
堆用于动态内存分配。堆在内存中位于bss区和栈区之间。一般由程序员分配和释放,若程序员不释放,程序结束时有可能由OS回收。例如C中常用的malloc()函数就是在堆中开辟区间存放数据。
参考文献/资料
【1】田黎育,何佩琨,朱梦宇. TMS320C6000系列DSP编程工具与指南[M].北京:清华大学出版社 2006.
【2】董言治,娄树理,刘松涛. TMS320C6000系列DSP系统结构原理与应用教程[M]. 清华大学出版社, 2014.
【3】Data alignment: Straighten up and fly right - IBM developerworks.
【4】Cache memory – Wikipedia.
【5】如何优化使用C6000系列C64x的Cache--原理,Cache种类和优化策略 - nouth的网易博客
【6】C语言中内存分配 - youoran的CSDN专栏.
·END·
想进一步跟踪本博客动态,欢迎关注我的个人微信订阅号:信号君
信号君:寻求简单之道
技术成长 | 读书笔记 | 认知升级

扫描二维码关注信号君
以上是关于TI C6000 数据存储处理与性能优化的主要内容,如果未能解决你的问题,请参考以下文章