SQL Server Extended Events 进阶 3:使用Extended Events UI
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SQL Server Extended Events 进阶 3:使用Extended Events UI相关的知识,希望对你有一定的参考价值。
开始采用Extended Events 最大的阻碍之一是需要使用Xquery和XML知识用来分析数据。创建和运行会话可以用T-SQL完成,但是无论使用什么目标,数据都会被转换为XML。这个限制在SQL Server 2012中已经被移除,它已经实现了Extended Events 用户界面。在SQL Server 2014中也基本没有变化,如我们在进阶2中所见,这个UI提供了创建和管理会话功能。在本阶中,我们将探索捕获数据的查看和处理的功能。
查看数据
当创建并启动会话后,我们有两种选择查看事件数据:实时数据查看器和目标数据查看器。
为了完成例子中的内容,你可以创建Listing 1中所示的XE_SampleCapture会话。它将捕捉batch,Statement和Procdeure 完成事件以及相关事件字段:
query_hash - 标识具有相似逻辑但是查询计划不同的查询
query_plan_hash 标识具有不同的查询计划但有相似逻辑树的查询计划
这两字段分别关于查询指纹和计划指纹。我们使用这些字段主要用于分析Ad-Hoc负载,查找非常相似但却有细微区别的查询,如具有不同的值(difference values of their concatenated literals)。
CREATE EVENT SESSION [XE_SampleCapture] ON SERVER ADD EVENT sqlserver.rpc_completed ( ACTION ( sqlserver.database_id, sqlserver.query_hash, sqlserver.query_plan_hash ) WHERE ( [sqlserver].[is_system] = ( 0 ) ) ), ADD EVENT sqlserver.sp_statement_completed ( SET collect_statement = ( 1 ) ACTION ( sqlserver.database_id, sqlserver.query_hash, sqlserver.query_plan_hash ) WHERE ( [sqlserver].[is_system] = ( 0 ) ) ), ADD EVENT sqlserver.sql_batch_completed ( ACTION ( sqlserver.database_id, sqlserver.query_hash, sqlserver.query_plan_hash ) WHERE ( [sqlserver].[is_system] = ( 0 ) ) ), ADD EVENT sqlserver.sql_statement_completed ( ACTION ( sqlserver.database_id, sqlserver.query_hash, sqlserver.query_plan_hash ) WHERE ( [sqlserver].[is_system] = ( 0 ) ) ) ADD TARGET package0.event_counter, ADD TARGET package0.event_file ( SET filename = N‘C:\\temp\\XE_SampleCapture‘ , max_file_size = ( 512 ) ), ADD TARGET package0.histogram ( SET filtering_event_name = N‘sqlserver.sql_statement_completed‘ , slots = ( 16 ) , source = N‘sqlserver.database_id‘ ), ADD TARGET package0.ring_buffer ( SET max_events_limit = ( 10000 ) , max_memory = ( 4096 ) ) WITH ( MAX_MEMORY = 16384 KB , EVENT_RETENTION_MODE = ALLOW_SINGLE_EVENT_LOSS , MAX_DISPATCH_LATENCY = 30 SECONDS , MAX_EVENT_SIZE = 0 KB , MEMORY_PARTITION_MODE = NONE , TRACK_CAUSALITY = ON , STARTUP_STATE = OFF ); GO
为了生成一些样本数据,我执行了Jonathan Kehayias 为 AdventureWorks创建的随机负载生成脚本(https://www.sqlskills.com/blogs/jonathan/the-adventureworks2008r2-books-online-random-workload-generator/),它可以生成多个连接,同时创建了一些存储过程,并重复执行他们。你可以在文章底部下载它。你的输出结果与我的可能并不完全相同,但是结果应该相似。
实时数据查看器
Live Data Viewer总是可用的,无论会话设置了什么类型的目标,甚至是没有设置目标,它会简单的显示出捕获的数据。打开查看器仅需右键选择任何运行中的会话并选择"Watch Live Data"。你可以使用上面创建的XE_SampleCapture会话,如果喜欢也可以使用system_health会话。图1显示了一些数据样例。
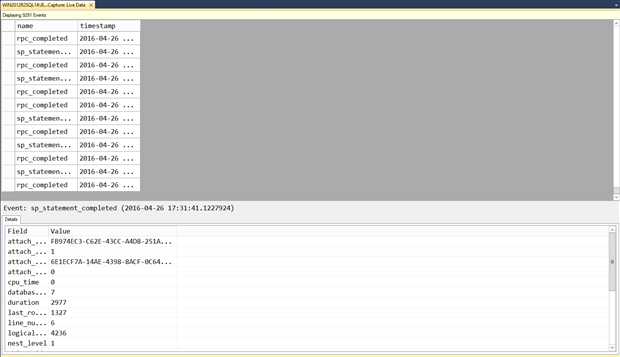
Figure 1
初始化后可能不会显示任何数据,尤其是你尝试打开system_health 会话时,因为事件显示在查看器中的速度主要取决于你收集的事件和谓词。如果你有一个可以快速捕捉数据的会话,那么一旦事件会话的调度周期到达,或者缓冲区被填充,事件会被调度到查看器和会话中定义的其他目标。
调度周期和内存缓冲
Extended Events引擎首先将事件数据流写入指定会话的中间缓冲区。调度周期是一个会话级别的选项,用于定义将事件数据从内存写入目标的频率,以秒为单位。
除非你导出数据,否则实时查看器中的数据并不会被持久化。你必须停止实时查看器的数据推送后才能使用这个选项(通过 Extended Events主菜单中的Stop Data Feed)。选择实时数据查看器窗口,转到Extended Events | Export to来选择导出目标。
你可以随时停止数据推送或者关闭查看器,同时在前一阶中我们提到过,SQL Server如果检测对性能有负面影响时,查看器会自动停止。
目标数据查看器
另外一个查看会话数据的方式是右键点击目标,然后然后选择View Target Data…选项。这个菜单根据选择的目标显示不同的视图
查看 event_file目标数据
如果是选择了一个event_file 目标,则显示已经被写入硬盘的目标文件中的事件数据。这些信息不会更新,仅显示打开文件那一刻已经存在的数据。
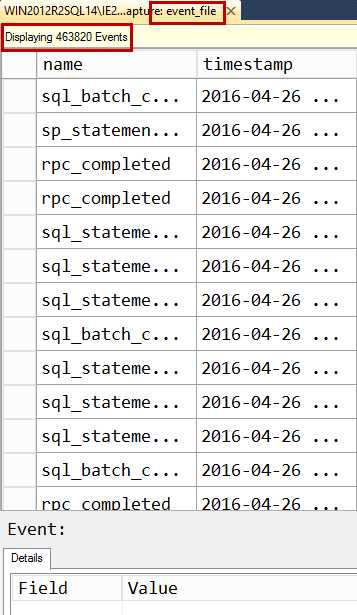
Figure 2
对于一个event_file目标,这个选项与实施数据查看器对比的好处是它不需要SQL Server同时将数据流写入目标和Management Studio。它仅仅读取已经被目标消费后的数据。
event_file 目标捕捉的数据可以在事件会话停止后在SQL Server Management Studio 中查看,因为他们会以.xel文件保存在硬盘上。你可以拖拽一个.xel文件到SSMS中,或者使用 File | Open | File…菜单选项打开一个.xel文件。system_health会话的默认文件路径在默认的错误日志文件夹中。
这个查看器看起来极为相似,除了windows窗口中的文件名不一样 (XE_SampleCapture_0_131061823727010000.xel), 实时查看器显示Live data和目标查看器显示event_file。
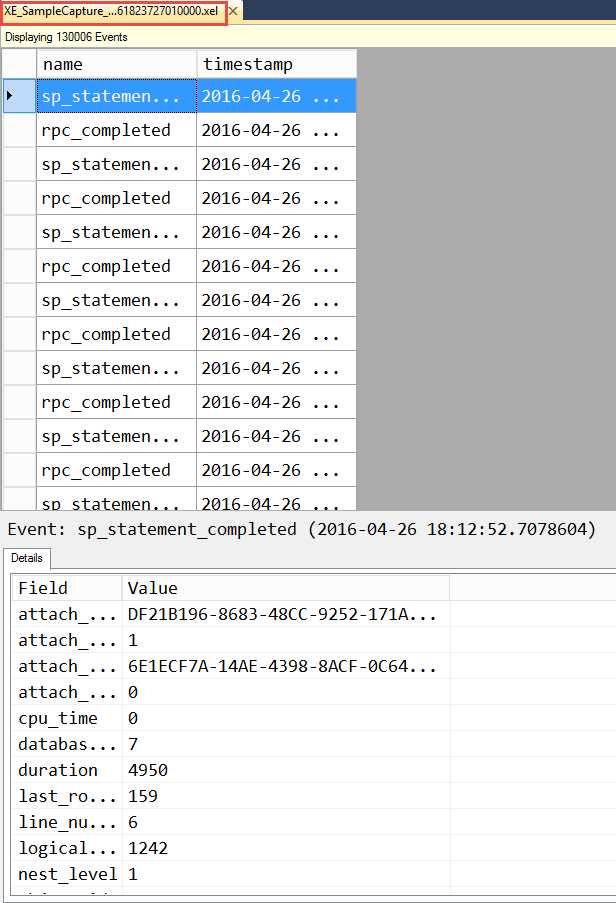
Figure 3
查看ring_buffer目标数据
当使用ring_buffer目标是,View Target Data选项不是非常有帮助,因为它以整个的XML链接格式显示。

Figure 4
点击链接后,数据以xml格式显示,但是对于分析也不是很有帮助。
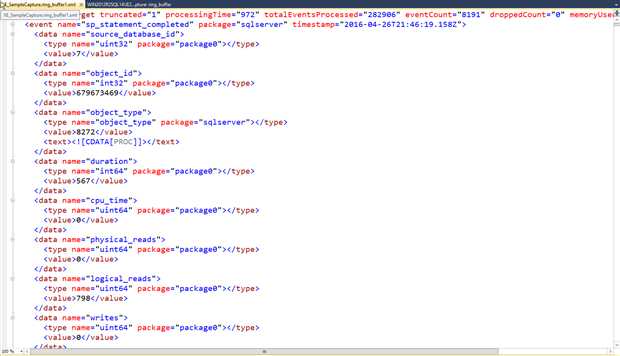
Figure 5
当使用ring_buffer 目标是,我们需要使用XQuery分析事件数据。
查看event_counter, histogram 和pair_matching 目标数据
最后三种目标event_counter, histogram, 和pair_matching,需要你查看目标数据或者使用XQuery分析数据,这是仅有的两种查看聚合数据的方式。使用我们的XE_SampleCapture会话,或其他具有histogram 目标的会话,右键选择histogram 目标并打开目标数据视图,如图6所示的输出。
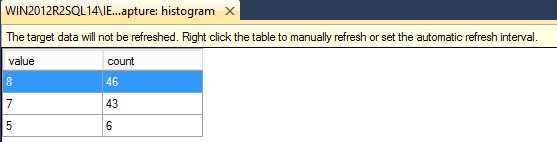
Figure 6
histogram 目标数据视图开始可能是空的,也可能会有数据。这个查看器需要被刷新才会显示最新数据。为了手动跟新它,可以在histogram 目标窗口中右键点击Refresh,或者你可以选择 Refresh Interval 让窗口定时更新。
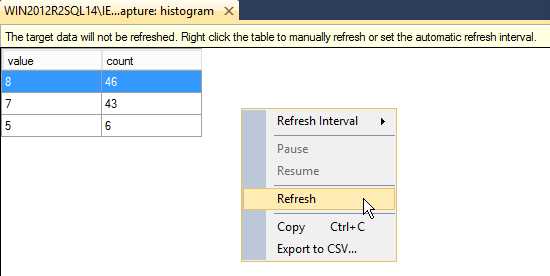
Figure 7
histogram, event_counter 和pair_matching等三种目标在内存中保存数据,一旦你停止事件会话,内中种的数据也会飞释放,因而视图中的数据也会消失。如果你需要保存数据,你可以通过右键的Copy选项,或者右键的Export to CSV选项导出.csv文件(请参考图7)。
你可以在停止一个会话后选择复制或者保存当前显示在目标数据查看器中的数据,但是对于这些目标,一旦你在停止会话后刷新了查看器,数据将会丢失。
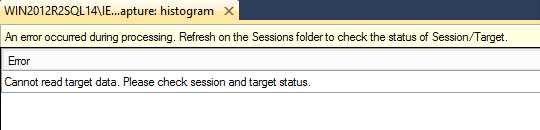
Figure 8
显示选项:定制列
无论哪种查看器,你都可以定制显示的列。默认情况下,只有事件名和时间戳显示在顶部的面板中,因为这两列是所有所有事件所共有的。当你选中顶部面板中的列时,详细面板会显示所有捕获的字段。想要在顶部面板中产看任何字段,你可以在详细面板中右键选择所需的列,并选择Show Column in Table。在图9中,我们添加了duration 字段到顶部面板中。
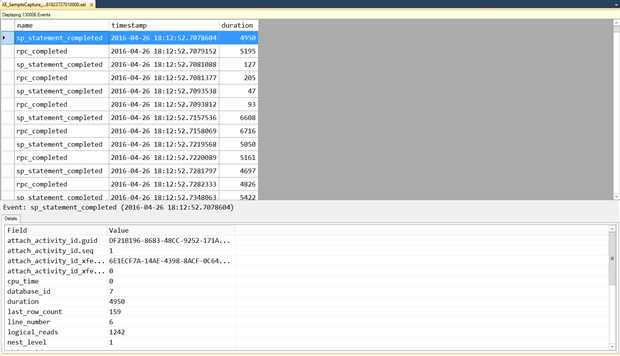
Figure 9
我们可以重复以上步骤将我们需要的字段都添加到顶部面板中。这些列可以通过拖拽列名进行左右移动位置。或者,你可以通过 Extended Events工具栏上的Choose Columns… 按钮,或者Extended Events | Choose Columns… 菜单选项来选择列或者配置列的顺序。如果你没有看Extended Events工具栏,可以使用View | Toolbars菜单来选择。
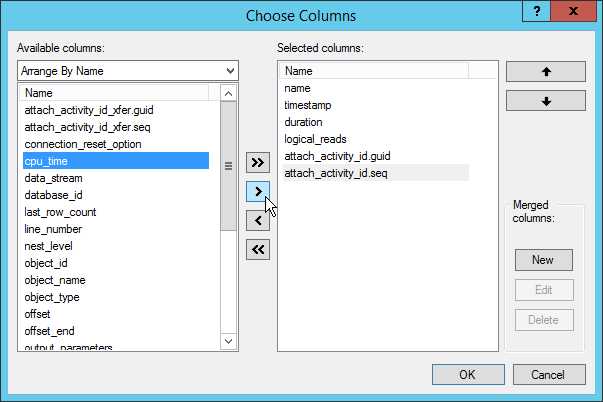
Figure 10
在查看器中可以使用的技巧之一就是合并列,换句话说你可以根据已有的两列或更多列来创建一个新列。这对捕捉查询语句存储在不同字段的事件非常有帮助。例如sp_statement_completed 事件使用statement 字段存储查询语句,batch_completed 事件使用batch_text 字段。如果你同时将这两个字段都加到顶部面板中,你会发现对于batch_completed 事件statement 字段总是为NULL,同样,对于sp_statement_completed事件batch_text 字段也为NULL。
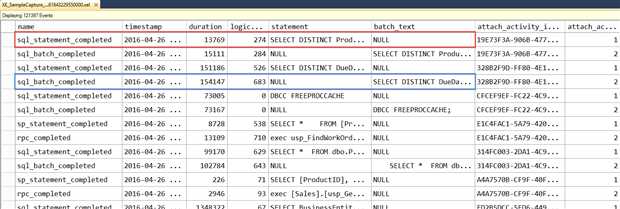
Figure 11
数据在不同的字段中会阻碍我们的分析,但是如果将他们合并为一列缓解了这一问题。在Choose Columns… 窗口的右下角你可以找到一个Merged columns。选择New,为新列提供一个名字,并选择你要合并的列,如图12所示。
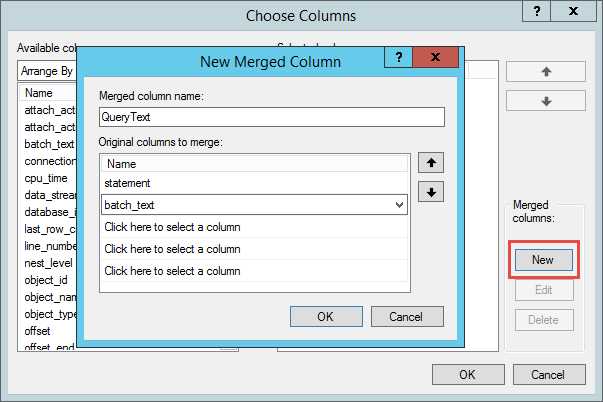
Figure 12
新的合并列将以[QueryText]为名显示在查看器中。注意合并列选项专为字符串连接设计,因此如果你选择了非字符串数据类型,并不是所有的数据都可以正常显示。例如,如果你尝试连接logical_reads 和database_id,它金辉显示logical_reads。
在你根据所需的字段定制查看器后,在需要的情况下,你可以通过 Extended Events菜单来保存配置,或者通过Display Settings按钮。
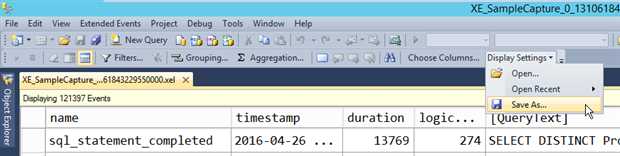
Figure 13
配置文件以.viewsetting 文件格式保存,然后在以后需要查看或分析event_file 目标时,通过同样的菜单打开这个文件。这个文件可以被共享或者保存在多个用户可以访问的网络地址中。最后,一旦顶部面板中显示了所有你需要的列后,如果你要在查看器中移除详细面板,可以选择Extended Events | Show Details Pane菜单。
分析数据
查看器提供了一个我们所熟悉的事件视图。但是与Profiler UI不同,在这里我们有能力对列进行排序并过滤数据,extended events查看器提供了更好的数据分析选项,我们不再需要将数据在导出到表中,或者使用第三方工具。
排序
你可以做的最简单的事情之一就是对事件排序。仅需右键选择列名然后选择Sort Ascending 或Sort Descending排序(你也可以直接点击列名排序,再次点击的时候以反序排序)。当你想要快速的找到执行时间最长,IO最高的事件时,对UI上的数据排序是最简单的方式。
过滤
使用工具栏上的Filters… 按钮(或者Extended Events | Filter…菜单)对查看器中的数据进行过滤。我们可以使用时范围或者其他任何字段进行过滤,包括为事件收集的全局字段。进一步,我们可以通过使用AND,OR和其他运算(=, <>, Like, Not Like, Null等)创建复杂的条件,就像我们在谓词中一样。
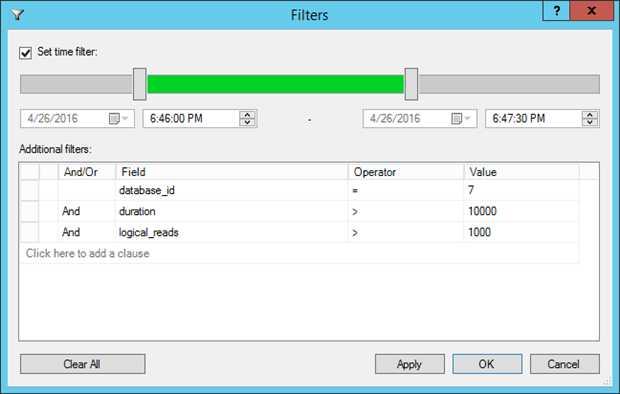
Figure 14
应用过滤后,结果集可以被保存在新的.xel文件中。如果原始的.xel文件被关闭时没有移除过滤条件,请注意重新打开文件时,这些过滤依然生效。一个好的习惯是检查当前显示的事件数量,来判断是否有过滤条件被应用在了分析上,如图15所示。
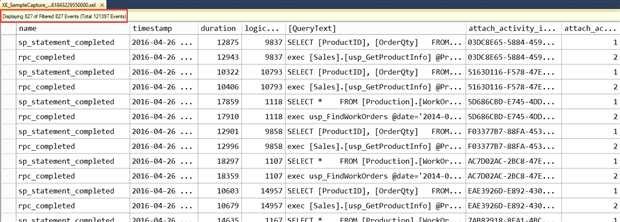
Figure 15
可以通过filters 窗口或者选择Extended Events | Clear All Filters菜单来移除过滤条件。
合并.xel 文件
在我们经常需要过滤结果来分析数据的同时,在一些情况下,我们也需要从多个文件中抓取数据进行全面的分析。一个例子,当我们在跨越多个节点的Availability Group中排除故障时,你可能为每一个节点设置一个会话,然后将多个节点中的目标文件合并在一起查看。为完成这个目标,通过SSMS选择File | Open | Merge Extended Events Files菜单,找到文件路径并将他们添加到窗口中,然后选择OK。
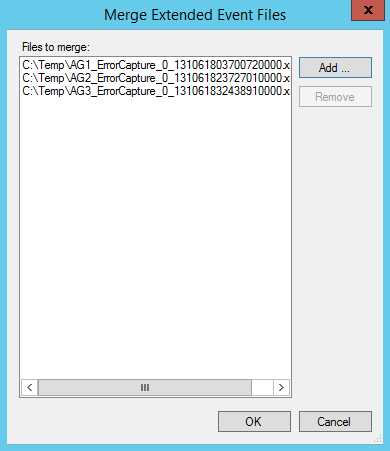
Figure 16
合并后的文件将按照一个结果集输出进行分析,同时你可以保存为单独的.xel文件。
搜索
Profiler UI中也提供了搜索功能,这对于搜索查询语句中的字符尤为有用。Extended events 查看器提供了同样的功能,位于工具栏中的望远镜图标(或选择Extended Events | Find菜单)。
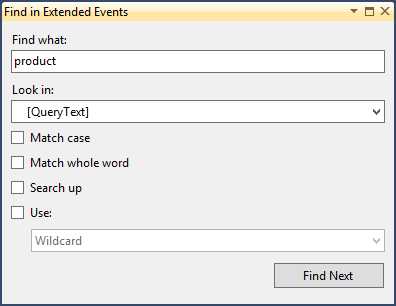
Figure 17
在Find窗口中你可以搜索任何已经添加到顶部面板的字段。如果你没有在查看器的顶部面板添加任何额外的字段,默认情况下仅可以搜索name 和timestamp列。每次仅可以在一个列中进行搜索,你可以选择其他的标准的搜索选项,包括匹配大小写和全字匹配,同时也可以使用通配符或者正则表达式。
标记行
当找到含有我们感兴趣的数据行时,我们可以在查看器中使用书签标记他们(熟悉使用Profiler的用户过去可能经常会写下行号,这都已经成为过去时了)。选中我们感兴趣的行,然后点击工具栏中的Bookmark 按钮(或者点击右键菜单中的Toggle Bookmark)即可。书签图标会显示在查看器的最左边。
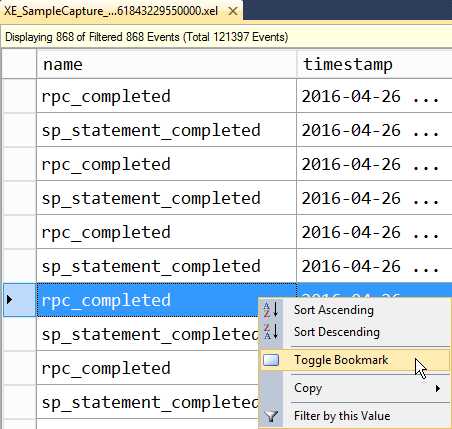
Figure 18
当你标记完所有感兴趣的行后,你可以使用工具栏上的向前向后导航按钮快速的访问他们(再不需要无止境的滚动鼠标了)。这些按钮使你可以轻松的浏览整个文件,仅停止在那些感兴趣的事件上。如果过你想要移除某个书签,仅需右键点击行后选择Toggle Bookmark。如果你想要删除所有书签可以使用Clear All Bookmarks按钮。请注意,当你关闭文件并再次打开时所有的书签都会丢失。
分组
当我们在事件数据中合并列、过滤数据和查找指定值时,可能很有趣并且对我们分析数据有帮助,但是它们不能帮我们从整体上找到数据的发展趋势或者异常现象。进入分组,这个分析选项是extended events 查看器远远超越Profiler的原因之一。对于查看器顶部面板中的任何字段选,你都可以右键点击它并选择Group by this column。


Figure 19
你也可以使用Grouping… 按钮或者 Extended Events | Grouping… 选项,他们的好处是你可以轻松的使用多个列作为分组条件。在查看器中,在我已经使用其中一列进行分组后,如果我右键选择另外一列进行分组,原来的分组条件将被移除。在很多情况下你可能会需要根据多个列进行分组,这时,使用分组窗口将允许你选择多列,并设置列的顺序。
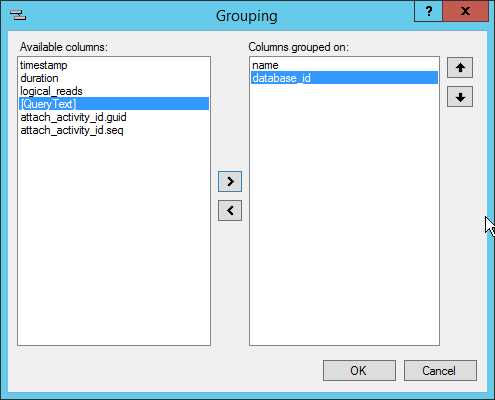

Figure 20
通用的分组字段包括:
- event (事件名称)
- object_name or object_id
- database_name or database_id
- login fields (e.g. username, nt_username)
- client_app_name
- client_hostname
在duration, logical_reads 或CPU等字段上分组没有任何意义。因为他们提供的是事件的度量指标,但你并不是在寻找那些20ms中完成的事件,或者需要特定IO数量的事件。 而是在某一服务器,或者特别的程序,或数据库的事件中寻找某些模式或者异常情况。
尝试使用Statement(或Batch_Text)进行分组的情况会经常遇到,因为我们想找到那些查询会被频繁的执行。当我们使用SQL Trace 捕获数据时,第三方工具可以为我们提供这些分析,如ClearTrace 和ReadTrace。这些工具会格式化文本数据并进行聚合,一次你可以查看指定的查询或存储过程的执行频率。
不幸的是,Extended Events不具有格式化数据功能。如果你尝试在statement 或batch_text (或我们定义的 QueryText) 字段上进行分组,你最终得到的结果可能是所有数据都只有一行。
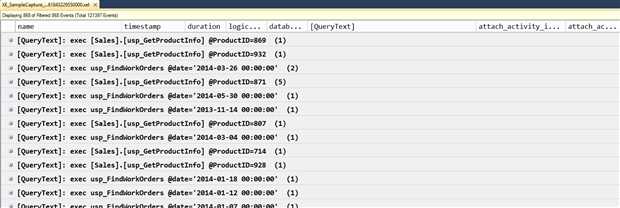
Figure 21
你需要在query_hash 或query_plan_hash字段上进行分组,而不是在查询文本上。这两个字段在 SQL Server 2008 中被添加到sys.dm_exec_query_stats 管理视图,通常也被称为"query fingerprints"。
具有相同文本的查询具有相同的query_hash,因此可以使用它作为分组条件查看一个查询的执行频率。

Figure 22
一旦你可以将相同的查询进行分组,你接下来就可以对每个分组计算平均值,最大值,最小值等额外的分析。
聚合
最后一个分析工具是使用UI上的聚合选项。在应用聚合前你必须使用至少一个字段进行分组。对于非数字字段,数学计算无法被应用(如,batch_text, database_id, xml_report),唯一可用的聚合选项是COUNT。对于数字字段,额外的选项包括SUM, MIN, MAX, 和AVG。我们可以在字段上点击右键并选择 Calculate Aggregation…,应用聚合选项。你可以可以使用工具栏中的 Aggregation…按钮,或者Extended Events | Aggregation…菜单。
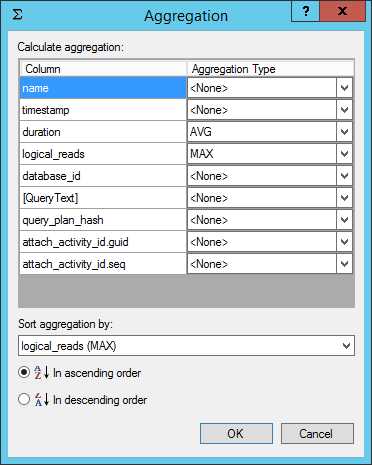
Figure 23
图24展示了聚合后的结果。
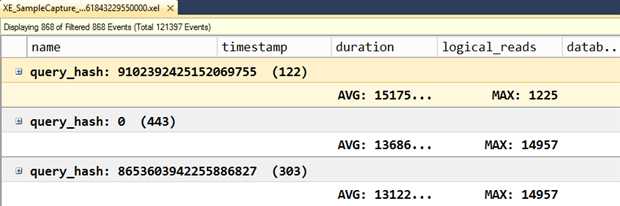
Figure 24
你可以为不同的字段应用不同的聚合方法,如AVG 应用到duration, MAX应用到logical_reads,但是对于一个字段每次只能应用一个聚合选项。也就是对于一个字段你仅可以查看AVG 或者只查看MAX。这里有一个有趣的变通方式可以为相同的字段应用不同的聚合选项。你可以创建一个合并列来表示那一列。例如,如果你即想看duration的平均值也想看duration的最大值,你可以首先将AVG 聚合函数应用到duration列上,然后我们在duration 上创建一个合并列(稍不同的名字),另外一列选择一个总是为零的字段如connection_reset_option。一旦你创建了合并列,你就可以在它上面应用MAX 了。
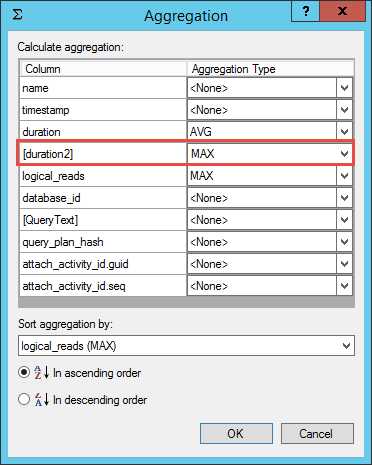
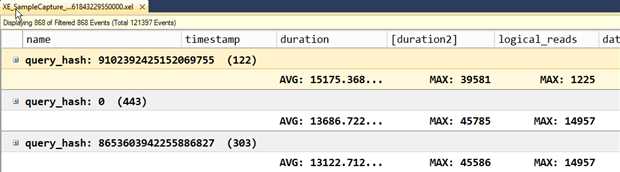
Figure 25
关闭和重新打开文件时,合并列是被持久化的。但是分组和聚合却不可以,他们并不会被保存在.viewsetting文件中。
总结
SQL Server 2012中,用户最大的胜利是它引入了目标数据查看器,这意味着我们不在需要T-SQL和XQuery就可以分析事件数据了。目标数据查看器是的我们可以产看除ring_buffer 以外所有的目标事件数据(还有etw_classic_sync_target,它仅可以通过 ETW 工具进行查看)。
另外, Extended events UI中比Profiler UI提供了更多重要的数据分析选项。除了搜索和过滤,我们现在可以对数据进行排序,分组,聚合等复杂的分析, 而不再需要将数据导入表中并使用SQL进行分析,或者使用ReadTrace这样的第三方工具。
以上是关于SQL Server Extended Events 进阶 3:使用Extended Events UI的主要内容,如果未能解决你的问题,请参考以下文章