分布式架构-可观测性-聚合度量
Posted 只会一点java
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式架构-可观测性-聚合度量相关的知识,希望对你有一定的参考价值。
系列目录
引子
分布式架构的可观测性,度量(Metrics)的目的是揭示系统的总体运行状态。度量总体上可分为客户端的指标收集、服务端的存储查询以及终端的监控预警三部分能力,每个过程在系统中一般也会设置对应的组件来实现。Prometheus在度量领域的统治力虽然还暂时不如日志领域中 Elastic Stack(ELK+Beats) 的统治地位那么稳固,但在云原生时代里,已经是事实标准了。本文就以 Prometheus 为例,介绍这三部分组件的原理。
一、指标收集
指标收集部分要解决两个问题:“如何定义指标”(通用指标类型)以及“如何将这些指标告诉服务端”(数据采集方案)。
1.1 指标类型(Metrics Types)
无论何种系统,都是具备一些共性特征。指标的数据类型是有限的。这里列举5个常见指标数据类型。
计数度量器(Counter):这是最好理解也是最常用的指标形式,计数器就是对有相同量纲、可加减数值的合计量,譬如业务指标像销售额、货物库存量、职工人数等等;技术指标像服务调用次数、网站访问人数等都属于计数器指标。
瞬态度量器(Gauge):瞬态度量器比计数器更简单,它就表示某个指标在某个时点的数值。譬如当前 Java 虚拟机堆内存的使用量,这就是一个瞬态度量器;又譬如,网站访问人数是计数器,而网站在线人数则是瞬态度量器。
吞吐率度量器(Meter):吞吐率度量器顾名思义是用于统计单位时间的吞吐量,即单位时间内某个事件的发生次数。譬如交易系统中常以 TPS 衡量事务吞吐率,即每秒发生了多少笔事务交易。
直方图度量器(Histogram):直方图是常见的二维统计图,它的两个坐标分别是统计样本和该样本对应的某个属性的度量,以长条图的形式表示具体数值。
采样点分位图度量器(Quantile Summary):分位图是统计学中通过比较各分位数的分布情况的工具,用于验证实际值与理论值的差距,评估理论值与实际值之间的拟合度。譬如,我们说“高考成绩一般符合正态分布”,这句话的意思是:高考成绩高低分的人数都较少,中等成绩的较多,将人数按不同分数段统计,得出的统计结果一般能够与正态分布的曲线较好地拟合。
1.2 数据采集
数据采集通常有两种:拉取式采集(Pull-Based Metrics Collection)和推送式采集(Push-Based Metrics Collection)。
- Pull 是指度量系统主动从目标系统中拉取指标。
- Push 就是由目标系统主动向度量系统推送指标。
这两种方式并没有绝对的好坏优劣,以前很多老牌的度量系统,如Ganglia、Graphite、StatsD等是基于 Push 的,而以 Prometheus、Datadog、Collectd为代表的另一派度量系统则青睐 Pull 式采集(按需拉取)。
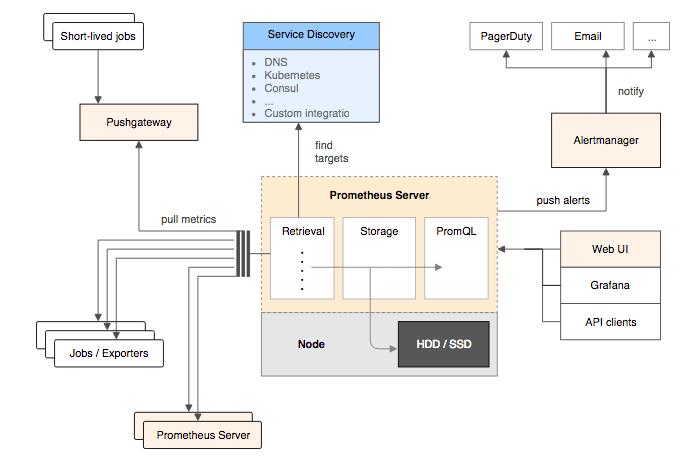
如上图所示,Prometheus 基于 Pull 架构的同时还能够有限度地兼容 Push 式采集(支持Push Gateway再pull)。Prometheus 设计 Push Gateway 的本意是为了解决 Pull 的一些固有缺陷,譬如目标系统位于内网,通过 NAT 访问外网,外网的 Prometheus 是无法主动连接目标系统的,这就只能由目标系统主动推送数据;又譬如某些小型短生命周期服务,可能还等不及 Prometheus 来拉取,服务就已经结束运行了,因此也只能由服务自己 Push 来保证度量的及时和准确。
由于度量面向的是广义上的信息系统,横跨存储、通讯、中间件,直到系统本身的业务指标,一直没有统一的标准。有一些度量系统,譬如老牌的 Zabbix 就选择同时支持了 SNMP、JMX、IPMI 等多种不同的度量协议,另一些度量系统,以 Prometheus 为代表就相对强硬,选择任何一种协议都不去支持,只允许通过 HTTP 访问度量端点这一种访问方式。如果目标提供了 HTTP 的度量端点(如 Kubernetes、Etcd 等本身就带有 Prometheus 的 Client Library)就直接访问,否则就需要一个专门的 Exporter 来充当媒介。
二、存储查询
指标从目标系统采集过来之后,应存储在度量系统中,以便被后续的分析界面、监控预警所使用。早期的度量系统 Zabbix 用的就是传统关系数据库来存储指标。但由于度量指标数据量巨大,时序特性,Prometheus的度量指标数据存储在“时序数据库”(Time Series Database)中。写操作,时序数据通常只是追加,很少删改或者根本不允许删改。针对数据热点只集中在近期数据、多写少读、几乎不删改、数据只顺序追加这些特点,时序数据库被允许做出很激进的存储、访问和保留策略(Retention Policies):
- 以日志结构的合并树(Log Structured Merge Tree,LSM-Tree)代替传统关系型数据库中的B+Tree。LSM 适合的应用场景就是写多读少,且几乎不删改的数据。
- 设置激进的数据保留策略,譬如根据过期时间(TTL)自动删除相关数据以节省存储空间,同时提高查询性能。
- 对数据进行再采样(Resampling)以节省空间。
- 极端情况下,使用轮替型数据库(Round Robin Database,RRD),以环形缓冲的思路实现,只能存储固定数量的最新数据,超期或超过容量的数据就会被轮替覆盖。
近几年随着云原生的快速发展,Prometheus+k8s的监控方案日渐成熟。Prometheus时序数据库,在DB-Engines的排名目前已经跃居时序数据库第三。Prometheus时序数据库提供了名为 PromQL (Prometheus 的文档手册)的数据查询语言,能对时序数据进行丰富的查询、聚合以及逻辑运算。
三、监控预警
指标度量是手段,最终目的是做分析和预警。
3.1 监控
与追踪系统的情况类似:
- 广义上的度量系统由面向目标系统进行指标采集的客户端(Client,与目标系统进程在一起的 Agent,或者代表目标系统的 Exporter 等都可归为客户端),负责调度、存储和提供查询能力的服务端(Server,Prometheus 的服务端是带存储的,但也有很多度量服务端需要配合独立的存储来使用的),以及面向最终用户的终端(Backend,UI 界面、监控预警功能等都归为终端)组成。
- 狭义上的度量系统就只包括客户端和服务端,不包含终端。
Prometheus 应算是处于狭义和广义的度量系统之间,尽管它确实内置了一个界面解决方案“Console Template”,以模版和 JavaScript 接口的形式提供了一系列预设的组件(菜单、图表等),让用户编写一段简单的脚本就可以实现可用的监控功能。不过这种可用程度,往往不足以支撑正规的生产部署,只能说是为把度量功能嵌入到系统的某个子系统中提供了一定便利。在生产环境下,大多是 Prometheus 配合 Grafana 来进行展示的,这是 Prometheus 官方推荐的组合方案,但该组合也并非唯一选择,如果要搭配 Kibana 甚至 SkyWalking来使用也都是完全可行的。
3.2 预警
除了为分析、决策、故障定位等提供支持的用户界面外,度量信息的另一种主要的消费途径是用来做预警。譬如你希望当磁盘消耗超过 90%时给你发送一封邮件或者是一条微信消息,通知管理员过来处理,这就是一种预警。Prometheus 提供了专门用于预警的 Alert Manager,将 Alert Manager 与 Prometheus 关联后,可以设置某个指标在多长时间内达到何种条件就会触发预警状态,触发预警后,根据路由中配置的接收器,譬如邮件接收器、Slack 接收器、微信接收器、或者更通用的WebHook接收器(例如集成钉钉机器人)等来自动通知用户。
如果你觉得本文对你有点帮助的话,记得在右下角点个“推荐”哦,博主在此感谢!
以上是关于分布式架构-可观测性-聚合度量的主要内容,如果未能解决你的问题,请参考以下文章