Alluxio简介
Posted lipeng_bigdata
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Alluxio简介相关的知识,希望对你有一定的参考价值。
一、Alluxio是什么?
Alluxio是一个基于内存的分布式文件系统,它是架构在底层分布式文件系统和上层分布式计算框架之间的一个中间件,主要职责是以文件形式在内存或其它存储设施中提供数据的存取服务。
Alluxio的前身为Tachyon。
二、Alluxio应用场景
Alluxio居于传统大数据存储(如:Amazon S3,Apache HDFS和OpenStack Swift等)和大数据计算框架(如Spark,Hadoop Mapreduce)之间,如下图所示:
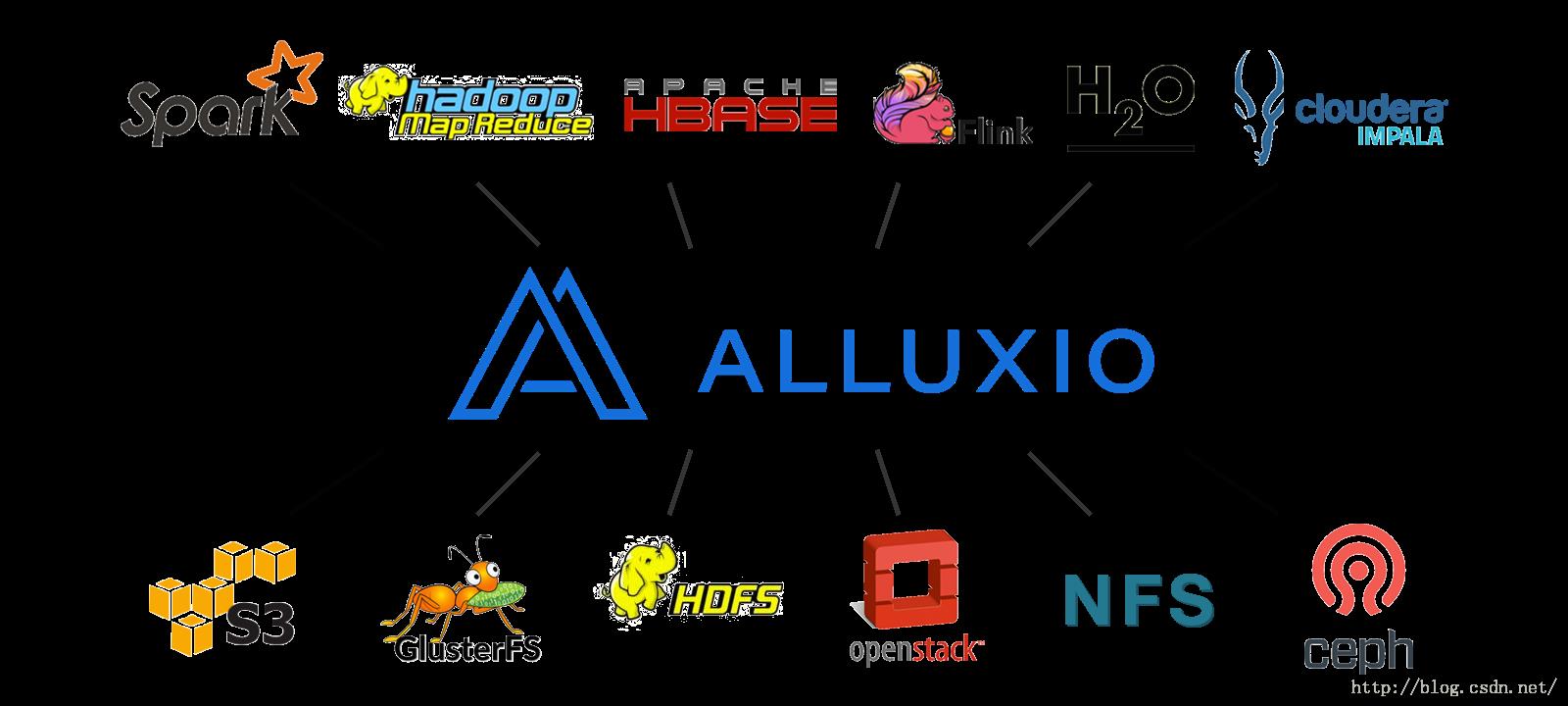
在大数据领域,最底层的是分布式文件系统,如Amazon S3、Apache HDFS等,而较高层的应用则是一些分布式计算框架,如Spark、MapReduce、HBase、Flink等,这些分布式框架,往往都是直接从分布式文件系统中读写数据,效率比较低,性能消耗比较大。而如果我们将其架构与底层分布式文件系统与上层分布式计算框架之间,以文件的形式在内存中对外提供读写访问服务的话,那么Alluxio可以为那些大数据应用提供一个数量级的加速,而且它只要提供通用的数据访问接口,就能很方便的切换底层分布式文件系统。
三、Alluxio系统架构
与其他诸如HDFS、HBase、Spark等大数据相关框架一致,Alluxio也是一个主从结构的系统。它的主节点为Master,负责管理全局的文件系统元数据,比如文件系统树等,而从节点为Worker,负责管理本节点数据存储服务。另外,Alluxio还有一个组件为Client,为用户提供统一的文件存取服务接口。
当应用程序需要访问Alluxio时,通过客户端先与主节点Master通讯,或许对应文件的元数据,然后再和对应Worker节点通讯,进行实际的文件存取操作。所有的Worker会周期性地发送心跳给Master,维护文件系统元数据信息和确保自己被Master感知扔在集群中正常提供服务,而Master不会主动发起与其他组件的通信,它只是以回复请求的方式与其他组件进行通信。这与HDFS、HBase等分布式系统设计模式是一致的。
以上是关于Alluxio简介的主要内容,如果未能解决你的问题,请参考以下文章
Presto Iceberg 数据源 + Alluxio 使用以及最新进展介绍
云知声 Atlas 超算平台: 基于 Fluid + Alluxio 的计算加速实践