可观测数据采集端的管控方案的简单对比
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了可观测数据采集端的管控方案的简单对比相关的知识,希望对你有一定的参考价值。
概述
当前,主流的日志采集产品除了SLS的ilogtail,还有Elastic Agent、Fluentd、Telegraf、Sysdig、Logkit、Loggie、Flume等。详细的对比结果见下表:
备注:
- 集群监控:表示工具可以查看管理采集端的运行状态、采集速度等数据
- 集群管理:表示工具可以对管理采集端的采集配置、运行参数等进行添加、修改、删除
| ilogtail | Elastic | Logkit | Sysdig | Fluentd | Telegraf | Loggie | Flume | |
| 产品类型 | 企业版 | 企业版 | 开源版 | 企业版 | 开源版 | 开源版 | 开源版 | 开源版 |
| 单机部署 | 支持 | 支持 | 支持 | 支持 | 支持 | 支持 | 支持 | 支持 |
| 集群管理 | 控制台(阿里云)、API、K8s Operator | 控制台(Fleet Server) | Logkit 助手 | 不支持 | 容器下有三方开源的Fluent Operator和Logging Operator,主机下不支持 | 不支持 | Kubernetes下可通过CRD配置,主机下不支持 | 不支持 |
| 集群监控 | 阿里云控制台 | Fleet UI | Logkit助手 | Sysdig Monitor | 通过第三方Prometheus,或REST API | InfluxData Platform | 通过第三方Prometheus | 使用额外的exporter |
可以看到提供完整集群管理能力的,主要是SLS、Elastic、和Logkit,下面会针对Elastic、Logkit做进一步介绍。
Elastic Agent - Fleet 介绍
Fleet 是一个用于管理 Elastic Agent 配置的组件,由两部分组成:Fleet UI 和 Fleet Server。Fleet UI 是一个带有用户界面的 Kibana 应用程序,供用户载入和配置 agent 策略(注: agent 策略类似于SLS的ilogtail采集配置)、管理载入数据以及管理整个环境中的Elastic Agent。
Fleet Server 是 Elastic Stack 的一个后端组件,作为 Elastic Agent 的一部分部署在主机(服务器)上,Elastic Agent连接到该组件,以执行检索 agent 策略、更新和管理等命令。一个 Fleet Server 进程可以支持多个 Elastic Agent 连接,并作为控制平台,用作更新 agent 策略、收集状态信息以及协调多个 Elastic Agent 操作。Fleet Server 需要连接到支持 Elasticsearch 的集群才能运行。
主要功能
Fleet 允许用户集中管理大量Elastic Agent,是管理与 Elastic Agents 通信的基础设施组件。
- 用户可以在 Fleet UI 页面上查看所有Elastic Agent的状态,看到Elastic Agent的在线状态、健康状态、上次注册时间,还可以查看Elastic Agent的二进制文件和 agent 策略的版本。
- 若用户更改了 agent 策略,所有的Elastic Agent都会在下次注册的时候收到更新。
- Fleet Server 会自动为每个Elastic Agent生成 Elasticsearch API 密钥,对正在运行的集群具有最低权限,更好地保护Elastic Agent。
- Fleet Server提供了更新Elastic Agent的控制层,并指示它们执行诸如跨主机运行 OSQuery 或在网络层隔离主机以遏制安全威胁等操作。
- Fleet Server 可以集中部署,也可以部署在专用网络的边缘。
- Elastic提供设计了对Fleet Server的监控功能。
设计
部署模型
Fleet Server有两种部署模型,分别适用Elastic Cloud部署和本地部署。
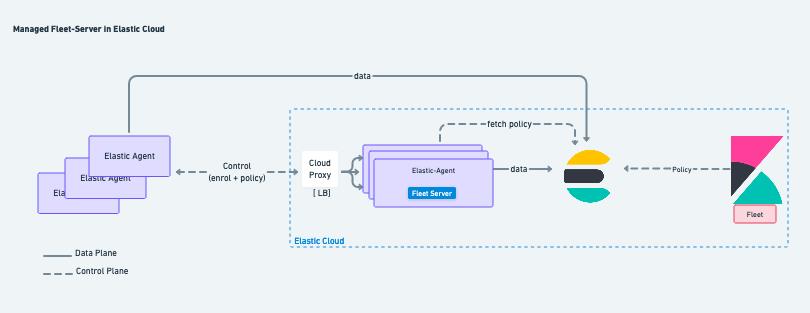
Elastic Cloud部署
在 Elastic Cloud 中配置和托管 Fleet Server,可以简化 Elastic Agent 的部署。在这种情况下,创建部署时,会自动部署一组高度可用的 Fleet Server。
管理员可以选择分配给 Fleet Server 的资源,以及是否希望将 Fleet Server 部署在多个可用区中。
一旦作为服务部署在 Elastic Cloud 上,Fleet Server 的整个生命周期都由 Elastic 管理。Fleet Server 具有可扩展性和高可用性,可在多个实例之间实现流量入口负载平衡,以满足规模要求。
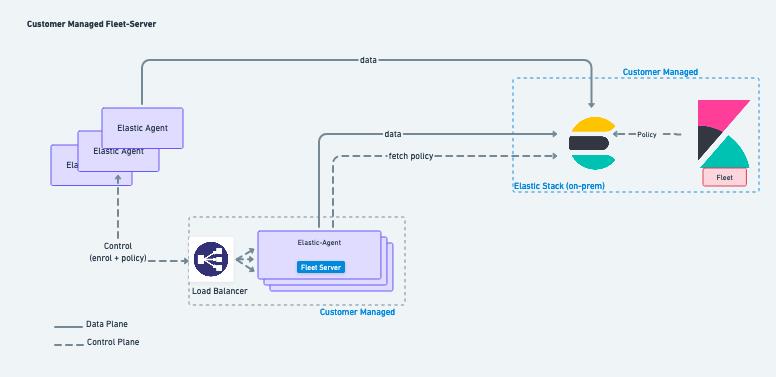
本地部署
Fleet Server 可以在本地部署并由用户管理。在此部署模型中,管理员负责 Fleet Server 部署和生命周期管理。这种操作模式主要用于满足数据处理要求,或用于Elastic Agent只能访问私有分段网络的场景,需要管理员配置 Fleet Server 的多个实例并使用负载均衡器来更好地扩展部署。
高可用性
Fleet Server 是无状态的。因此,只要 Fleet Server 有能力接受更多连接,就可以对 Fleet Server 的连接进行负载均衡。负载均衡是在循环的基础上完成的。
在 Elastic Cloud 部署模型中,会自动预置多个 Fleet Server 以满足所选的实例大小(修改实例大小以满足规模要求),也选择多个可用区来满足容错要求,这些实例也可用于平衡负载。
在本地部署中,Fleet Server 的高可用性、容错性和生命周期管理是管理员的责任。
监控自建的 Fleet Server
对于自建的 Fleet Server,监控是关键,因为 Fleet Server 的运行对于已部署Elastic Agent及其提供的服务的健康状况至关重要。当 Fleet Server 运行不正常时,可能会导致其管理的Elastic Agent的签入、状态信息和更新延迟。Elastic提供设计了对Fleet Server的监控功能。监控数据将告诉用户何时为 Fleet Server 添加容量,并提供错误日志和信息以解决其他问题。对于自我管理的Fleet Server,当用户创建新的 agent 策略或使用现有的 Default Fleet Server 策略时,默认情况下会启用监控。
高度的环境依赖性
Fleet 严重依赖 Elastic 环境,Fleet Server 对于合作的 Elastic 产品有兼容要求。
- Elastic Stack 7.13 或更高版本(在 Elastic Cloud 上托管 Elasticsearch 服务,或自行管理的集群)。
- Elastic Cloud Enterprise 2.9(自行管理 Fleet Server)/ 2.10及以上版本(Elastic Cloud 上使用托管的 Fleet Server)。
通信机制
Elastic Agent 使用 http 协议, 通过 Fleet Server 与 Elasticsearch 通信:
- 在Fleet UI上创建新的 agent 策略后,保存到 Elasticsearch。
- Elastic Agent 使用身份验证生成注册密钥,向 Fleet Server 发送注册 agent 策略请求。
- Fleet Server 接收请求并从 Elasticsearch 获取 agent 策略,然后将 agent 策略发送到所有注册了该 agent 策略的 Elastic Agent。
- Elastic Agent 使用 agent 策略中的配置信息来收集数据并将其发送到 Elasticsearch。
- Elastic Agent 登记录入 Fleet Server 以获取更新,并且保持开放连接。
- 当 agent 策略更新时,Fleet Server 从 Elasticsearch 检索更新的 agent 策略并将其发送到连接的 Elastic Agent。
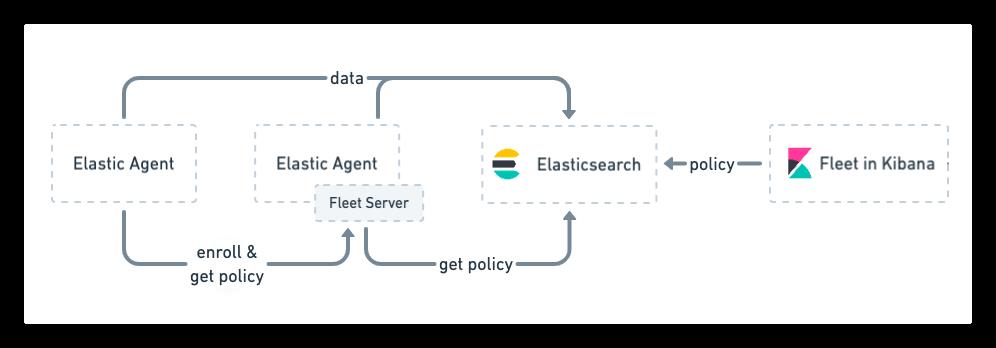
Fleet Server 使用服务令牌与包含fleet-server服务帐户的 Elasticsearch 进行通信。每个 Fleet Server 可以使用自己的服务令牌,并且可以在多个服务器之间共享它(不推荐)。为每个服务器使用单独的令牌的优点是可以分别使每个服务器无效。
配置说明
Elastic Cloud部署
Elastic Cloud 直接托管 Fleet Server ,在不考虑扩展的情况下,不需要额外的设置(使用 Fleet 需要确保部署包含一个集成服务器实例)。可以在Fleet UI上确认集成服务器的可用性。
本地部署
要部署自我管理的 Fleet Server,需要安装 Elastic Agent 并将其注册到包含 Fleet Server 集成的 agent 策略中。每个主机只能安装一个 Elastic Agent,不能在同一主机上运行 Fleet Server 和另一个 Elastic Agent,除非部署容器化 Fleet Server。
使用Fleet UI可以快速部署Fleet Server。
- 指定一个或多个 Elastic Agents 将用于连接到 Fleet Server 的主机 URL。
- 单击“Agent”选项卡并按照产品内的说明添加 Fleet Server。
- 选择Quick Start 可以让 Fleet 自动生成 Fleet Server 策略、注册令牌和自签名证书,不建议用于生产用例。
- 选择高级可以使用自己的 Fleet Server 策略、使用自己的 TLS 证书来加密 Elastic Agents 和 Fleet Server 之间的流量。

可扩展性
修改部署中的设置和 Fleet Server 策略来扩展 Fleet Server。Fleet Server 提供了一些高级设置。
cache
num_counters
//Size of the hash table. Best practice is to have this set to 10 times the max connections.
max_cost
//Total size of the cache.
server.limits
policy_throttle
//How often a new policy is rolled out to the agents.
checkin_limit.interval
//How fast the agents can check in to the Fleet Server.
checkin_limit.burst
//Burst of check-ins allowed before falling back to the rate defined by interval.
checkin_limit.max
//Maximum number of agents.
artifact_limit.max
//Maximum number of agents that can call the artifact API concurrently. It allows the user to avoid overloading the Fleet Server from artifact API calls.
artifact_limit.interval
//How often artifacts are rolled out. Default of 100ms allows 10 artifacts to be rolled out per second.
artifact_limit.burst
//Number of transactions allowed for a burst, controlling oversubscription on outbound buffer.
ack_limit.max
//Maximum number of agents that can call the Ack API concurrently. It allows the user to avoid overloading the Fleet Server from Ack API calls.
ack_limit.interval
//How often an acknowledgment (ACK) is sent. Default value of 10ms enables 100 ACKs per second to be sent.
ack_limit.burst
//Burst of ACKs to accommodate (default of 20) before falling back to the rate defined in interval.
enroll_limit.max
//Maximum number of agents that can call the Enroll API concurrently. This setting allows the user to avoid overloading the Fleet Server from Enrollment API calls.
enroll_limit.interval
//Interval between processing enrollment request. Enrollment is both CPU and RAM intensive, so the number of enrollment requests needs to be limited for overall system health. Default value of 100ms allows 10 enrollments per second.
enroll_limit.burst
//Burst of enrollments to accept before falling back to the rate defined by interval.分析
Fleet Server是一款成熟的商业产品,其对各个场景的支持、对安全的处理、配置的扩展性等等,都做的比较完善。文档较为详细,按照文档内容可以实现较快速的部署上手。
由于Fleet Server是企业版软件,所以若是想脱离环境和生态单独使用会比较困难。
Logkit - Cluster介绍
Cluster是Logkit的集群管理解决方案。Logkit 通过添加 runner 的形式,提供了丰富的功能来收集、解析和发送多种格式的日志和系统信息。Cluster是为了解决在集群中部署多个 Logkit 时,runner 的管理变得繁琐的问题而开发的。
主要功能
开发者将 Logkit 分成 master 和 slave 两类,master 可以管理 slave 上的 runner。master本身也可以是一个slave,承担数据收集的责任。
- 通过 master 可以查看所有 Logkit 上的 runner 的运行状态;
- 通过 master 可以批量对 Logkit 上的 runner 添加/删除/更新/停止 等操作;
设计

- Logkit 的 cluster 功能采用了 master/slave 的架构,slave 会定期向 master 发心跳注册;
- 一个 slave 的 master 可以有多个,它们都可以对该 slave 进行管理,master本身是一个无状态服务,相当于一个中转站,负责将用户的请求分发给所有的slave,也可以收集所有slave的状态方便用户查看;
- 每一个 slave 都分配一个集群名称,集群名称可以用于将 slave 分类。 master 可以以集群为单位,对 slave 进行批量操作。当然也可以对某一个特定的 slave 进行操作。
- 所有master和slave之间的通信都是通过http进行的。
配置说明
参数说明
cluster 配置参数说明如下(完整的 Logkit 主配置文件字段说明请参考Logkit主配置文件):
| 参数名称 | 参数类型 | 是否必填 | 参数说明 |
| master_url | string 数组 | slave 必填 master 选填 | master_url中的每一项都应该是一个url(包括端口号),它们是当前 Logkit 各个 master 的 url 1. 对于 slave, 它会定期向每个链接发心跳注册,以便让其 master 获取自己的状态 2. 对于 master, 当填写该字段后,它本身也会作为 slave 受到它的 master 控制,当然这个 master 可以是它自己。 |
| is_master | bool | 必填 | 标明当前 Logkit 是否是 master: 1. master 请置为 true 2. slave 请置为 false |
| enable | bool | 必填 | 是否启用 cluster 功能, master 和 slave 都应该置为 true |
在启用 cluster 功能时,将 Logkit 主配置文件中的 bind_host 字段显式绑定一个可以保证master、slave能够互相通信的ip地址和端口,防止出现ip与master不在同一网段,造成master无法访问slave的情况。 (因为当此处的ip地址为空时,作为slave的Logkit会自行获取本机的一个ip地址,并在向master发心跳时将该ip地址发送给master, master会利用该ip与slave进行通信。)
在配置结束后,建议先启动作为master的Logkit,再启动作为slave的Logkit,这样可以避免slave产生向master发心跳失败的错误日志。
配置示例
- master添加字段
"cluster":
"master_url": [],
//若master本身也想承担slave的功能
//可以填上其他master或自身的地址
//例如 "master_url": ["http://192.168.0.2:3000"],
"is_master": true,
"enable": true
- 完整的 Logkit 主配置文件示例(slave)
"max_procs": 8, // 选填,默认为机器的CPU数量
"debug_level": 1, // 选填,默认为0,打印DEBUG日志
"bind_host":"127.0.0.1:3000", // 选填,默认自己找一个4000以上的可用端口开启
"profile_host":"localhost:6060", // 选填,默认为空,不开启
"clean_self_log":true, // 选填,默认false
"clean_self_dir":"./run", // 选填,clean_self_log 为true时候生效,默认 "./run"
"clean_self_pattern":"*.log-*", // 选填,clean_self_log 为true时候生效,默认 "*.log-*"
"clean_self_cnt":5, // 选填,clean_self_log 为true时候生效,默认 5
"rest_dir":"./.logkitconfs", // 选填,通过web页面存放的logkit配置文件夹,默认为logkit程序运行目录的子目录`.logkitconfs`下
"static_root_path":"./public", // 必填,logkit页面的静态资源路径,即项目中public目录下的内容,包括html、css以及js文件,请尽量填写绝对路径
"timeformat_layouts":["[02/Jan/2006:15:04:05 -0700]"], // 选填,默认为空。
"confs_path": ["confs","confs2", "/home/me/*/confs"], // 必填,监听的日志目录
"cluster": // 启用 cluster 功能时填写.
"master_url": ["http://192.168.0.2:3000"],
"is_master": false,
"enable": true
使用
Logkit 具有可视化工具Logkit助手,目前已支持 Cluster 。Logkit 助手主要有三个界面,分别是集群管理页面、机器管理页面和收集器管理页面。
- “集群管理”页面:集群管理页面展示的是集群列表,在这个页面上,可以对同一个集群的 slave 添加一个 runner ,或者对一个特定的 runner 进行开启、关闭、重置和删除等操作,还可以更改这个集群的名字。当需要进行批量操作时,可以通过一个弹框选择要操作的 runner 的名字。机器地址列是该集群下所有的机器地址。

- “机器管理”页面:机器页面展示的是 master 管理的所有的 slave, 包括他们的 url、tag、与 master 的连接状态、上次心跳时间等。状态共有三种:15s内有心跳为“ok”,15~30s内有心跳为“bad”,30s以上没有心跳为“lost”。同时在该页面上也可以更改一台机器的集群, 为一台特定的机器添加 runner 以及将这台机器从 master 的 slave 列表中删掉。这个删掉是临时的, 如果这个 slave 还处于活跃状态,当它向 master 发心跳注册时,它还会回到列表中, 提供这个功能的目的是在需要时从列表中清除处于失联状态的 slave。

- “runner管理”页面:runner 管理页面会展示 master 下所有 slave 的 runner, 在这里可以看到每个 runner 的运行状态,并可以对这些 runner 进行修改、关闭、重启、重置和删除等操作,支持通过集群名称和机器地址进行筛选。

分析
Logkit Cluster的配置较为简单,在已经配置好Logkit的情况下,只需要在原有配置的基础上增加"cluster"字段就可以实现。同时,由于Logkit原本就是有Logkit助手这样的一个可视化前端的,所以增加集群功能后老用户很快就可以上手。
美中不足的是,该功能虽然解决了多机器同时添加runner繁琐的问题,但对于单机器同时添加多个runner的场景并没有优化,这里还有提升的空间。Logkit最大的问题在于文档的滞后,例如企业版2019年发布的对比文档中,对于是否支持集群管理,社区版为“不支持”,事实上本文参考的Logkit 社区版 Cluster 文档发布于2017年12月,社区版与企业版的文档内容产生了冲突。
参考
- logtail企业版 - 机器组:https://help.aliyun.com/document_detail/65021.html
- Elastic Agent - Fleet:https://www.Elastic.co/guide/en/fleet/current/manage-agents-in-fleet.html
- Logkit - Cluster: https://github.com/qiniu/logkit/wiki/Cluster
- Fluentd:https://docs.fluentd.org/monitoring-fluentd/overview
- Telegraf:https://docs.influxdata.com/telegraf/v1.23/
- Loggie:https://loggie-io.github.io/docs/user-guide/architecture/compare/
- Flume:https://cwiki.apache.org/confluence/display/flume
本文为阿里云原创内容,未经允许不得转载。
以上是关于可观测数据采集端的管控方案的简单对比的主要内容,如果未能解决你的问题,请参考以下文章