eBay 大数据平台的 HDFS 性能优化实践 Posted 2021-04-14 过往记忆大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了eBay 大数据平台的 HDFS 性能优化实践相关的知识,希望对你有一定的参考价值。
HDFS作为大数据的底层存储系统,其性能处理效率关乎着大量与集群数据相关的计算任务的运行。HDFS的性能效率主要由其内部的核心服务NameNode所决定。此次eBay Hadoop team将分享如何在上百PB数据规模的HDFS集群上,进行HDFS NameNode的性能调优实践。过去一年时间里,他们将NameNode的处理性能提升近
70%
,从
5毫秒+
的RPC处理时间提速到了
1.5毫秒
的速度。
随着公司业务的发展,我们的Hadoop集群规模也在不断地扩大,逐渐碰到越来越多HDFS NameNode方面的扩展性问题以及一些性能瓶颈问题,这些症结的出现影响了我们集群本身的稳定性。因此,在过去近一年的时间里,我们对HDFS NameNode这块做了很多优化改进,包括一些社区已有的patch改进和我们自身内部做的优化等等。本文旨在分享HDFS NameNode的主要优化改进措施,将从减少HDFS繁重API操作影响、异步化RPC response、RPC流量迁移以及NN锁优化处理这四个方面做具体阐述。
在这些优化改进完成后,NameNode的RPC处理时间完成了近
70%
的性能提升(从
5毫秒+
到
1.5毫秒
)。
有过维护大规模HDFS集群经验的同学,一定或多或少了解过现有HDFS的几大比较繁重的操作,如下述几种:
Delete操作
,出问题的状况为Delete大目录或者大Snapshot的情况。Delete大目录时会发生NN长时间的hung住现象,甚至crash NN。另外,我们启用了HDFS Snapshot功能来做用户数据的保护,所以Delete Snapshot操作的性能对我们来说也是需要关注和优化的。
GetBlocks操作
,这个发生在Balancer做大量块数据平衡的时候,会造成周期性的NN RPC队列的尖峰毛刺现象。
ListStatus操作
,当client频繁对大目录调用list操作时,会对NN造成不小的影响。另外,ListStatus操作中的needLocation逻辑会加重list结果的返回开销(比如结果信息的加密计算等等),因为此时block location的信息也被包含在返回结果中了。
GetContentSummary操作
,这个操作对应的一个日常我们经常会使用到的命令,就是fs -count操作。该操作在方法名上容易让人误以为只是简单获取某个目录或文件的summary属性信息,其实它会去递归遍历子目录来计算实际的文件目录大小求和。简单来说,本质上这个call的代价是非常高的,尤其是对大目录进行此操作调用的时候。
以上这些重API操作轻则会影响NameNode的正常RPC处理,重则会crash当前NameNode服务。
上面提到的问题很多在社区都是已知issue了,不过除了目前GetBlocks操作已经有了比较好的解决方案,其它的改进现在看来也只是尽可能减小其造成的影响,还没有很完美的解决办法。
在这里我们先来聊聊eBay内部对于Delete操作和GetBlocks操作做的改进优化。
对于GetBlocks来说,既然这个call只会被Balancer用到,那就不存在这个call会被client调用到的情况。那么我们可以单独将这个请求操作重定向到Standby NameNode上执行,Active NameNode就完全不会受到此操作的影响了。
(相关JIRA HDFS-13183:Standby NameNode process getBlocks request to reduce Active load)
另外对于Delete操作(包括Delete Snapshot),我们改进的方向是降低其操作的影响,从以下两方面入手:
对于Delete目录操作而言,减少其每次delete block的batch大小,减小其操作持有NN锁时间过长的影响。
(相关JIRA HDFS-13831:Make block increment deletion number configurable)
对于Delete Snapshot操作而言,从外部我们自身使用的Snapshot Policy层面进行改进,由原来大目录单个Snapshot变为子目录多Snapshot的管理模式,这样每个Snapshot进行重创建和删除的时候,影响不至于过大。经过此调整优化后,Delete Snapshot的处理时间从 3分多钟 降到了目前的最长不超过 1分钟 的时间。效果图如下(图1为优化前,图2为优化后的时间) :
图2(点击可查看大图)
社区的解决思路
(HDFS-11225:NameNode crashed because deleteSnapshot held FSNamesystem lock too long) 是额外引入类似SkipList的结构来存储多Snapshot间的Diff信息,以减少删除Snapshot的时间。此JIRA的改动在我们目前内部的Hadoop版本中改动较大,出于稳定性的考虑,我们并没有backport这个JIRA的改动。
针对ListStatus的优化,如果不考虑data locality的情况下,我们建议client端通过ignore location配置来忽略掉block location的获取,以此减小server端处理ListStatus操作的压力。
(相关JIRA SPARK-29189:Add an option to ignore block locations when listing file)
经过此部分的优化后,NameNode的RPC队列少了一些毛刺点,但这点优化对我们目前来说还远远不够。
我们的集群数据体量在不断扩张后,集群单日RPC请求数也在飞快上涨,最后经常会出现RPC队列被打满的情况。只要RPC队列被打满,用户的请求响应就会立刻受到影响。
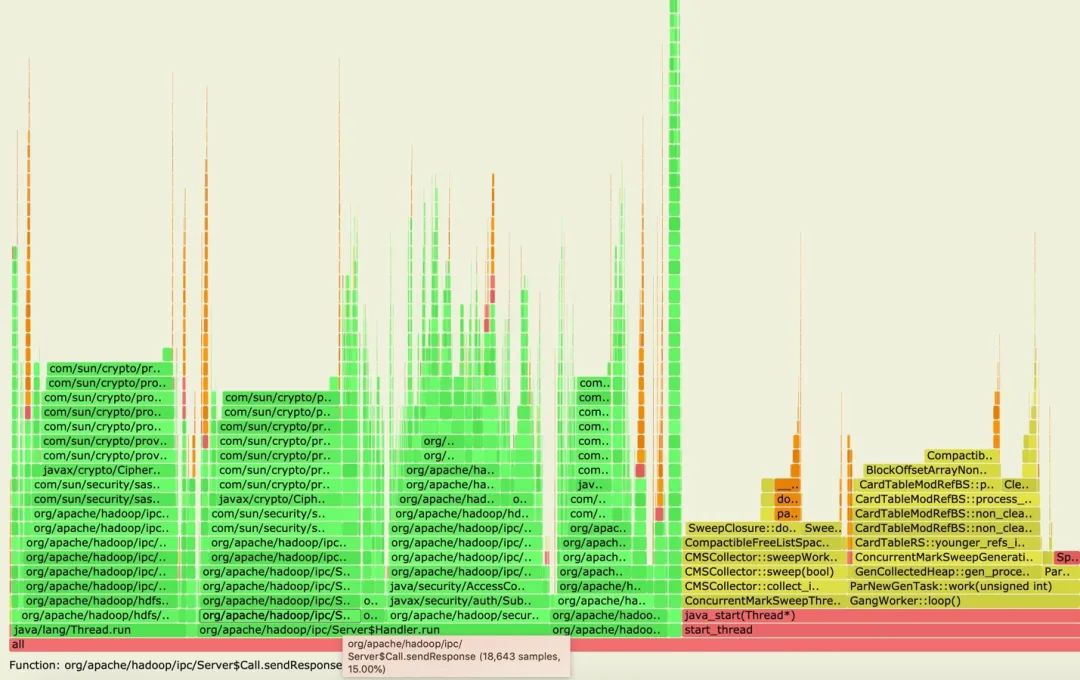
这个时候光看NN log,往往是看不出太多端倪的,后来我们对RPC队列满的那段时间做了多次的profile,终于从火焰图中发现了一些有用的东西。
我们经常性发现NN会花费很多时间执行Server#Call.sendResponse的操作,如下图所示:
下图为FSEditLogAsync类里面调用执行到的Server#Call.sendResponse方法。
首先简单介绍下这个方法是做什么的,Server#Call.sendResponse的逻辑属于Hadoop框架RPC底层的过程方法,指在已经处理完上层应用逻辑(此为HDFS NameNode的API操作处理)后,将结果返回给client的操作阶段。上图结果表明,在我们集群开启有Security模式下,其中涉及到的加解密过程的开销还是挺大的。
本身我们已经开启了async editlog
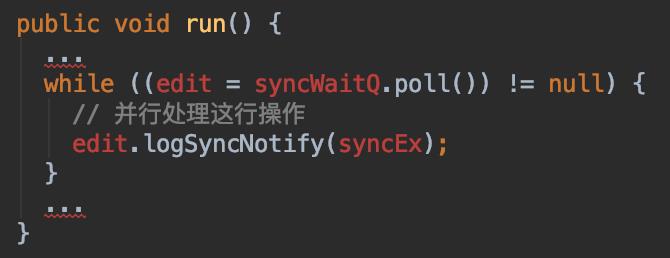
(相关JIRA HDFS-7964,功能开关配置为dfs.namenode.edits.asynclogging) 的功能,来防止logSync操作慢占据了NN的Handler资源,导致Handler不能即时释放资源处理下一个RPC请求。这里async的意思并不是说完全异步化RPC的处理过程,而是将response结果的异步化返回,调用方还是会阻塞等待请求的返回结果的。
但是从上面火焰图的分析结果来看,async editlog相关类FSEditLogAsync还是经常性地卡在了sendResponse阶段。此时FSEditLogAsync的处理本身已经是异步化了,通过分析代码逻辑,这里的问题其实就是FSEditLogAsync内部单线程模式消费内部队列的pending edit call速度过慢,原因是sendResponse执行开销较大。sendResponse是在出队列后同步执行的,pending edit call进队列比出队列速度快。一旦这个pending edit queue满了,就会阻塞外部调用此enqueue方法的逻辑,从而影响操作方法的执行。这部分对应的RPC的操作调用都属于写类型。
我们对上述问题的改进方法也很简单,通过在内部改用多线程外加新增一个response call queue的并行处理方式来加速pending edit queue的消费。
此改进提议我们已经提交到社区了。
(相关JIRA HDFS-15486:Costly sendResponse operation slows down async editlog handling) Async editlog中再次并行处理response可以在一定程度上提升NN的RPC吞吐量,
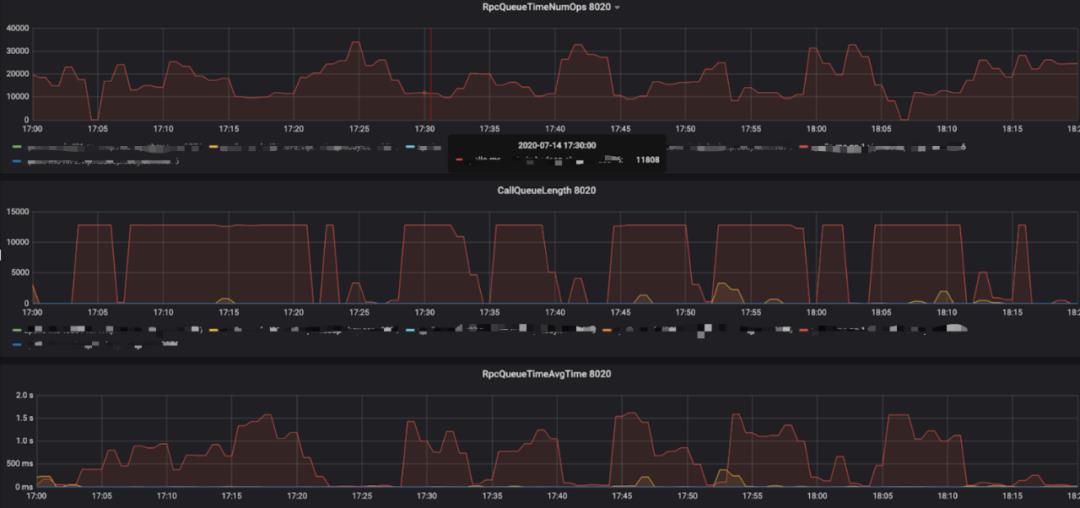
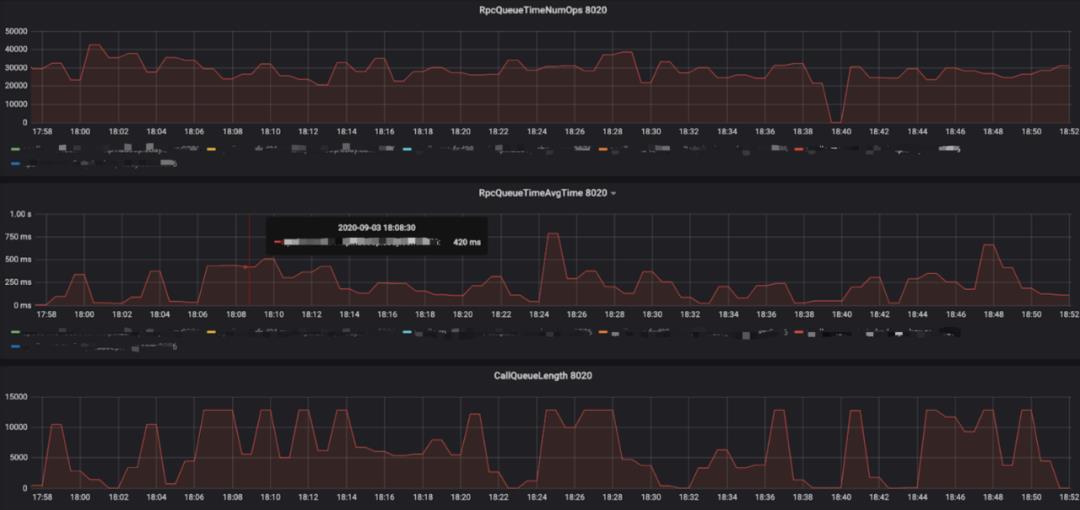
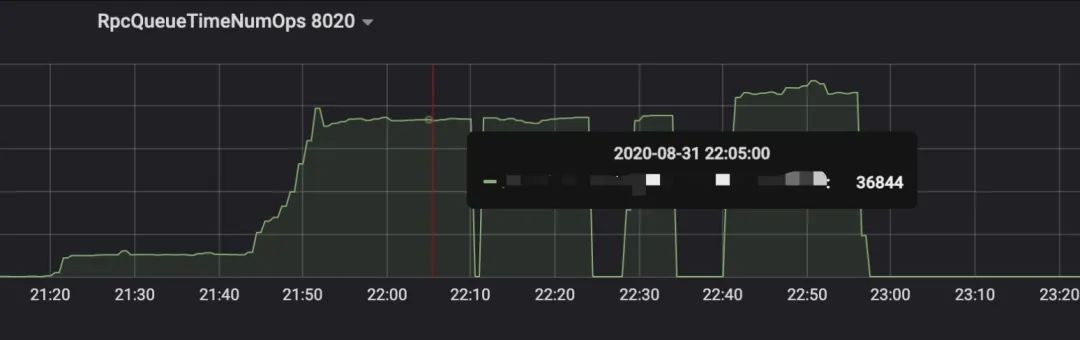
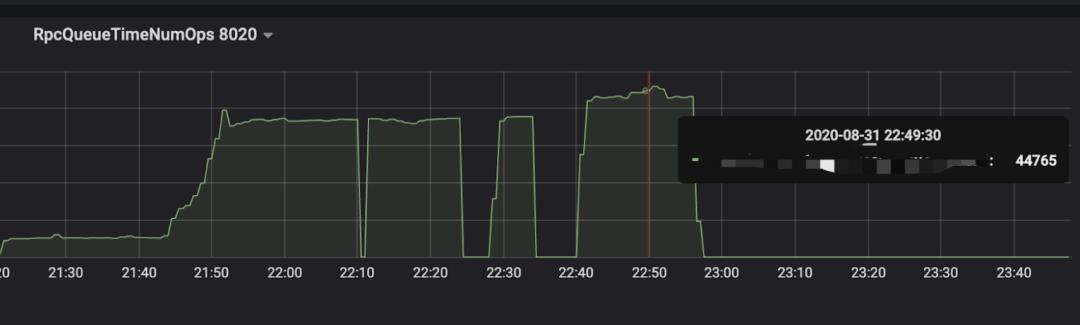
优化效果如下图所示(图5优化前,图6优化后):
图6(点击可查看大图)
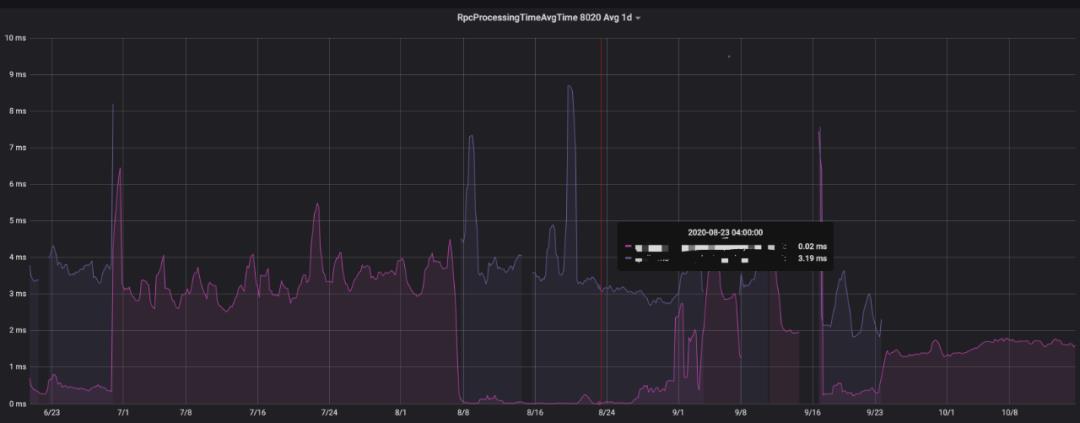
上图中NameNode RPC的queue time(RpcQueueTimeAvgTime, RPC请求等待被处理的耗时)在RPC队列打满的时候,从 1~2秒 降到了 500毫秒 左右,另外queue ops(RpcQueueTimeNumOps, 可简单理解为RPC请求数)指标的峰值从 2~3万 提高到了 3~4万 。
在进行NameNode RPC性能调优的同时,我们另一方面也在考虑怎么给当前大集群拆分一部分RPC流量出去,让其它集群能够分担掉大集群的RPC压力。综合考虑RPC流量拆分的难易程度及其能带来的好处,我们最终决定拆分以下两个目录下的数据:
Yarn application log(后面简称app log)
高流量RPC请求的一个业务目录
1. Yarn application log迁移
首先是Yarn application log,虽然说它只是那些yarn application任务写出的log数据,数据量肯定不会太大,但是其能够产生的一系列写操作是十分惊人的。首先它会创建很多log文件,这个数量由每天集群跑的application总数和这里面的总task数所决定。另外,一个log文件从创建到最后被retain策略删除,会涉及到create,rename,delete三类操作。那么这整个过程中它能够产生的写请求操作的量就非常大了。我们做过一个数据分析,结果显示,每天由app log造成的写请求的操作总数占到集群日均写操作接近
1/3 的比例。
从拆分难度上来说,app log没有涉及到和用户业务逻辑强相关的依赖,迁移起来比较容易。另外迁移app log的一个附加好处是可以减轻NN的heap使用,app log很多都是一些小文件数据,占据了不少NN的heap空间。
而实际做app log拆迁过程中,在security集群模式下,我们配置了一个全新的namespace地址作为新app log的目录,然后遇到了一个关于delegation token方面的问题,如下所示:
后来发现是因为我们没有在client端配置对应namespace地址,导致对应namespace下的delegation token没有传到YARN NodeManager这边。
除了app log的流量迁移,我们的另外一个迁移对象是产生RPC量最大的一个业务目录,该结果基于每日RPC统计分析报告得出。
这部分迁移涉及到了实际的业务数据,而且体量规模在千万文件数,PB级别大小。我们对DistCp做了大幅度的优化后,进行了数据的迁移。此过程在 一文中已经详细讲述,感兴趣的同学可点击链接进行更加细节的了解。
通过此小节描述的两大流量迁移,我们大集群NameNode的压力着实减轻了不少,一个明显的体现是RPC平均处理时间的下降,
如下图所示,从
3毫秒
以上降到了
2毫秒
以下。
图7(点击可查看大图)
说到NN的锁问题,这在HDFS中一直是一个比较难彻底解决的症结。社区在早期有过许多对此的优化方案,但随着HDFS功能的不断完善和成熟,其改造成本越来越高,到最后已经不太好去动NN锁这块的代码逻辑了。
我们对目前NN锁这块的问题只是做了局部的优化处理,还没有涉及到NN锁的大改。这里主要分为三块的改进。
在NN内部,除开FSN lock外,还有一个所谓的目录锁FSDir lock,FSDir lock用来做NN INode信息的更新控制。但上面这两个锁的存在其实存在冗余性,NN可以完全复用FSN lock来做NN元数据更新的一致性控制,而不需要额外去拿FSDir lock的操作。
(相关JIRA HDFS-14731:[FGL] Remove redundant locking on NameNode)
在对于NN局部锁的优化里,我们必须要对每一个更细粒度的锁操作进行监控,才能够知道哪些操作持锁的时间比较长。我们backport了社区关于细粒度锁监控的2个改进:HADOOP-16266
(Add more fine-grained processing time metrics to the RPC layer) 和HDFS-10872
(Add MutableRate metrics for FSNamesystemLock operations) 。
通过上述改进,可以看到针对每个HDFS具体方法操作级别的metric指标,如下图3所示:
然后在这些metric里找到了一个处理时间上起伏比较大的RPC操作:Open操作。
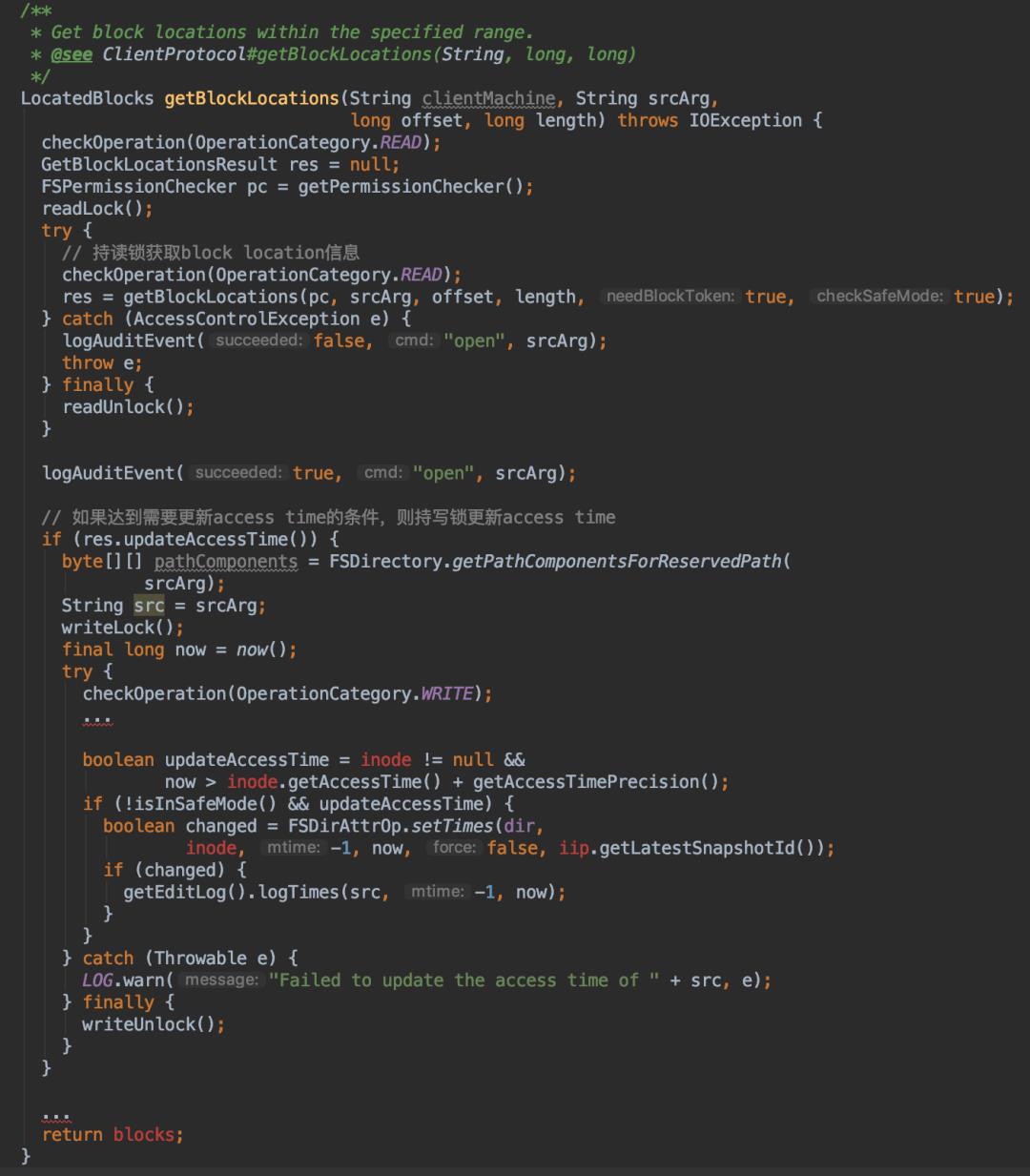
通过代码分析,我们发现Open操作实际上是NN里面的getBlockLocarions操作,作为一个读类型的操作。但其实里面有一段更新文件access time的逻辑是需要持写锁的,代码如下所示:
这意味着当集群存在大量文件读的情况下时,可能会触发大量的setTimes写操作。
在是否需要更新access time(简称atime)的条件里,有以下一段逻辑:
从这里我们可以看到,在atime的更新上,为了避免过于频繁的路径访问造成的access time的反复更新,NN设有额外atime更新的精度控制参数dfs.namenode.accesstime.precision,默认值是
1小时 ,意为至少在超过上次atime时间后1小时,才能再次允许atime值的更新。
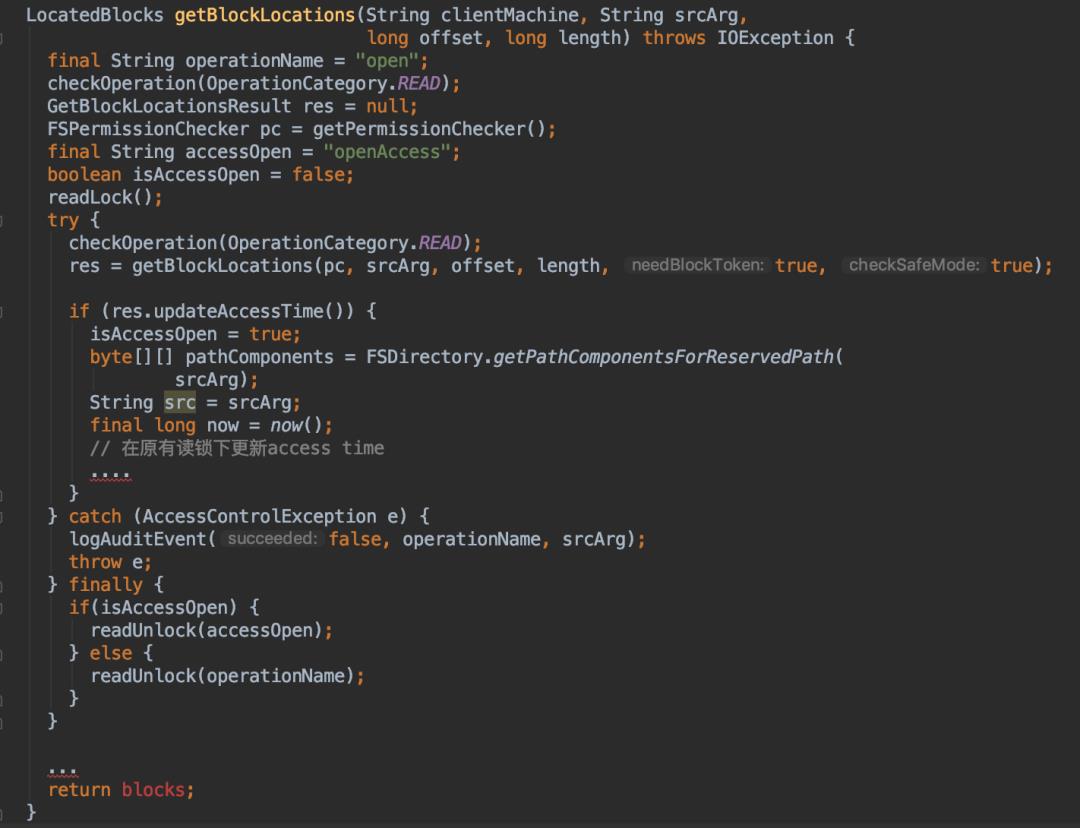
但是在读操作本身量很大的情况下,它能够产生的setTimes依然可能会很多。接下来我们做了一个大胆的改进,将setTimes要求的持写锁改成了持读锁的行为,然后将这个操作整个合并起来用读锁来保护,修改后的代码如下:
上面优化过后的代码一方面可以避免写锁的持有操作,另一方面可以减少之前读写锁之间的切换,在整个方法执行的效率上会得到提高。当然,这也可能会造成atime精度的丢失,毕竟之前是完全持互斥的写锁进行atime值的更新的。此时在读锁可以share的模式下,这个更新操作可以并发执行。这个改动的前提是我们并没有强依赖于该atime值完全准确性的要求,所以能够允许此操作更新的一点误差。
在进行上述改动后,setTimes造成的影响比之前要好了很多,很少看到Open操作的处理时间出现毛刺现象了。
这块优化的改动还涉及到另外两个地方的更新,FSNamesystem#setTimes方法和FSDirAttrOp#setTimes方法里面的写锁转读锁改动。
如果在生产环境中不需要access time的功能,我们可以通过设置dfs.namenode.accesstime.precision为0来禁用掉此功能。
在对集群每日的RPC类型做读写分析的时候,我们发现读的占比非常之高,正常情况下达到
10:1 的读写操作比。这就相当于大部分RPC队列中是读的请求,而写操作是贯穿于读请求操作中的。读写类型请求的交替穿插意味着后续NN在处理这些请求操作时会进行不断读写锁的请求释放。但其实读和读之间是可以共享的,倘若我们能把读写请求进行分批处理,就能够尽可能地发挥出读锁共享的优势,从而减少频繁读写锁之间互斥导致的开销。
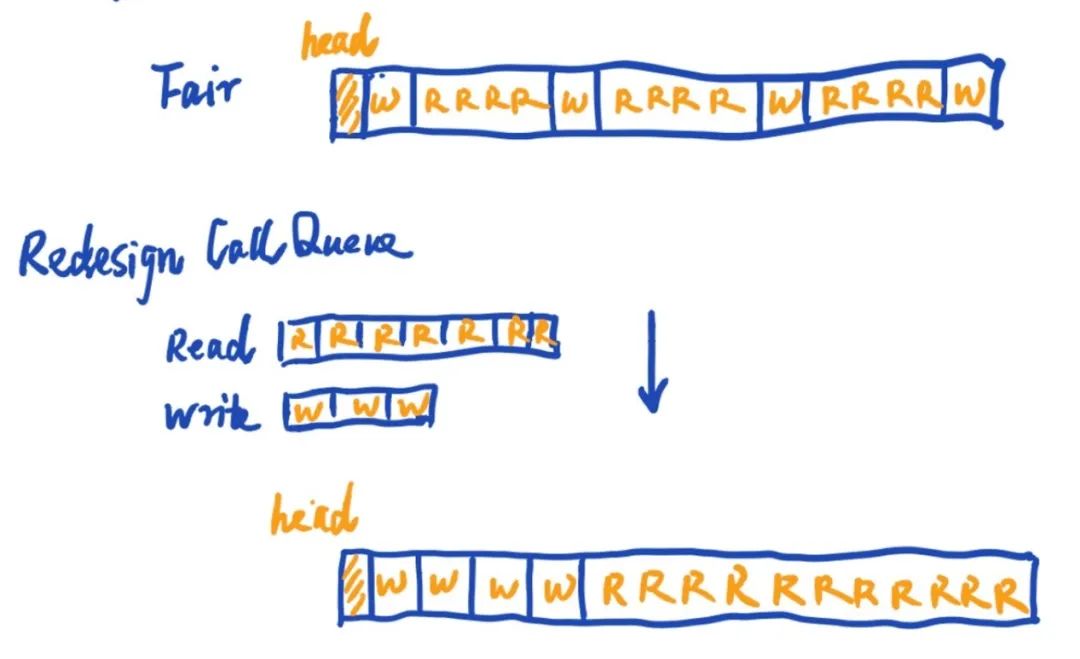
基于这个思路,我们设计了ReadWrite Callqueue,这个Callqueue实现里有2个子队列,一个是存放所有读类型的操作,另一个则是存放所有写类型相关的操作。NN在消费此ReadWrite队列的时候,采用轮询的方式依次从读队列和写队里去获取RPC请求进行处理。每次轮询周期内我们会设置有依次对应的权重值来设定此周期内处理读写请求操作的数量比。
用一个简单模拟图的效果来展示新的ReadWrite Callqueue工作模式:
原来Fair Callqueue模式,读写请求随机交叉:
RRRRWRRRRWRRRRWRRRRWRRRRWRRRRWRRRRWRRRRW
ReadWrite Callqueue模式,读写分组轮询:
RRRRRWWWWWWWWRRRRRRRRRRRRRRRRRWWWWWWWWWW
我们在测试集群用NNloadGeneratorMR工具命令,按照读写比接近
30:1 的比例,对ReadWrite Callqueue进行了性能测试,测试效果如下所示。
采用默认Fair Callqueue队列(图11左侧显示区域值):
采用ReadWrite Callqueue(图12右侧显示区域值):
结果显示,新的Callqueue实现能够带来接近于
15~20% 的RPC吞吐量的提高(图中ops数值的上升)。但是我们同时发现,当读的操作远远大于写操作的时候,ReadWrite Callqueue的优势就会越来越小,因为本身大量读操作的情况下,往往已经是share lock处理的模式了。
我们目前也已经在生产集群上应用了这个全新的Callqueue队列。关于这个ReadWrite Callqueue实现的方案细节和讨论我们也已经提交到社区。
(相关JIRA HDFS-15553:Improve NameNode RPC throughput with ReadWriteRpcCallQueue)
以上优化要归功于我组同事们的聪明才智,是过去大半年时间里大家付出的辛苦努力的结果。主要的一些优化措施历时较长,因为很多优化并不是短时间内就能想到和做到的,中间需要花很多时间不断地发现问题,解决问题。
最终结果还是比较喜人的,我们集群NN RPC的平均处理时间已经从年初的 5毫秒+ 优化到了目前的 1.5毫秒 的速度,性能提升近 70% (如图13)。我们做的HDFS相关的优化还不仅仅如此,后续还会分享给大家更多优化系列的其它文章,尽请关注。
[1] HDFS-13183. Standby NameNode process getBlocks request to reduce Active load
[2] HDFS-11225. NameNode crashed because deleteSnapshot held FSNamesystem lock too long
[3] HDFS-13831. Make block increment deletion number configurable
[4] HDFS-7964. Add support for async edit logging
[5] HDFS-15486. Costly sendResponse operation slows down async editlog handling
[6] HDFS-14731. [FGL] Remove redundant locking on NameNode.
[7] HADOOP-16266. Add more fine-grained processing time metrics to the RPC layer
[8] HDFS-10872. Add MutableRate metrics for FSNamesystemLock operations
[9] HDFS-15553. Improve NameNode RPC throughput with ReadWriteRpcCallQueue
[10] SPARK-29189. Add an option to ignore block locations when listing file
7年老码农,10W+关注者。【Java与大数据架构】全面分享Java编程、Spark、Flink、Kafka、Elasticsearch、数据湖等干货。欢迎扫码关注!
以上是关于eBay 大数据平台的 HDFS 性能优化实践的主要内容,如果未能解决你的问题,请参考以下文章
Apache Spark在海致大数据平台中的优化实践
eBay:如何用HDFS分层策略优化数千节点数百PB的数据存储
eBay的Elasticsearch性能调优实践
干货|eBay的Elasticsearch性能调优实践(上)
ElasticsearcheBay上的Elasticsearch性能调优实践
TiDB 在 eBay丨亿优百倍:商品数据服务缓存与代码优化