网络爬虫是啥?具体要学哪些内容?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了网络爬虫是啥?具体要学哪些内容?相关的知识,希望对你有一定的参考价值。
之前有接触过点Python课程,想学习这个看了某公有,有了解具体讲什么内容吗?
参考技术A 网络爬虫又称网络蜘蛛、网络蚂蚁、网络机器人等,可以自动化浏览网络中的信息,当然浏览信息的时候需要按照我们制定的规则进行,这些规则我们称之为网络爬虫算法。使用Python可以很方便地编写出爬虫程序,进行互联网信息的自动化检索。①要具备扎实的python语法基础,这是一切的根基
②对前端知识有一定的了解,起码做到能看懂
③如何获取目标数据:requests模块等
④如何解析目标数据:正则,xpath,jsonpath等
⑤如何做到做到反反爬:经验总结
⑥如何大规模批量获取数据:scrapy框架
网络爬虫简介
1. 什么是网络爬虫
(1) 网络爬虫又称网络蜘蛛,可以自动化浏览网络中的信息,进行互联网信息的自动检索
(2) 搜索引擎会在海量的互联网信息中爬取优质信息并收录,当用户在搜索引擎上检索对应关键词时,会从收录的网页中按照一定的算法或排名规则呈现给用户
(3) 大数据也离不开网络爬虫,需要使用网络爬虫去一些比较大型的站点爬取数据源,进行大数据分析或数据挖掘
2. 为什么要学网络爬虫
(1) 学习网络爬虫,可以私人定制一个搜索引擎,更好地理解数据采集原理
(2) 为大数据分析提供更多高质量的数据源,获取更多有价值的信息
(3) 可以更深层次地理解搜索引擎爬虫的工作原理,从而可以更好地进行搜索引擎优化
(4) 从就业角度来说,爬虫工程师也是紧缺的人才,学习网络爬虫对就业来说非常有利
3. 网络爬虫的组成
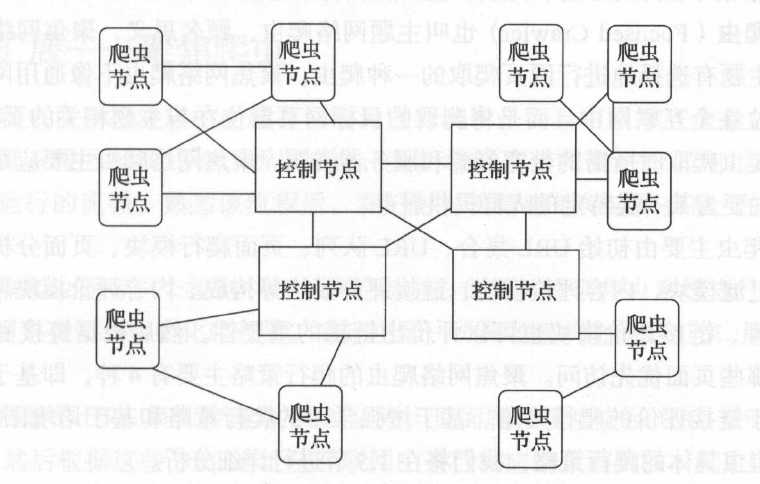
(1) 网络爬虫由控制节点 、爬虫节点 、资源库组成
(2) 控制节点,也就是爬虫节点的中央控制器,负责调用爬虫节点进行爬取
(3) 爬虫节点会按照相关的算法,对网页进行具体的爬取,爬取后的结果会存储在资源库中
4. 网络爬虫的类型
(1) 通用网络爬虫:也称全网爬虫,顾名思义,就是爬取的目标是互联网中的所有数据资源,主要应用于大型搜索引擎中
(2) 聚焦网络爬虫:也称主题网络爬虫,按照预先定义好的主题有选择地进行网页爬取,爬取特定的资源
(3) 增量式网络爬虫:即第二次爬取相同网页时,只爬取内容发生变化的数据,对于没有发生变化的不再爬取
(4) 深层网络爬虫:不需要登录就能获取的页面叫做表层页面,需要提交表单登录后才能获取的页面叫做深层页面,爬取深层页面需要想办法填写好表单
(5) 用户爬虫:指的是专门用来爬取互联网中用户数据的一种爬虫,价值相对较高,可以用来做抽样统计 、营销 、数据分析
5. 网络爬虫的工作流程
(1) 网络爬虫由控制节点 、爬虫节点 、资源库组成;以搜索引擎或聚焦网络爬虫为例,先确定好要爬取的主题和要爬取的初始URL
(2) 控制节点调用爬虫节点对初始URL进行爬取,爬行过程中,会爬到一些新的URL,会根据主题过滤掉一些URL,然后把剩下的URL根据优先级添加到URL队列等待爬取
(3) 爬虫节点爬取到的数据会存放到资源库中,资源库对爬取到的资源进行分析并建立索引,当用户检索对应信息时,可以从索引中进行检索并呈现给用户
6. 网络爬虫的爬行策略
网络爬虫爬行过程中,会爬到一些新的URL,对这些 URL 爬取的顺序,是由爬行策略来决定的
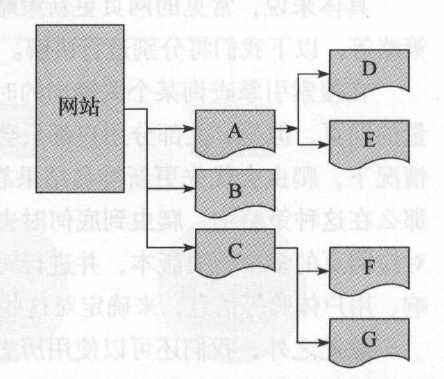
(1) 深度优先爬行策略:先爬取一个网页,然后将这个网页的下层链接依次爬取完再返回上一层进行爬取,如下图,爬取的顺序是 A → D → E → B → C → F → G
(2) 广度优先爬行策略:先爬取同一层次的网页,同一层次的网页爬取完之后再选择下一个层次的网页进行爬取,如下图,爬取的顺序是 A → B → C → D → E → F → G
(3) 大站优先爬行策略:按照网页所属的站点进行归类,如果某个网站的网页数量多,就称其为大站,优先爬取
(4) 反链爬行策略:反链指的是该网页被其他网页指向的次数,这个次数在一般程度上代表着该网页被推荐的次数,因此反链数量多的被优先爬取
7. 网络爬虫的更新策略
一个网站的网页经常会更新,在网页更新之后,作为爬虫方,我们则需要对这些网页进行重新爬取,有以下几种策略进行重新爬取
(1) 用户体验策略:我们从浏览器搜索一个关键字,会出现一个排名结果,我们可以根据排名靠前的网页更新爬虫程序,对其进行爬取,这种更新策略称为用户体验策略
(2) 历史数据策略:一般我们不知道网站什么时候更新,但我们可以通过爬取的历史数据,分析出网站的更新周期,确定对这些网页的爬取周期,以此更新爬虫程序
(3) 聚类分析策略:聚类指的是共性较多的网页聚为一类,比如新闻类网站,购物类网站等等,确定爬虫程序要爬取哪一类数据
以上是关于网络爬虫是啥?具体要学哪些内容?的主要内容,如果未能解决你的问题,请参考以下文章