:深度学习概述应用学习路线和框架选择
Posted 快乐江湖
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了:深度学习概述应用学习路线和框架选择相关的知识,希望对你有一定的参考价值。
文章目录
一:基本概念
注意:
- 本节内容在前文中已有叙述,因此概念不再做重复,只从具体例子出发解释说明
- 有些概念介绍的可能没有那么准确和详细,会在后续文章中继续补充
(1)神经网络
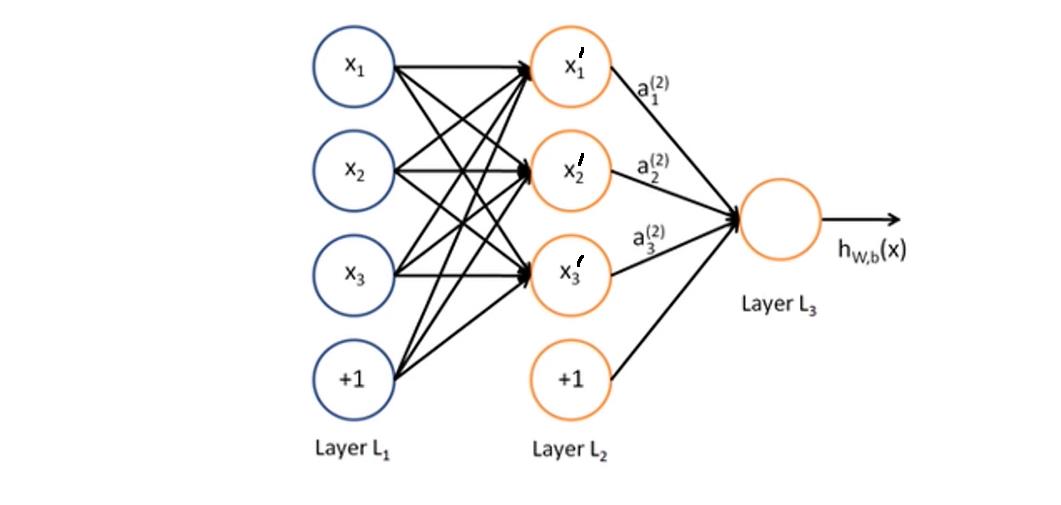
- 如下图是一个简单的人工神经网络,从左至右依次为输入层、隐藏层和输出层,图中的每一个圆圈为人工神经元
- 每个神经元可以接受一个或多个输入,并对输入的线性加权(连线表示权重)进行非线性运算以产生输出。例如下图中, x 1 ‘ = f ( x 1 , x 2 , x 3 , 1 ) x_1^`=f(x_1, x_2, x_3, 1) x1‘=f(x1,x2,x3,1),通常表示为 y = w x + b y=wx+b y=wx+b, b b b称之为偏置项
- 神经网络在训练时,会进行逐层运算,每一层的输出将作为下一层的输入。每相邻两层之间是一个函数关系,多层之间可视为复合函数关系
- 神经网络最后需要求解出 y = w x + b y=wx+b y=wx+b中的 w w w和 b b b,因此需要借助链式法则求解梯度,然后进行反向传播
(2)感知器
- 上图中 x 1 ‘ x_1^` x1‘与 x 1 x_1 x1、 x 2 x_2 x2、 x 3 x_3 x3和偏置项构成一个感知器,可以看出输入层和隐藏层包含多个感知器,所以神经网络也可以称之为由多层感知器所构成网络结构
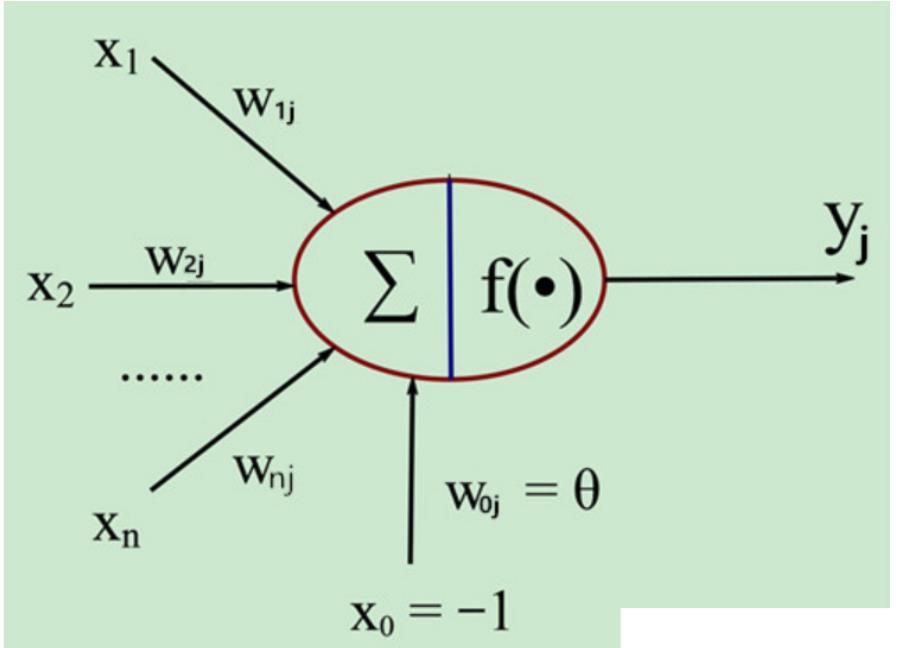
- 如下图为感知器模型,其激活函数为神经网络赋予了非线性特性
- 输出可写为: y = ϕ ( ∑ i = 0 N w i x i − θ j ) y=\\phi(\\sum\\limits_i=0^Nw_ix_i-\\theta_j) y=ϕ(i=0∑Nwixi−θj),其中 x 0 x_0 x0通常被赋值为 + 1 +1 +1,此时 w 0 w_0 w0为偏置项 b b b
- 激活函数通常会被设为连续且有界的非线性增函数
(3)深度学习
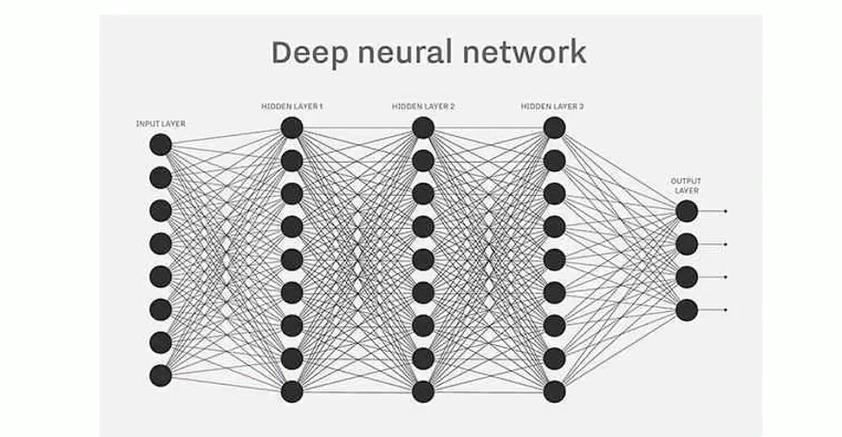
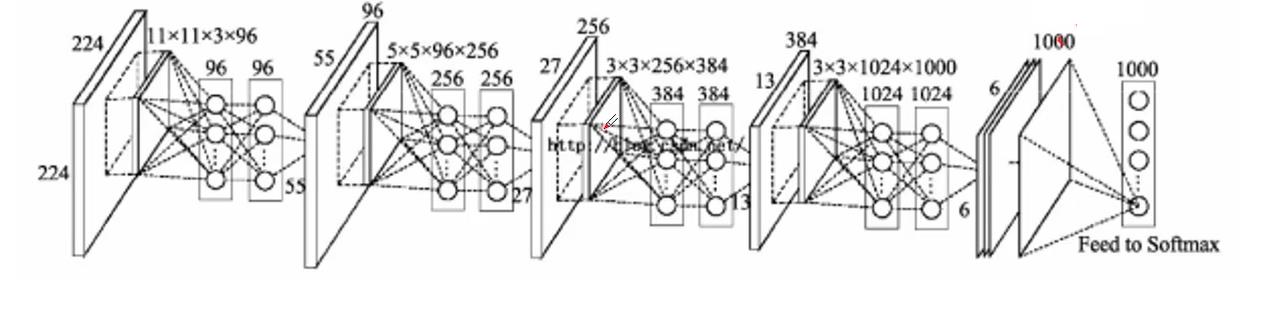
- 神经网络由多层感知器构成,而深度学习可以看成添加了多个隐藏层的多层感知器
- 当网络结构不同时就会形成不同的深度学习模型,例如DNN、CNN、RNN等,就可以应用在不同的领域
(4)前向运算和反向传播
-
前向运算:在已知参数的前提下,计算输出值的过程
-
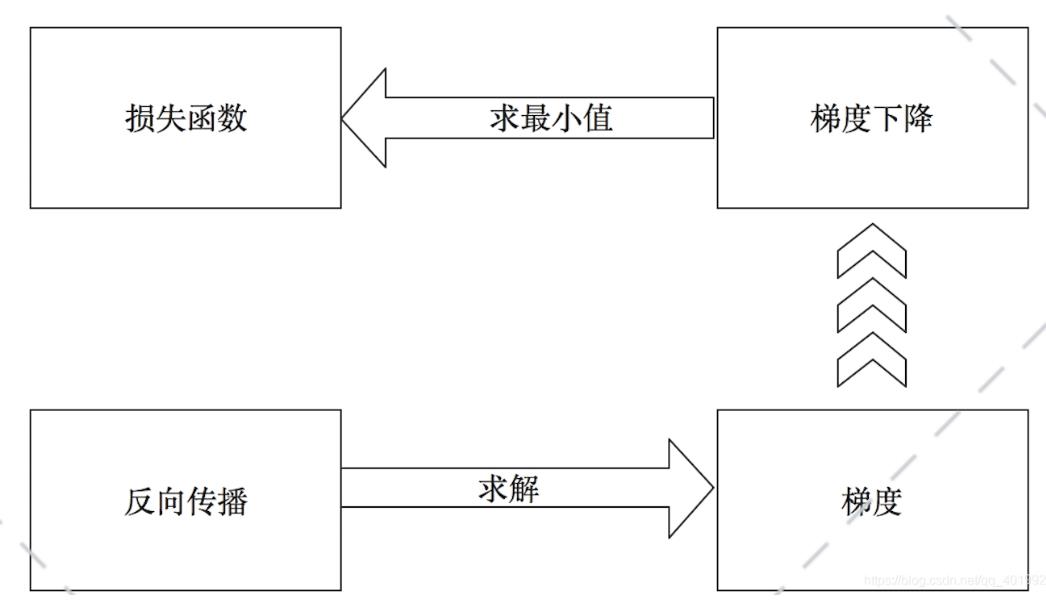
反向传播(BP算法):通过计算输出层结果与真实值之间的偏差来进行逐层调节参数。具体来说,反向传播是求解梯度的一种方法,梯度下降是找损失函数极小值的一种方法
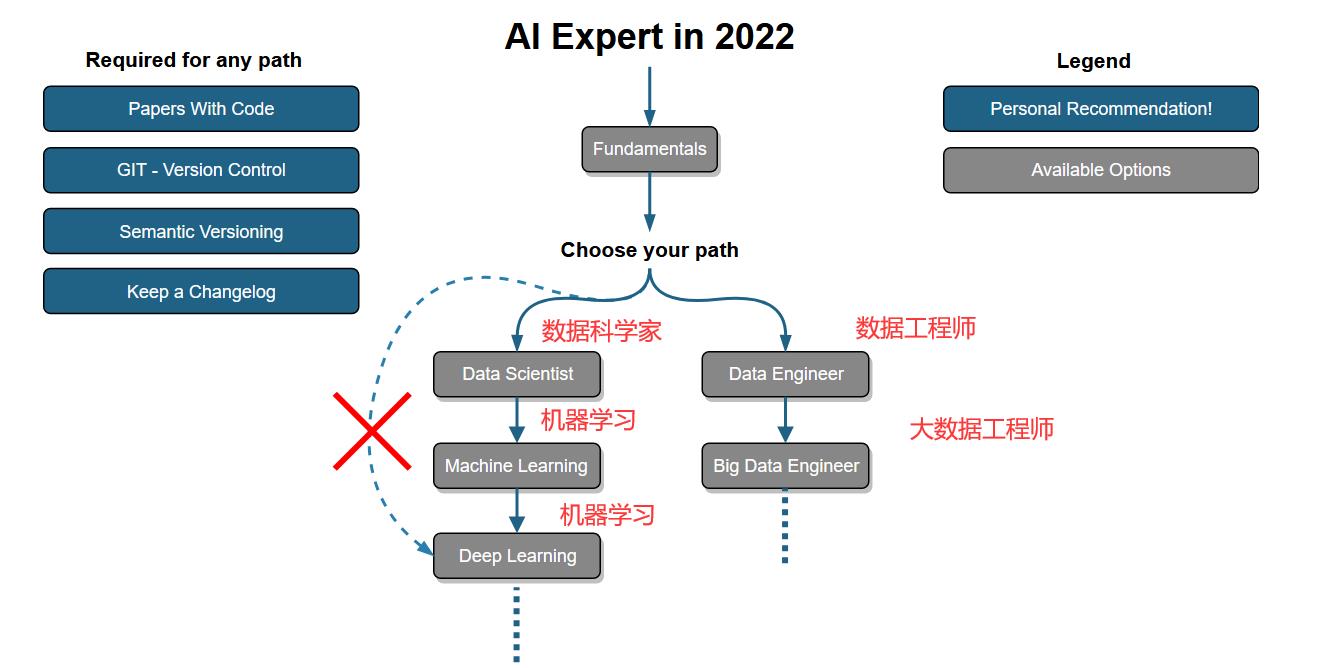
二:DeepLearning学习路线
- 这是一个github项目:项目地址
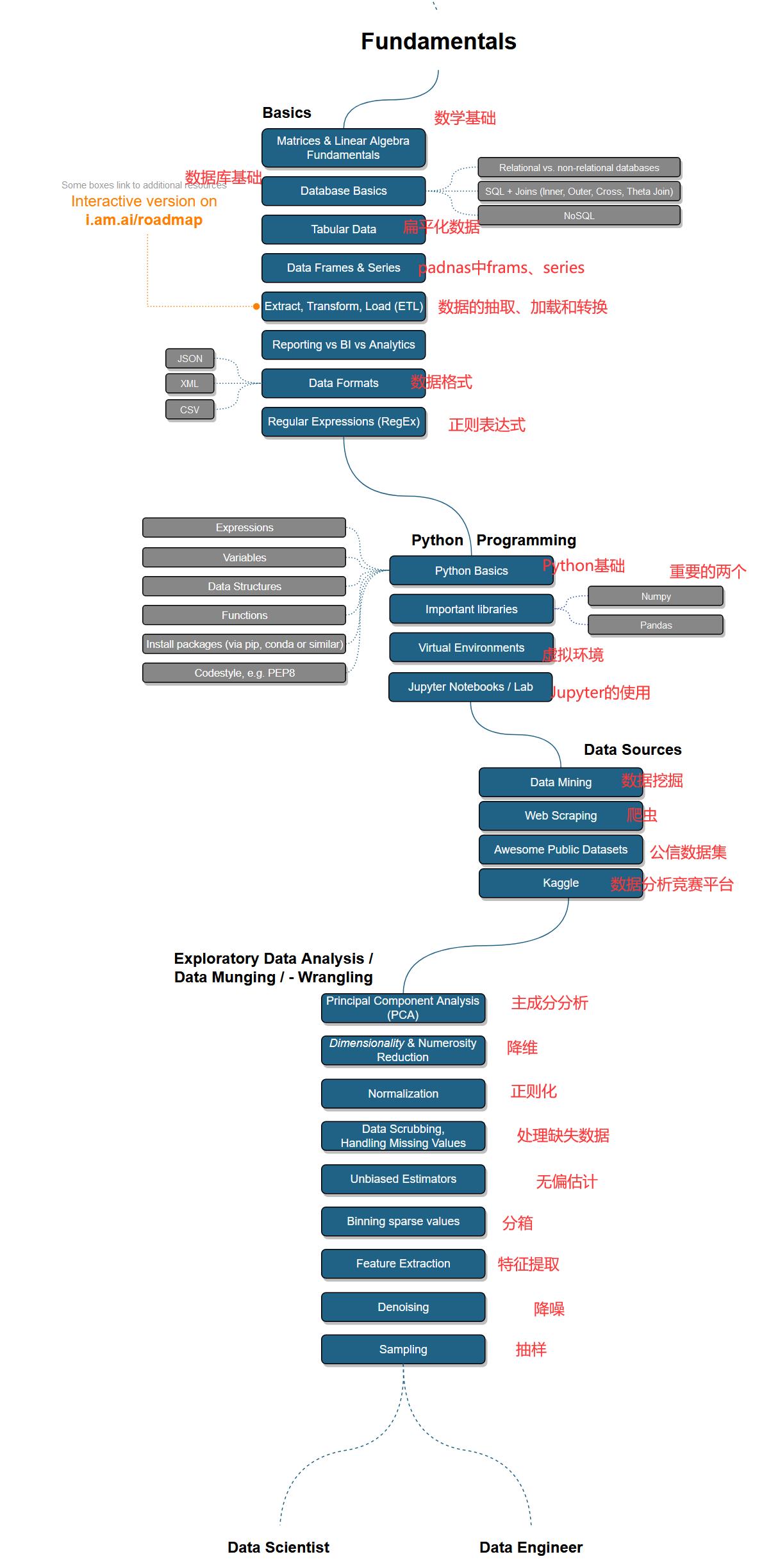
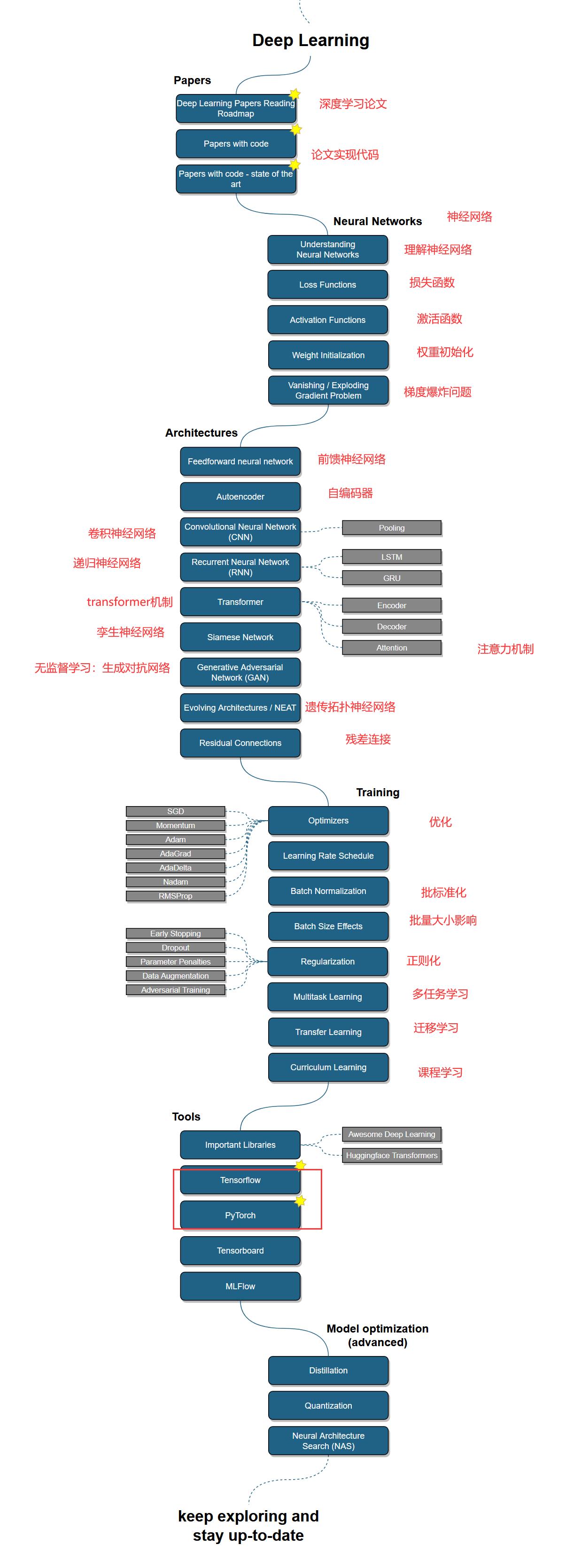
下图是人工智能学习路线的概述,学习完基础后,在了解一些简单的数据处理和机器学习的内容后就可以进入深度学习了,后续学习过程中如果遇到不懂的点随时补充即可
基础部分
深度学习部分
三:深度学习应用
(1)生活领域
- Speech Recognition(语音识别):例如自动字幕
- Image Recognition(图像识别):例如人脸识别
- Automatic Languate Translation(翻译):例如谷歌翻译就基于RNN
- Medical Diagnosis(医疗诊断):例如CT
- Stock Market Trading(股票市场):例如量化交易
- Online Fraud Detection(欺诈检测):例如如钓鱼网站检测
- Virtual Personal Assistant(语音助理):例如Siri等
- Self Driving Cars(自动驾驶):例如特斯拉(主要是图像识别)
- Product Recommendations(推荐系统):例如商品、信息、咨询推荐
- …
(2)深度聚类
深度聚类:传统聚类算法最大的一个瓶颈就是难以处理高维数据,虽然有很多降维方法可以使用,但所采用的降维技术大多无法揭示数据的潜在结构,而且聚类和降维彼此独立,导致降维后特征不是和聚类。有别于传统聚类算法,深度聚类是一种在聚类过程中结合了深度学习技术的聚类算法,现有深度聚类方法主要分为如下两类
- 顺序深度聚类方法:该类方法特点是表征学习与聚类过程彼此独立,首先利用深度神经网络提取表征,然后将传统聚类算法应用于深度表征,得到聚类结果。其缺点是表征学习的过程缺乏聚类相关的先验知识作为指导,导致学习到的特征不适合聚类
- 联合深度聚类方法(更优):通过定义一个联合损失函数,在表征学习的过程中融入聚类思想,对表征进行调整,使之容易聚类
在联合深度聚类方法中,基于网格结构可以将其划分如下深度聚类算法
- 基于自编码器的深度聚类:自编码器(Autoencoder) 由一个编码器和一个解码器组成。编码器将输人信息x映射为潜在空间中的一个潜在表示z。训练时,解码器根据潜在表示z对输入信息进行重构,目的是使输人样本与重构后的样本尽可能相似
- 基于变分自编码器的深度聚类:
- 基于生成对抗网络的深度聚类(GAN):生成对抗网络(GAN) 由一个生成网络G与一个判别网络D组成,生成网络的输出要尽可能模仿训练集中的真实样本,判别网络以真实样本或生成网络的输出作为输人,其目标是对二者进行区分。两个网络不断对抗,调整各自参数,直到判别网络无法判断生成网络的输出是否真实
- 基于图神经网络的深度聚类:
四:https://paperswithcode.com/
这是一个非常出名的深度学习网站,如果你有以下需求时就可以访问它
- 某一个研究方向下,有哪些算法模型可以用?不同算法之间效果对比如何?
- 某一个研究方向下,目前效果最好的算法是哪个?
- 某一个研究方向下,有哪些数据集可以选择?从哪儿下载?
- 深度学习算法模型中,有哪些方法?有哪些结构?
五:TensorFlow和Pytorch的选择
注意
-
如果是工程师,应该优先选TensorFlow2:在工业界最重要的是模型落地,目前国内的大部分互联网企业只支持TensorFlow模型的在线部署,不支持Pytorch
-
如果是学生或者研究人员,应该优先选择Pytorch:研究人员最重要的是快速迭代发表文章,需要尝试一些较新的模型架构。而Pytorch在易用性上相比TensorFlow2有一些优势,更加方便调试
-
如果时间足够,最好TensorFlow2和Pytorch都要学习掌握
这里我们选择Pytorch,便于学习,相较于其它框架它的优点有
-
简洁:PyTorch的设计追求最少的封装,尽量避免重复造轮子。不像TensorFlow中充斥着session、graph、operation、name_scope、variable、tensor、layer等全新的概念,PyTorch的设计遵循tensor→variable(autograd)→nn.Module 三个由低到高的抽象层次,分别代表高维数组(张量)、自动求导(变量)和神经网络(层/模块),而且这三个抽象之间联系紧密,可以同时进行修改和操作。简洁的设计带来的另外一个好处就是代码易于理解。PyTorch的源码只有TensorFlow的十分之一左右,更少的抽象、更直观的设计使得PyTorch的源码十分易于阅读。在笔者眼里,PyTorch的源码甚至比许多框架的文档更容易理解。
-
速度:PyTorch的灵活性不以速度为代价,在许多评测中,PyTorch的速度表现胜过TensorFlow和Keras等框架 。框架的运行速度和程序员的编码水平有极大关系,但同样的算法,使用PyTorch实现的那个更有可能快过用其他框架实现的。
-
易用:PyTorch是所有的框架中面向对象设计的最优雅的一个。PyTorch的面向对象的接口设计来源于Torch,而Torch的接口设计以灵活易用而著称,Keras作者最初就是受Torch的启发才开发了Keras。PyTorch继承了Torch的衣钵,尤其是API的设计和模块的接口都与Torch高度一致。PyTorch的设计最符合人们的思维,它让用户尽可能地专注于实现自己的想法,即所思即所得,不需要考虑太多关于框架本身的束缚。
-
活跃的社区:PyTorch提供了完整的文档,循序渐进的指南,作者亲自维护的论坛 供用户交流和求教问题。Facebook 人工智能研究院对PyTorch提供了强力支持,作为当今排名前三的深度学习研究机构,FAIR的支持足以确保PyTorch获得持续的开发更新,不至于像许多由个人开发的框架那样昙花一现
六:深度学习项目一般流程
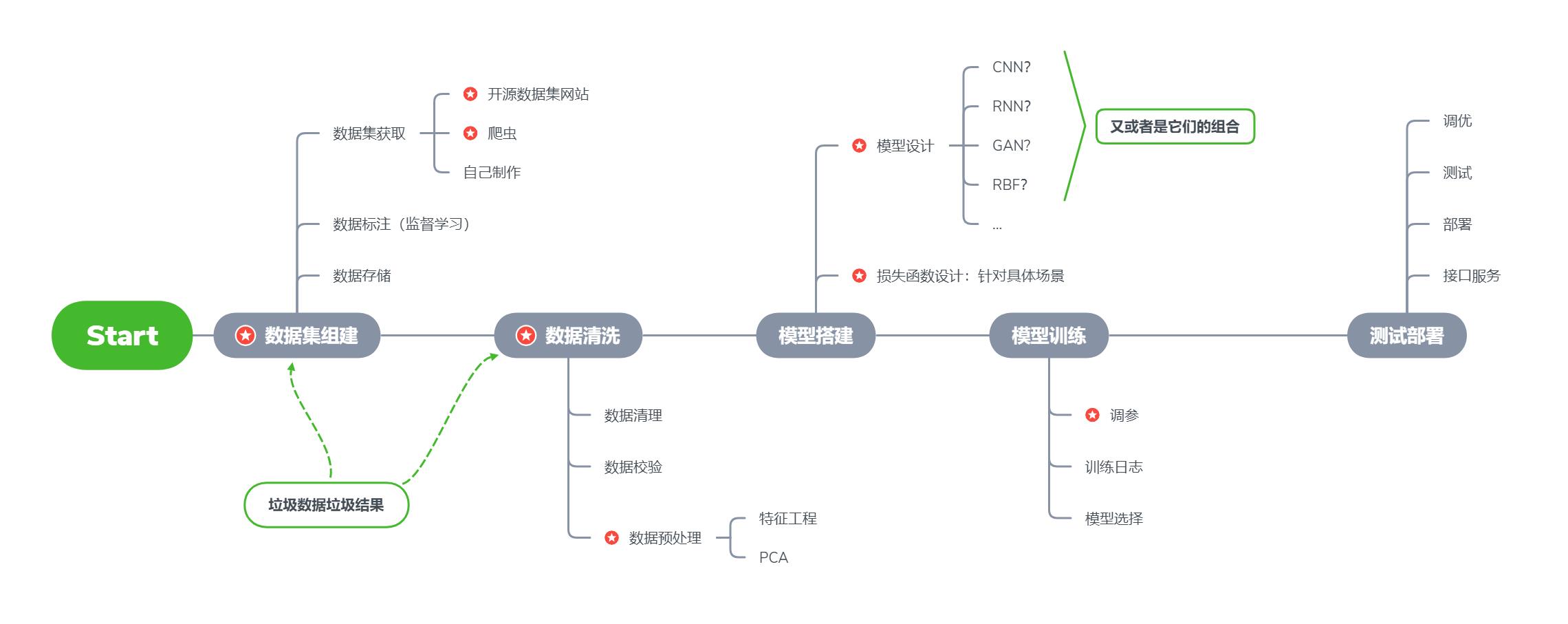
以上是关于:深度学习概述应用学习路线和框架选择的主要内容,如果未能解决你的问题,请参考以下文章
Nature子刊:一个从大脑结构中识别阿尔茨海默病维度表征的深度学习框架