看过来,这里有最前沿的开源深度学习框架
Posted 原力大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了看过来,这里有最前沿的开源深度学习框架相关的知识,希望对你有一定的参考价值。
本文选自CIO
原力大数据编译
深度学习是机器学习中一种基于对数据进行表征学习的方法,其目的在于建立模拟人脑进行分析学习的神经网络,它通过模仿人脑的机制来解释图像,声音和文本数据。深度学习的优势在于使用非监督或半监督学习的方法进行特征提取来替代费时费力的手动提取。
过去一年,Google、Facebook、Microsoft等互联网巨头纷纷选择在深度学习领域投资新项目,甚至还出现了一些由埃隆·马斯克和彼得·蒂尔等投资人支持的非盈利性研究实验室。深度学习已然成为行业大佬们关注的焦点。

开源的深度学习神经网络逐渐发展成熟,目前有多个开源的深度学习网络框架可以在机器学习和人工智能领域提供个性化解决方案。
本文通过比较各深度学习网络框架的优缺点,并结合不同的业务发展需求,为大家选择深度学习框架提供一个参考。
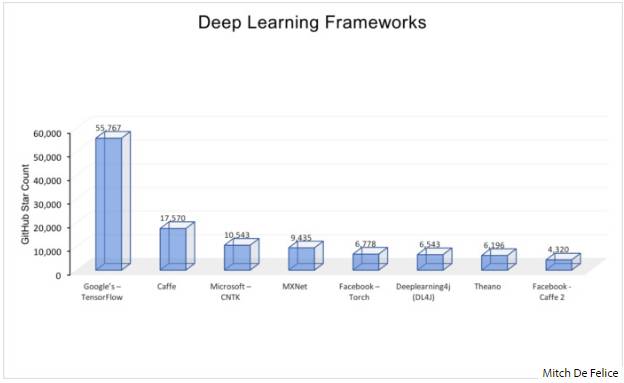
下图是在GitHub上流行的开源深度学习网络框架的排名。截止到2017年5月初,GitHub上各大框架的收藏数得出以下排名。
TensorFlow
TensorFlow作为谷歌大脑(Google Brain)项目的一部分,由早期的DistBelief V2库发展而来。当谷歌决定开源TensorFlow时,立即吸引了大量开发爱好者。
TensorFlow可提供一系列功能,如图像、手写、语音识别、预测和自然语言处理。 2015年11月9日,TensorFlow根据Apache 2.0开源许可发布。
2017年2月15日,TensorFlow 发布了1.0版本。此版本是在先前八个版本的基础上优化改进的,它解决了TensorFlow之前存在的性能不完整的问题,并完善了一些核心功能。TensorFlow能成功的原因可归结如下:
TensorFlow提供了以下工具:
TensorBoard是一个设计良好的可视化工具,可用于网络建模和性能测试。
TensorFlow Serving可以保持相同的服务器结构体系和API,使得部署新的算法和实验变得轻松。TensorFlow Serving提供了与TensorFlow模型即开即用的整合,同时还能轻松扩展到其他类型的模型和数据。
TensorFlow编程接口支持Python和C ++。1.0版本的公告显示,TensorFlow还将支持Java、GO、R和Haskell API的alpha版本。此外,TensorFlow还可以在谷歌云和亚马逊云中运行。
TensorFlow 0.12版本支持win7、 win10和 win server2016。由于TensorFlow使用C ++ Eigen库,所以可以在ARM架构上进行编译和优化。这意味着您可以在各种服务器或移动设备上部署训练模型,而无需执行单独的模型解码器或加载Python解释器。
TensorFlow支持细粒度的网络层,子图处理允许您在图的任何边缘引入和恢复数据结果,这对于调试复杂的计算图十分有帮助。
分布式TensorFlow引入了0.8版本,允许模型并行,这意味着模型的不同部分可以在不同的设备上并行训练。
截至2016年3月,斯坦福大学、伯克利学院、多伦多大学和Udacity都将该框架作为一个免费在线课程进行教授。
TensorFlow的缺点是:
TensorFlow中的每个计算流都必须构造为静态图,并且缺少符号性循环,这使得一些计算变得困难。
缺少对视频识别很有帮助的三维卷积。
即使TensorFlow比初始版本(v0.5)快了58倍,但在执行性能方面仍落后于竞争对手。
链接:https://www.tensorflow.org/
Caffe
Caffe是现Facebook AI平台首席工程师贾杨清的杰作。Caffe可能是自2013年底以来第一个主流的行业级深度学习工具包。
优良的卷积模型使其成为机器视觉领域最受欢迎的工具包之一,并在2014年ImageNet挑战赛中拔得头筹。Caffe遵循 BSD第2协议许可下发布。
Caffe的快速使其成为实验研究和商业化应用的完美选择。Caffe每天可在英伟达单个 K40 GPU上处理超过6000万张图片,可达到1 毫秒完成一张图像推理和4毫秒完成一张图像学习的程度,越新的版本处理速度越快。
Caffe基于C ++,可以在各种设备上进行编译,而且是跨平台运行的,包含Windows端口。 Caffe支持C++、Matlab和Python编程接口,拥有一个庞大的用户社区,为其深度网络库(“Model Zoo”)做贡献。AlexNet和GoogleNet就是社群用户构建起的两个流行网络。
虽然Caffe是一款在视觉识别领域流行的深度学习网络,但是,它不像TensorFlow、CNTK和Theano那样支持细粒度网络层。构建复杂层必须用低级语言完成。由于其遗留的架构,Caffee对常规网络和语言建模的支持总体而言很差。
链接:http://caffe.berkeleyvision.org/
Caffe 2
Caffe 2是Facebook的贾杨青和他的团队正在开发的新一代框架。今年4月18日,Facebook根据BSD协议许可开源了Caffe 2。
那么Caffe 2与Caffe区别在哪呢?Caffe 2更侧重于模块化和移动端大规模部署。同TensorFlow一样,Caffe 2使用C ++ Eigen库来支持ARM架构。
Caffe模型可以轻松地转换为具有实用程序脚本的Caffe 2模型。 Caffe的设计方案使其成为处理视觉类型问题的理想选择。
Caffe 2延续了Caffe在处理视觉类型问题上的优势,并且增加了对自然语言处理,手写识别和时间序列预测有帮助的递归神经网络(RNN)和长期记忆网络(LSTM)支持。
期待Caffe 2在不久的将来会超越Caffe,在深度学习领域中被广泛认可。
链接:https://caffe2.ai/docs/caffe-migration.html
CNTK
Microsoft Cognitive Toolkit(CNTK)是微软的深度学习神经网络工具包,最初是为了加强语音识别而开发的。
CNTK支持RNN和CNN类型的神经网络模型,使其成为处理图像,手写和语音识别问题的良好选择。 CNTK支持64位的Linux和Windows系统,并依据MIT的许可发布。
CNTK与TensorFlow和Theano的组成相似,使用向量运算符的符号图网络,支持矩阵加/乘或卷积等向量操作。
此外,同TensorFlow和Theano一样,CNTK允许构建细粒度的网络层。构建块(操作)的细粒度允许用户不需要使用低级语言就能创建新的复杂层类型。
CNTK同Caffe一样基于C ++结构,支持跨平台的CPU / GPU部署。 CNTK在AzureGPU Lab展现出最高效的分布式计算性能。目前,CNTK缺乏对 ARM架构的支持限制了其在移动设备上的功能实现。
链接:https://github.com/Microsoft/CNTK/wiki
MXNet
MXNet(发音为“mix-net”)起源于卡内基梅隆大学和华盛顿大学,是一个功能齐全,可编程和可扩展的深度学习框架,支持最先进的深度学习模型。
MXNet支持混合编程模式(命令式和声明式)和多种编程语言代码(Python、C ++、R、Scala、Julia、Matlab和javascript)。 2017年1月30日,MXNet已被纳入Apache Incubator开源项目。
MXNet支持深度学习架构,如卷积神经网络(CNN)、循环神经网络(RNN)和其包含的长短期记忆网络(LTSM)。
该框架在图像,手写和语音识别和预测以及自然语言处理上表现出色。有些人认为MXNet是世界上最好的图像分类器。
MXNet具备强大的可扩展能力,如GPU并行和内存镜像,编程器快速开发和可移植性。此外,MXNet通过与Apache Hadoop YARN(一种通用的分布式应用程序管理框架)集成,使其成为TensorFlow强劲的竞争对手。
MXNet与其他深度学习网络框架最大的区别在于,它是少数支持生成对抗网络(GAN)模型的深层网络框架之一。该模型启发自实验经济学方法的纳什均衡。
早前,亚马逊CTO Werner Vogels曾宣布将MXNet作为亚马逊深度学习的框架。传闻苹果公司在2016年收购Graphlab / Dato / Turi之后也使用MXNet。
链接:http://mxnet.io/
Torch
Torch由Facebook的RonanCollobert和Soumith Chintala,原先在Twitter工作过的Clement Farabet(现任职于英伟达),以及Google Deep Mind的Koray Kavukcuoglu共同开发。
Torch根据BSD 第3条协议获得许可认证。随着Facebook对Caffe 2研究的深入,以及其对移动设备的支持,Torch的地位逐渐被替代。
Torch的编程语言为Lua。 Lua不是主流语言,在开发人员没有熟练掌握Lua之前,使用Torch很难提升开发的整理生产力。
Torch缺少TensorFlow的分布式应用程序管理框架,也缺乏MXNet或Deeplearning4J对YARN的支持。缺乏多种编程语言的API也限制了开发人员。
链接:http://torch.ch/
Deeplearning4J
Deeplearning4J(DL4J)是由Java和Scala编写的,由Apache2.0授权开源的分布式神经网络库。 DL4J最初由SkyMind的Adam Gibson开发,是唯一与Hadoop和Spark集成的协调多个主机线程的商业级深度学习网络。
DL4J使用Map-Reduce来训练网络,同时依靠其他库来执行大型矩阵操作。DL4J框架内置GPU支持,在训练过程中支持YARN。
DL4J支持多种深层网络架构:RBM、DBN、卷积神经网络(CNN)、循环神经网络(RNN)、RNTN和长短期记忆网络(LTSM)。 DL4J还能为Canova的矢量化库提供支持。
DL4J使用Java语言实现,本质上比Python快。在使用多个GPU解决非平凡图像识别任务时与Caffe一样快,在图像识别、欺诈检测和自然语言处理方面表现出色。
链接:https://deeplearning4j.org/
Theano
Theano由蒙特利尔大学算法学习实验室(MILA)维护,该实验室由Theano创始人Yoshua Bengio领导,是深度学习研究领域的重要贡献者,拥有约100名学生和教师。
Theano支持快速开发高效的机器学习算法,根据BSD协议许可发布。Theano支持手写和图像分类等多种卷积类型,例如医学图像,使用三维卷积或三维池进行视频分类。
Theano可以用自然语言处理任务,包括语义理解、翻译和生成。 Theano还支持一个由MILA学生(现在谷歌工作)创建的生成对抗网络(GAN)。
Theano只支持一种编程开发语言,更适宜作为学术研究的工具。然而,缺乏移动平台和其他编程语言的API限制了Theano在企业级应用程序的开发。
链接:http://deeplearning.net/software/theano/
开源VS非开源
随着深度学习的不断成熟,TensorFlow、Caffe 2和MXNet之间的竞争会越来越明显。另一方面,软件供应商开始开发具有人工智能技术的产品,您会购买非开源的还是使用开源框架的人工智能产品?有了开源工具,开发者在决定运用深度学习框架时容易陷入两难的选择。在非开源产品中,你的退出策略是什么?人工智能的收益会随着工具学习能力的进步而提升,看待这些问题都需要用长远的观点。


原力大数据(广州帷策智能科技有限公司)
广州帷策智能科技有限公司致力于大数据研究及应用项目,积累了丰富且深入的大数据实践经验与成果。尤其擅长基于大数据的分析建模、能力固化和产品研发,力求帮助客户透视业务全景,实现量化决策、精准决策和科学决策,高效提升市场营销及运营管理能力。
官网 http://www.wislife.cn
合作联系 020- 85279103
微信 jesich
以上是关于看过来,这里有最前沿的开源深度学习框架的主要内容,如果未能解决你的问题,请参考以下文章