反反爬虫的技术手段都有哪些?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了反反爬虫的技术手段都有哪些?相关的知识,希望对你有一定的参考价值。
参考技术A 反爬虫就是和爬虫抗衡,减少被爬取。
因为搜索引擎的流行,网络爬虫已经成了很普及网络技术,
相当部分国内爬虫不遵守robots协议。
所有有了保护自己内容不让别人抓取的反爬虫需求
--------------------------反爬虫方法
1、手工识别和拒绝爬虫的访问
2、通过识别爬虫的User-Agent信息来拒绝爬虫
3、通过网站流量统计系统和日志分析来识别爬虫
4、网站的实时反爬虫防火墙实现
5、通过JS算法,文字经过一定转换后才显示出来,容易被破解。某技术网站采用了这种方法
6、通过CSS隐藏技术,可见的页面样式和html里DIV结构不同,增加了爬虫的难度,同时增加自己的维护难度。
技术网站采用了这种方法
7、通过JS不让用户复制,这对非专业人员有效,对技术人员/工程师来说,没有任何效果。不少网站采用。
8、通过flash等插件技术(会被破解,同时对用户不友好,有流失用户的可能性)。早期网站用得多,移动互联网来后,这种方式对用户不友好,少有专业网站采用了。
9、图片化
A:将文字图片化,增加了维护成本,和移动端的可读性
B:将标点符号图片化,再适当增加CSS混淆,这是一种较好的办法,不影响搜索引擎收录,不影响用户使用。但影响爬虫,是一种较好的反爬虫方式,某著名的文学网站采用了这种方法
10、交给专业反爬虫公司来处理
流程
1反爬虫混淆设计器 ---->产生反爬虫混淆素材
2混淆素材--->将服务器端文字变成不可阅读文字
3网络传输--->不可阅读文字+混淆素材
4浏览器-->绘制阶段显示可读文字
5浏览者能看见内容
但是无能有效复制,无法通过底层协议抓取
6混淆算法随时改变,只需要放入新素材就可以了,不需要工程师参与。
特点
依靠文字矩阵变换来提高蜘蛛爬虫软件抓取的代价.
由发布人员,而不是技术人员来更新混淆算法
保护方:内容保护的方法素材易复制,易部署和运营
抓取/窃取方:面对对方快速变化,增加了成本
爬虫与反爬虫与反反爬虫简介
一.基本概念简介
1.爬虫:
自动获取网站数据的程序,关键是批量的获取。
2.反爬虫:
使用技术手段防止爬虫程序的方法。
3.误伤:
反爬技术将普通用户识别为爬虫,如果误伤过高,效果再好也不能用。(如局域网【学校,网吧等】可能用的是同一个ip,如果有人写了一个爬虫,把ip封了,可能损失很多用户。还有可能ip动态分配,重启路由器ip很有可能切换,而被禁的ip有可能在其他用户那儿。)
4.拦截:
成功拦截爬虫,一般拦截率越高,误伤率越高。
二.反爬虫的目的
1.初级爬虫:
简单暴力,不管服务器压力,容易弄垮网站。
2.数据保护:
保护数据不被窃取。
3.失控爬虫:
由于某些情况忘记或无法关闭的爬虫。
4.商业竞争对手:
行业间竞争窃取数据。
三.爬虫与反爬虫对抗过程
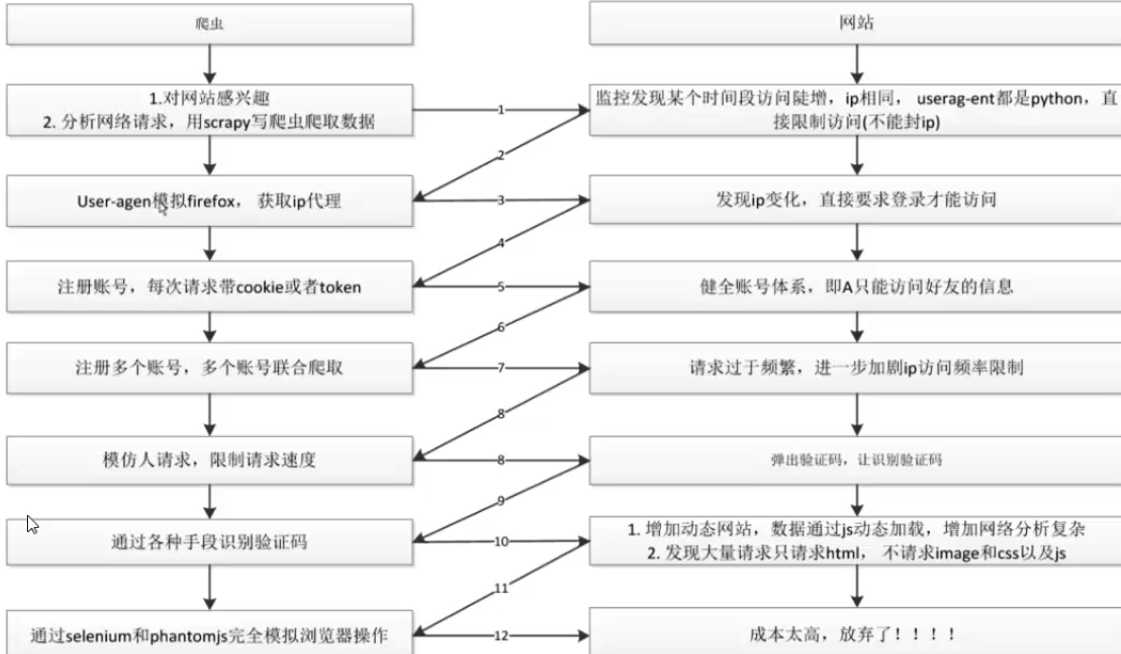
以上是关于反反爬虫的技术手段都有哪些?的主要内容,如果未能解决你的问题,请参考以下文章