Presto Iceberg 数据源 + Alluxio 使用以及最新进展介绍
Posted 过往记忆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Presto Iceberg 数据源 + Alluxio 使用以及最新进展介绍相关的知识,希望对你有一定的参考价值。
本文来自 Alluxio 在2021年11月27日举办的 《【Iceberg + Alluxio】助力加速数据通道》在线会议。分享者为王北南和shouwei chen。本次分享主要分两部分:
•Alluxio 和 Iceberg 的简介;•Presto Iceberg 数据源 + Alluxio 使用介绍以及最新进展介绍。
本文主要介绍第二部分 Presto Iceberg 数据源 + Alluxio 使用介绍以及最新进展介绍,是由北南大佬的分享。本次分享的视频如下:(完整的视频请过往记忆大数据次条)
我们来进入正题:

下面是在 Presto 里面创建 Iceberg 表的使用方法,可以看出,其语法和创建 Hive 表很类似,因为 Presto Iceberg 数据源的实现很多都是参照 Hive 数据源写的。在创建 Iceberg 表的时候可以指定数据的存储格式,以及分区字段。目前 Presto Iceberg 数据源只支持 Parquet 和 ORC 两种格式。
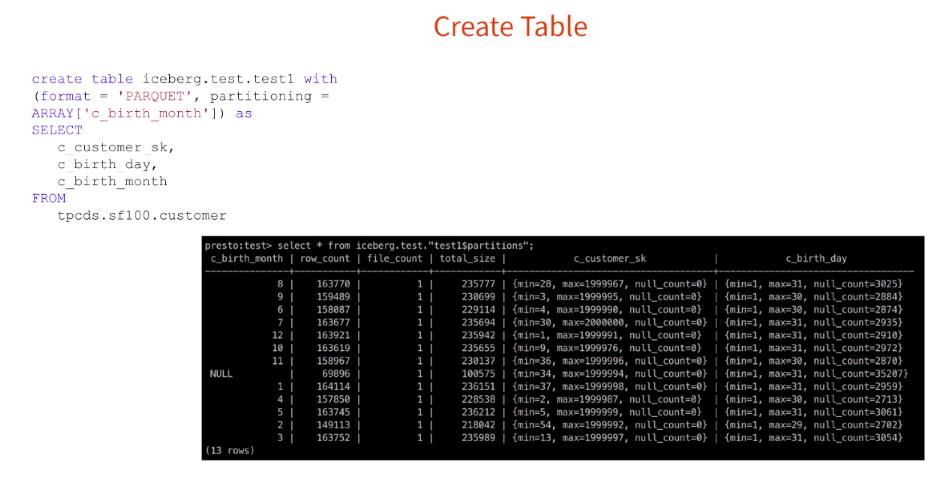
数据写完之后,我们可以通过在表名后面加上 $partitions 就可以看到表的所有分区。比如上面的 select * from iceberg.test.test1$partitions,从上面的输出可以看出,输出的信息可以看到每个分区的行数、文件数、文件大小以及每列在每个分区里面的最大最小值等信息。

创建完表之后,我们还可以往里面插入数据,比如这里插入的数据分区为13(这里分区字段是月,这里只是为了测试,并未实际的业务含义)。我们可以看到 Iceberg 表的数据目录多了一个c_birth_month=13的目录,这个就是我们刚刚插入的数据分区,而且还多了一个快照。

从上图可以看出,我们可以查出刚刚插入的数据。另外,因为 Iceberg 支持时间旅行的概念,我们可以在 Presto 里面的表名后面加上快照ID就可以查到对应快照里面的数据。比如上面的 c_birth_month=13 是在 3499457625195057930 这个快照里面,所以可以查到刚刚插入的数据。
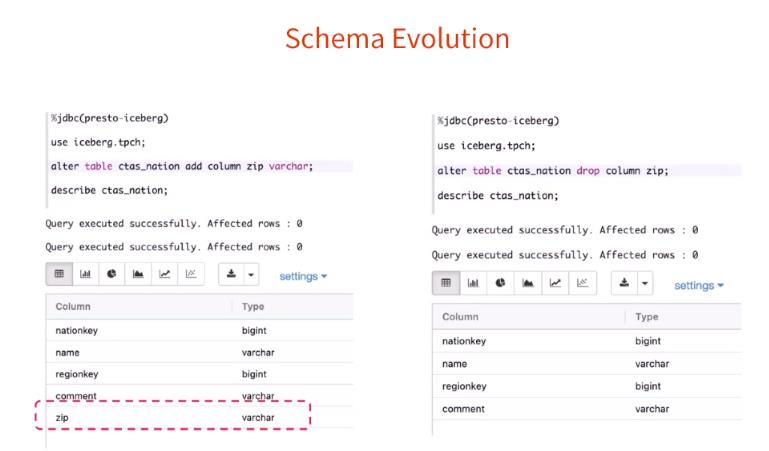
Iceberg 还支持模式演进,也就是可以修改表的列信息,比如增减列,同时可以正常查询表里面的数据。

下面我们来介绍一下 Presto Iceberg 数据源的最新更新。主要为以下四个地方:

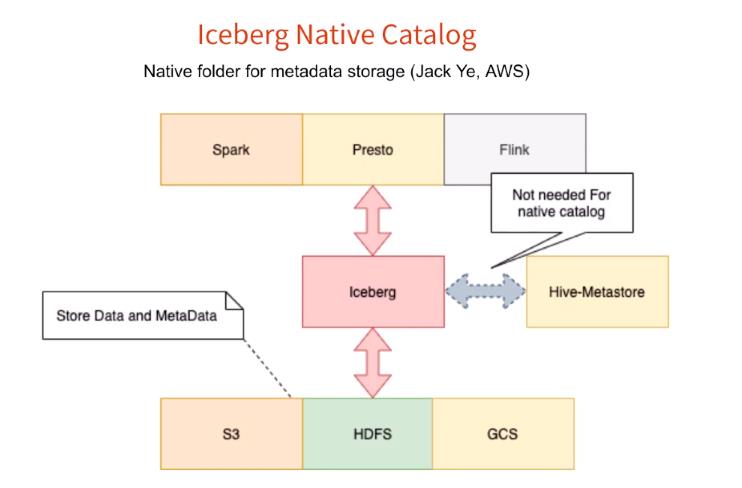
目前 Spark、Presto 等计算引擎从 Iceberg 数据源查询数据的时候还是需要从 Hive MetaStore 获取相关的元数据,然后再读取数据。但是我们都知道,Iceberg 其实自带了元数据,那我们为啥不直接从 Iceberg 里面拿?这个 AWS 的 Jack 给我们带来了这个功能,架构如下:
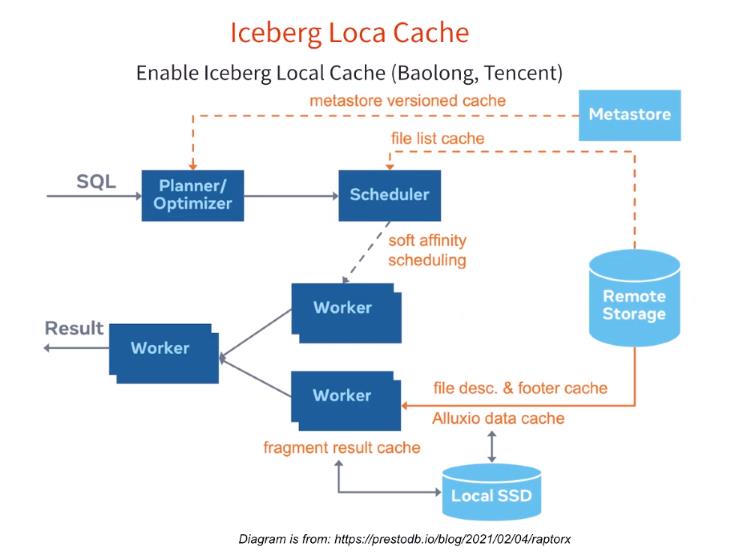
第二个功能是 Iceberg Local Cache ,其实这部分代码大部分是参考 Hive 数据源的 Alluxio Local Cache 功能,毕竟 Iceberg 数据源大部分代码和 Hive 数据源类似。
第三个功能是过滤下推,这个可以大大减少数据的扫描。
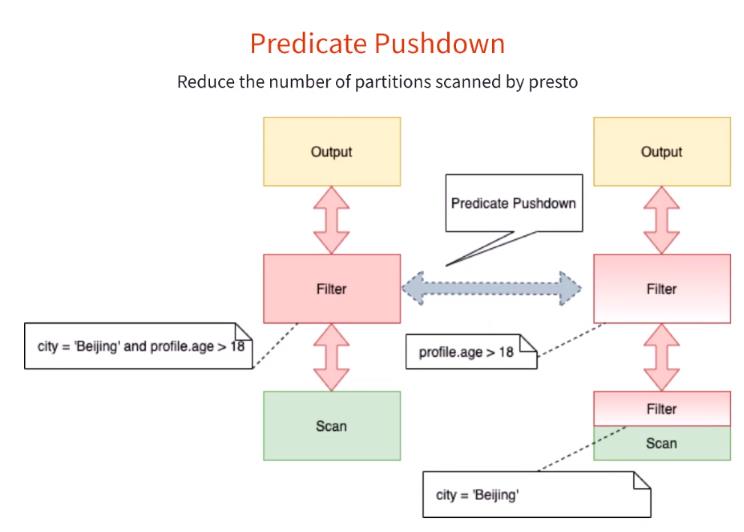
比如上面 city 是分区字段,在查询的时候直接把这个字符下推到 Iceberg 数据源,这样可以大大减少数据的扫描。

上面左图在未开启过滤下推时需要扫描200W行数据,而开启了过滤下推之后,只需要扫描一行数据。这个对性能提升还是有很大的帮助。

上面三个功能是正在做的,大家可以到社区关注最新的状况。
以上是关于Presto Iceberg 数据源 + Alluxio 使用以及最新进展介绍的主要内容,如果未能解决你的问题,请参考以下文章
数据湖(二十):Flink兼容Iceberg目前不足和Iceberg与Hudi对比