SQL Server数据库进阶考试题 要求用SQL语句实现(全部利用SQL语句完成)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SQL Server数据库进阶考试题 要求用SQL语句实现(全部利用SQL语句完成)相关的知识,希望对你有一定的参考价值。
员工管理系统数据库――综合考试题
创建数据库empsystem,主数据文件初始大小为3mb,最大容量为20mb,文件增长量为2mb(5分)
在empsystem数据库中创建以下两个表(15分)
Departments表
字段名称 数据类型 约束 备注
DepartId int 主键, 部门编号
departname nvarchar(50) 无 部门名称
location nvarchar(100) 无 地址
Employees表
字段名称 数据类型 约束 备注
EmpId Int 主键, 自动顺序编号 职员号
EmpName Nvarchar(50) 无 职员姓名
Job Nvarchar(50) 无 工作
MgrId int 无 上级编号
HireDate date 无 入职日期
Salary float 无 薪金
Commission float 无 佣金
DepartId int 外键,非空 部门编号
注意:(工资Pay=薪金Salary+佣金Commission)
现有表中的内容如下:
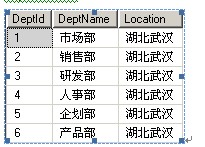
departments
employees
注意:(工资Pay=薪金Salary+佣金Commission)
--1.查询出工资比'陈芳'多的所有职员的名字,工作,入职日期,工资
--2.查询工资在3000元以上的所有的工作及工资
--3. 定义一存储过程,根据职员的姓名(输入参数)查询其上司的姓名(输出参数)
--4. 查询出入职日期晚于其上司的所有职员的名字
--5. 假定在建departments表时没有定义主键,写出为departments表追加定义主键的语句。
-6.查询出在每个部门工作的职员数量、平均工资
--7. .定义一存储过程,查询出在指定部门工作的职员数量,平均工资(输入参数部门名称,输出参数职员数量、平均工资)
--8.查询出每种工作的最高工资的职员信息及其上司信息
--9.Departments 表中的DeptId列是Employees表的一个外键,当删除Departments表中的部门时,如果该部门的DeptId在Employees表中存在,则系统拒绝执行删除操作。
现在在Departments表上创建一个INSTEAD OF 触发器remove_department,用于在对Departments表执行DELETE操作时,先删除Employees表中与该部门相关联的员工信息,然后再从Departments表中删除该部门。
--10.编写一个存储过程add_employee,使用该存储过程实现向Employees表中添加记录
帮我做好题目 给5块钱 用支付宝交易
on (filename=\'d:\\database\\empsystem_data.mdf\',
size=3mb,maxsize=20mb,filegrowth=2mb)
go
--use empsystem
create table Departments(
DepartId int not null primary key,
departname nvarchar(50),
location nvarchar(100))
create table Employees(
EmpId Int IDENTITY(1,1) primary key ,
EmpName Nvarchar(50),
Job Nvarchar(50),
MgrId int,
HireDate date,
Salary float,
Commission float ,
DepartId int REFERENCES Departments(DepartId))
go
insert Departments values(1,\'市场部\',\'湖北武汉\')
insert Departments values(2,\'销售部\',\'湖北武汉\')
insert Departments values(3,\'研发部\',\'湖北武汉\')
insert Departments values(4,\'人事部\',\'湖北武汉\')
insert Departments values(5,\'企划部\',\'湖北武汉\')
insert Departments values(6,\'产品部\',\'湖北武汉\')
go
insert Employees(Empname,Job,MgrId,HireDate,Salary,Commission,DeptId) values
(\'小刘\',\'程序员\',2,\'2009-0708\',2200,1500,3)
go
--1
select empname 姓名,job 工作,HireDate 入职日期,salary+commission 工资 from employees
where (salary+commission)>(select salary+commission from employees where empname=\'陈芳\')
--2
select job 工作,salary+commission 工资 from employees
where (salary+commission)>3000
--3
create procedure proce1
@name Nvarchar(50) ,@mgrId int output
as
select @mgrId=mgrId from employees where empname=@name
--4
--5
ALTER TABLE departments ADD DepartId int
CONSTRAINT DepartId_pk PRIMARY KEY 参考技术A 我晕死,哎 参考技术B 这么多!
SQL Server索引进阶:第一级,索引简介
SQL Server索引进阶:第一级,索引简介
By David Durant, 2014/11/05 (first published: 2011/02/17)
原文地址:
Stairway to SQL Server Indexes: Level 1, Introduction to Indexes
本文是SQL Server索引进阶系列(Stairway to SQL Server Indexes)的一部分。
索引是数据库设计的基础,向开发者显示了使用数据库大量数据库设计者的意图。不幸的是,索引大部分时候是在出现性能问题的时候,才被事后添加上的。
第一级介绍一下SQL Server的索引:是一种数据库对象,使得SQL Server可以在最短的时间内查询 or 修改请求的数据,使用最少的系统资源带来最大的性能提升。好的索引将会允许SQL Server实现最大化的并发,一个用户的查询对于其他用户的查询几乎没有影响。最终,索引给数据库完整性提供一种高效的方式,当唯一索引创建的时候,确保唯一的键值。这一级只是一个简介,包括一些理论和使用,一些物理的细节留在后面的级别中介绍。
对于数据库开发者来说,彻底的理解索引是重要的,当一个请求从客户端到达SQL Server,SQL Server只有两种可能的路径来访问请求的数据行:
- 扫描包含数据的表中的每一行,从第一行到最后一行,检查每一行是否满足请求的条件。
- 如果包含可用的索引,可以用索引来定位请求的数据。
第一种方法对于SQL Server来说总是可用的,第二种方法只在你给数据库设计了可用的索引的情况下才是可行的,但是第二种可以带来极大地性能提升,接下来我们将继续介绍。
因为索引需要维护(它们会占用物理空间,并且它们一定会和表保持同步),所以它们不是SQL Server必须的。有的数据库会完全没有索引。它们可能会导致性能下降,有可能带来数据完整性问题,但是SQL Server允许它的存在。
但是,这些不好的不是我们想要的。我们都希望数据库性能优良,数据完整,同时,保持索引维护的最小化。本级别将会朝着这个目标引导大家。
数据库实例
贯穿整个进阶系列,我们都会使用实例来阐述关键的理念。这些例子使用的是微软的
AdventureWorks 示例数据库。我们主要使用销售订单部门。包含5张表:Customer, SalesPerson, Product, SalesOrderHeader, SalesOrderDetail。为了保持注意力的集中,我们使用部分的列。
AdventureWorks 设计的很规范,销售人的信息在三张表中都有:SalesPerson,Employee,Contact。在某些情况下,我们会把他们看成是一张表。下图是这些表之间的关系。
本级别用到的TSQL在后面都会给出下载地址。
什么是索引
通过一个小故事开始我们的索引学习之旅,一个很老,但是证明很技术,贯穿整篇本章,介绍索引的基本概念。
你离开家去处理一些事情。当你回来的时候,从等待你回来的女儿的垒球教练口中得到一些消息。三个女孩子:Tracy,
Rebecca, and Amy弄丢了他们的帽子。你能否给他们买帽子,下一场比赛他们的父母将会还给你。
你认识那些女孩子,也认识他们的父母。但是你不知道他们帽子的尺寸。在你家的镇子上有三家人,每家都有一些你需要的信息。没有问题,你会打电话给他们,得到帽子的尺寸。你一手拿着电话,一边打开电话本的目录索引。
你需要联系的第一家是Hellen Meyer,你估计Meyer应该在姓名的中部,你直接跳到电话本的中间部分,但是你发现来到了页头部写着“Kline-Koerber”的一页,向前翻了几页,又发现了“Nagle-Nyeong”,又向前翻了几页,发现了“Maldonado-Nagle”。意识到你快要找到了,向后查找,你找到了“Meyer,Helen”一行,找到的对应的号码。打通了Meyer的家,得到了你想要的信息。
重复上面的过程,找到了另外两个家庭,获取了另外两个帽子的尺寸。
你使用了索引,你使用索引的方式和SQL Server使用索引的方式类似。他们有很多的相似,有一些不同,电话本和SQL Server的索引。
事实上,你刚才使用的就是SQL Server两种索引(聚集和非聚集)中的一种,非聚集索引。本级别我们介绍非聚集索引,下一级别介绍聚集索引,以及深入的分析这两种索引。
非聚集索引
白纸类似非聚集索引,他们不是以数据本身来组织的,只是一个映射,帮助你访问数据。数据本身才是我们真正需要的。电话公司没有将镇子的居民整理到一个有意义的队列中,将房子从一个地方移动到另一个地方,方便同一个垒球队的女孩们的家是一个挨一个的,而不是像现在这样用居民的姓氏来组织。相反,他给你一本书,包含每个居民。每行都包含一个键,使得你可以访问到居民的电话。
就像白纸上的电话一样,SQL Server的非聚集索引都包含两部分的内容:
查询键,例如:姓氏-名称-中间部分这样的格式,在SQL Server的词汇中,叫做索引键。
标签,提供相同的内容,那就是电话号码,SQL Server中则直接指向键代表的数据行。
另外,一个SQL Server非聚集索引还会包含一些内部使用的头部信息,可能会包含一些可选的信息。这些内容在后面的级别中会有介绍,现在还不是理解非聚集索引的重点内容。
就像电话本一样,SQL Server的索引维护一个查询键,经过几次小的跳转就会找到想要访问的入口。给出一个查询键,SQL Server可以快速的定位入口。不像电话本,SQL Server的索引是动态的。那就是说,每次增加一行,删除一样,或者是包含查询键的一列被修改,SQL Server都会更新索引。
就像在电话本上两个挨着的家庭,在地理位置上不是挨着的一样,在非聚集索引中挨着的两个入口,也不是表中挨着的两行数据。第一个入口可能是表中的最后一行,第二个入口可能是表中的第一行。事实上,不想索引,入口通常是有意义的序列。表中的行是完全无序的。
当我们创建一个索引,SQL Server会产生并且在额外的表中精确的维护每一行的入口。在一张表可以创建多于一个的非聚集索引。
最大的不同是:SQL Server不能使用电话。他只会使用标签中的信息,才可以导航到对应的表中的行。
创建并且从非聚集索引中受益
我们通过两次示例数据库的查询来结束这个级别,确保你使用的示例数据库是SQL
Server 2005的AdventureWorks 数据库,也可以是SQL Server 2008。每次我们会执行相同的查询,但是第一次是在创建索引之前,第二次是在创建索引之后。每一次,SQL Server都会告诉我们获取数据需要做多少工作。我们将在Contact表中查询Helen Meyer行(大概在表的中间部分)。初始时候,在FirstName或者是LastName列没有索引,为了确保执行正确,可以通过下面的代码来删除索引。
- IF EXISTS (SELECT * FROM sys.indexes
- WHERE OBJECT_ID = OBJECT_ID(‘Person.Contact‘)
- AND name = ‘FullName‘)
- DROP INDEX Person.Contact.FullName;
开启IO和时间统计
- SET STATISTICS io ON
- SET STATISTICS time ON
- GO
执行查询
- SELECT *
- FROM Person.Contact
- WHERE FirstName = ‘Helen‘
- AND LastName = ‘Meyer‘;
- GO
我们会看到执行结果,也就是Helen的信息。
在消息tab中我们会看到
- 表 ‘Contact‘。扫描计数 1,逻辑读取 561 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
- SQL Server 执行时间:
- CPU 时间 = 0 毫秒,占用时间 = 9 毫秒。
信息中显示本次查询产生逻辑IO 561次,处理器占用9毫秒的时间。你显示的内容会和处理器的不同而不同。
建立非聚集索引
- CREATE NONCLUSTERED INDEX FullName
- ON Person.Contact
- ( LastName, FirstName );
- GO
再次执行查询
- SELECT *
- FROM Person.Contact
- WHERE FirstName = ‘Helen‘
- AND LastName = ‘Meyer‘;
- GO
这次看到的信息变成了
- 表 ‘Contact‘。扫描计数 1,逻辑读取 4 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
- SQL Server 执行时间:
- CPU 时间 = 0 毫秒,占用时间 = 1 毫秒。
建立索引之后只需要4次逻辑IO,更少的处理器占用时间。
结论
创建合适的索引可以极大的提升数据库性能。在下一级别,我们会了解索引的物理结构。我们将会知道非聚集索引为什么会对查询有好处。还会介绍其他类型的索引,索引的其他好处,索引相关的代价,监控和维护索引,和一些最佳实践。目标就是告诉你建立索引所必须的知识。
代码下载
以上是关于SQL Server数据库进阶考试题 要求用SQL语句实现(全部利用SQL语句完成)的主要内容,如果未能解决你的问题,请参考以下文章
全国计算机三级数据库考试用的是mysql还是sql server?
SQL Server Extended Events 进阶 3:使用Extended Events UI