Spark:基础知识02
Posted Xiao Miao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark:基础知识02相关的知识,希望对你有一定的参考价值。
文章目录
Spark:基础知识
一、IDEA应用开发
1.依赖
<!-- 指定仓库位置,依次为aliyun、cloudera和jboss仓库 -->
<repositories>
<repository>
<id>aliyun</id>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
</repository>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
<repository>
<id>jboss</id>
<url>http://repository.jboss.com/nexus/content/groups/public</url>
</repository>
</repositories>
<properties>
<scala.version>2.12.10</scala.version>
<scala.binary.version>2.12</scala.binary.version>
<spark.version>2.4.5</spark.version>
<hadoop.version>2.6.0-cdh5.16.2</hadoop.version>
</properties>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>$scala.version</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_$scala.binary.version</artifactId>
<version>$spark.version</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>$hadoop.version</version>
</dependency>
</dependencies>
<build>
<outputDirectory>target/classes</outputDirectory>
<testOutputDirectory>target/test-classes</testOutputDirectory>
<resources>
<resource>
<directory>$project.basedir/src/main/resources</directory>
</resource>
</resources>
<!-- Maven 编译的插件 -->
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.0</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
2.应用入口:SparkContext
Spark Application程序入口为:SparkContext,任何一个应用首先需要构建SparkContext对象,如下两步构建:
-
1.创建SparkConf对象
- 设置Spark Application基本信息,比如应用的名称AppName和应用运行Master
-
2.传递SparkConf对象,创建SparkContext对象
package com.miao
import org.apache.spark.SparkConf, SparkContext
object Spark_ConText
def main(args: Array[String]): Unit =
val conf = new SparkConf()
.setAppName("appname")
.setMaster("master")
new SparkContext(conf)
3. 编程实现:WordCount
package com.miao
import org.apache.spark.rdd.RDD
import org.apache.spark.SparkConf, SparkContext
/*
SparkWordCOunt
*/
object WordCount
def main(args: Array[String]): Unit =
// 创建sparkconf对象,设置应用的配置信息,比如应用名称和应用模式
val conf: SparkConf = new SparkConf()
.setAppName("SparkWordCount")
.setMaster("local[2]")
// 构建sparkcontext上下文实例对象,读取数据和调度job执行
val sc: SparkContext = new SparkContext(conf)
//读取数据,每行分割为单词,转换为2元组,按照key分组聚合
val wordsCountRDD: RDD[(String, Int)] = sc.textFile("File/wordcount/wordcount.data")
.flatMap(x => x.split("\\\\s+"))
.map(x => (x, 1))
.reduceByKey((tmp, item) => (tmp + item))
//输出数据
wordsCountRDD.foreach(println)
//保存到存储系统,HDFS
wordsCountRDD.saveAsTextFile("file/output/wordcount")
//线程睡眠,用于测试,查看WEB UI
//Thread.sleep(10000000)
// 关闭资源
sc.stop()
本地模式LocalMode:
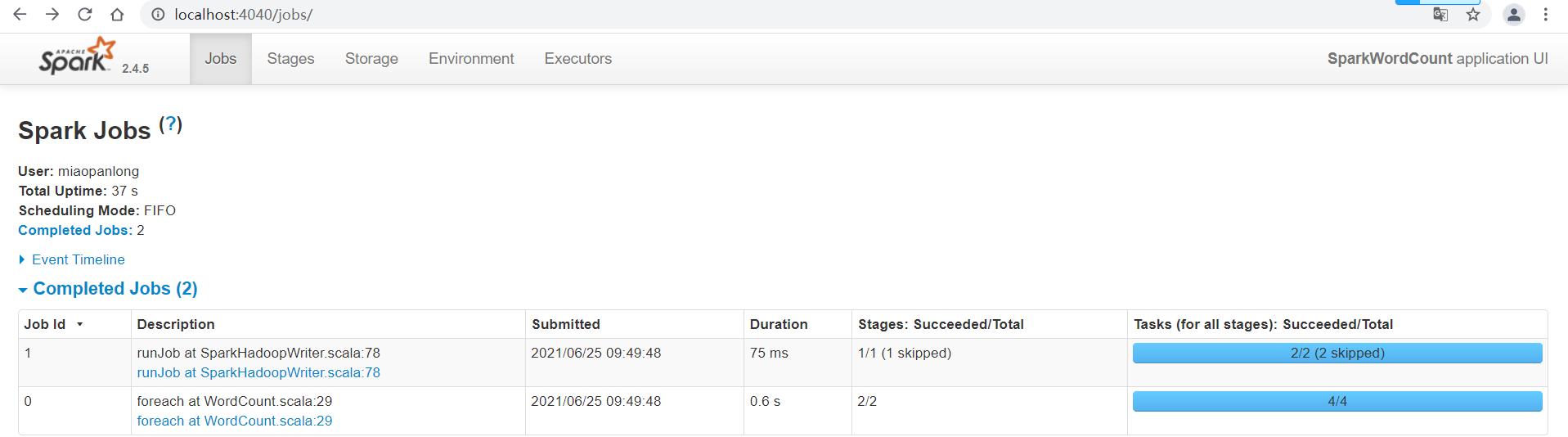
4.编程实现:TopKey
在上述词频统计WordCount代码基础上,对统计出的每个单词的词频Count,按照降序排序,获取词频次数最多Top3单词
- sortByKey:针对RDD中数据类型key/value对时,按照Key进行排序
- sortBy:针对RDD中数据指定排序规则
- top:按照RDD中数据采用降序方式排序,如果是Key/Value对,按照Key降序排序
package com.miao
import org.apache.spark.rdd.RDD
import org.apache.spark.SparkConf, SparkContext
/*
Top3
*/
object Top3
def main(args: Array[String]): Unit =
// 创建sparkconf对象,设置应用的配置信息,比如应用名称和应用模式
val conf: SparkConf = new SparkConf()
.setAppName("Top3")
.setMaster("local[2]")
// 构建sparkcontext上下文实例对象,读取数据和调度job执行
val sc: SparkContext = new SparkContext(conf)
//读取数据,每行分割为单词,转换为2元组,按照key分组聚合
val wordsCountRDD: RDD[(String, Int)] = sc.textFile("File/wordcount/wordcount.data")
.flatMap(x => x.split("\\\\s+"))
.map(x => (x, 1))
.reduceByKey((tmp, item) => (tmp + item))
//输出数据
wordsCountRDD.foreach(println)
println("===================sortByKey排序,结果也交换顺序======================")
/*
def sortByKey(
ascending: Boolean = true,
numPartitions: Int = self.partitions.length
): RDD[(K, V)]
*/
val values01: Array[(Int, String)] = wordsCountRDD
// swap交换元组的两个元素
.map(tuple => tuple.swap)
.sortByKey(false)
.take(3)
values01.foreach(println)
println("===================sortBy排序,结果不交换顺序======================")
/*def sortBy[K](
f: (T) => K, // T 表示RDD集合中数据类型,此处为二元组
ascending: Boolean = true,
numPartitions: Int = this.partitions.length
)
(implicit ord: Ordering[K], ctag: ClassTag[K]): RDD[T]*/
val values02: Array[(String, Int)] = wordsCountRDD
.sortBy(tuple => tuple._2, false)
.take(3)
values02.foreach(println)
println("===================top排序,结果不交换顺序======================")
val values03 = wordsCountRDD
.top(3)(Ordering.by(tuple=>tuple._2))
values03.foreach(println)
sc.stop()
5.spark应用提交
命令提交文档:
[root@node1 ~]# /export/server/spark/bin/spark-submit --help
Usage: spark-submit [options] <app jar | python file | R file> [app arguments]
Usage: spark-submit --kill [submission ID] --master [spark://...]
Usage: spark-submit --status [submission ID] --master [spark://...]
Usage: spark-submit run-example [options] example-class [example args]
Options:
--master MASTER_URL spark://host:port, mesos://host:port, yarn,
k8s://https://host:port, or local (Default: local[*]).
--deploy-mode DEPLOY_MODE Whether to launch the driver program locally ("client") or
on one of the worker machines inside the cluster ("cluster")
(Default: client).
--class CLASS_NAME Your application's main class (for Java / Scala apps).
--name NAME A name of your application.
--jars JARS Comma-separated list of jars to include on the driver
and executor classpaths
语法:
spark-submit [options] <app jar | python file> [app arguments]
基本参数配置
 动态加载Spark Applicaiton运行时的参数,通过–conf进行指定,如下使用方式:
动态加载Spark Applicaiton运行时的参数,通过–conf进行指定,如下使用方式:

Driver Program 参数配置
每个Spark Application运行时都有一个Driver Program,属于一个JVM Process进程,可以设置内存Memory和CPU Core核数
 Executor 参数配置
Executor 参数配置
每个Spark Application运行时,需要启动Executor运行任务Task,需要指定Executor个数及每个Executor资源信息(内存Memory和CPU Core核数)。

官方案例
# Run application locally on 8 cores
./bin/spark-submit \\
--class org.apache.spark.examples.SparkPi \\
--master local[8] \\
/path/to/examples.jar \\
100
# Run on a Spark standalone cluster in client deploy mode
./bin/spark-submit \\
--class org.apache.spark.examples.SparkPi \\
--master spark://207.184.161.138:7077 \\
--executor-memory 20G \\
--total-executor-cores 100 \\
/path/to/examples.jar \\
1000
# Run on a Spark standalone cluster in cluster deploy mode with supervise
./bin/spark-submit \\
--class org.apache.spark.examples.SparkPi \\
--master spark://207.184.161.138:7077 \\
--deploy-mode cluster \\
--supervise \\
--executor-memory 20G \\
--total-executor-cores 100 \\
/path/to/examples.jar \\
1000
# Run on a YARN cluster
export HADOOP_CONF_DIR=XXX
./bin/spark-submit \\
--class org.apache.spark.examples.SparkPi \\
--master yarn \\
--deploy-mode cluster \\ # can be client for client mode
--executor-memory 20G \\
--num-executors 50 \\
/path/to/examples.jar \\
1000
# Run a Python application on a Spark standalone cluster
./bin/spark-submit \\
--master spark://207.184.161.138:7077 \\
examples/src/main/python/pi.py \\
1000
# Run on a Mesos cluster in cluster deploy mode with supervise
./bin/spark-submit \\
--class org.apache.spark.examples.SparkPi \\
--master mesos://207.184.161.138:7077 \\
--deploy-mode cluster \\
--supervise \\
--executor-memory 20G \\
--total-executor-cores 100 \\
http://path/to/examples.jar \\
1000
# Run on a Kubernetes cluster in cluster deploy mode
./bin/spark-submit \\
--class org.apache.spark.examples.SparkPi \\
--master k8s://xx.yy.zz.ww:443 \\
--deploy-mode cluster \\
--executor-memory 20G \\
--num-executors 50 \\
http://path/to/examples.jar \\
1000
package com.miao
import org.apache.spark.rdd.RDD
import org.apache.spark.SparkConf, SparkContext
object SparkSubmit
def main(args: Array[String]): Unit =
val conf: SparkConf = new SparkConf()
.setAppName("SparkSubmit")
//.setMaster("local[2]")
if(args.length<2)
println("Usage: SparkSubmit <input> <output>............")
System.exit(-1)
val sc: SparkContext = new SparkContext(conf)
val wordsCountRDD: RDD[(String, Int)] = sc.textFile(args(0)).flatMap(_.split("\\\\s+"))
.map((_, 1)).reduceByKey(_ + _)
wordsCountRDD.foreach(println)
wordsCountRDD.saveAsTextFile(args(1))
sc.stop()
 打成jar包【spark-chapter01_2.11-1.0.0.jar】,如下图所示:
打成jar包【spark-chapter01_2.11-1.0.0.jar】,如下图所示:
上传到hdfs中
#1.创建hdfs目录
hdfs dfs -mkdir -p /spark/apps
#2.上传jar包
hdfs dfs -put /export/datas/Spark_01-1.0-SNAPSHOT.jar /spark/apps/
注意修改scala版本,否则报错,下边是修改后的版本
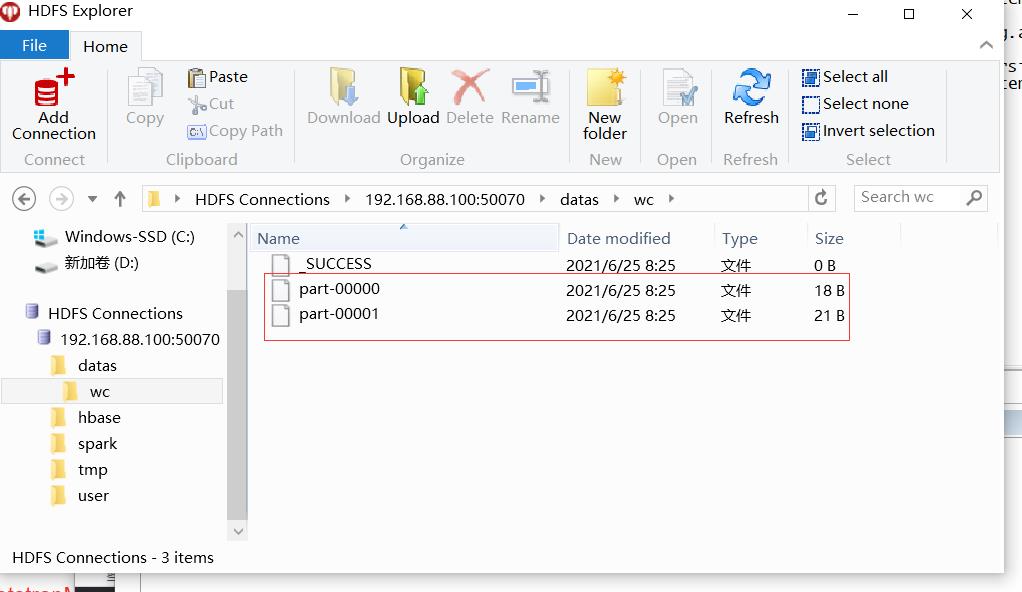
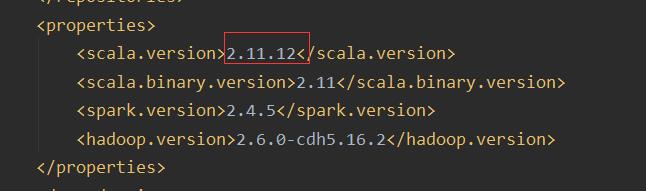 本地模式LocalMode提交运行
本地模式LocalMode提交运行
SPARK_HOME=/export/server/spark
$SPARK_HOME/bin/spark-submit \\
--master local[2] \\
--class com.miao.submit.SparkSubmit \\
hdfs://node1:8020/spark/apps/Spark_01-1.0-SNAPSHOT.jar \\
/datas/wordcount.data /datas/wc
 Standalone集群提交运行
Standalone集群提交运行
SPARK_HOME=/export/server/spark
$SPARK_HOME/bin/spark-submit \\
--master spark://node1:7077,node2:7077 \\
--class com.miao.submit.SparkSubmit \\
--driver-memory 512m \\
--executor-memory 512m \\
--num-executors 1 \\
--total-executor-cores 2 \\
hdfs://node1:8020/spark/apps/Spark_01-1.0-SNAPSHOT.jar \\
/datas/wordcount.data /datas/wc
二、Spark YARN
**启动服务HDFS、YARN、MRHistoryServer和Spark HistoryServer,命令如下:
**
#1.启动HDFS和YARN服务,在node1.itcast.cn执行命令
hadoop-daemon.sh start namenode
hadoop-daemons.sh start datanode
yarn-daemon.sh start resourcemanager
yarn-daemons.sh start nodemanager
#2.启动MRHistoryServer服务,在node1执行命令
mr-jobhistory-daemon.sh start historyserver
#3.启动Spark HistoryServer服务,在node1执行命令
/export/server/spark/sbin/start-history-server.sh
提交应用
- 圆周率
SPARK_HOME=/export/server/spark
$SPARK_HOME/bin/spark-submit \\
--master yarn \\
--class org.apache.spark.examples.SparkPi \\
$SPARK_HOME/examples/jars/spark-examples_2.11-2.4.5.jar \\
10
- wordcount
SPARK_HOME=/export/server/spark
$SPARK_HOME/bin/spark-submit \\
--master yarn \\
--driver-memory 512m \\
--executor-memory 512m \\
--executor-cores 1 \\
--num-executors 2 \\
--queue default \\
--class com.miao.submit.SparkSubmit \\
hdfs://node1:8020/spark/apps/Spark_01-1.0-SNAPSHOT.jar \\
/datas/wordcount.data /datas/wc
三、部署模式
Spark Application提交运行时部署模式Deploy Mode,表示的是Driver Program运行的地方,要么是提交应用的Client:client,要么是集群中从节点(Standalone:Worker,YARN:NodeManager):cluster。
- client 模式
- -deploy-mode client
以Spark Application运行到Standalone集群上为例,前面提交运行圆周率PI或者词频统计
WordCount程序时,默认DeployMode为Client,表示应用Driver Program运行在提交应用Client
主机上(启动JVM Process进程),示意图如下:
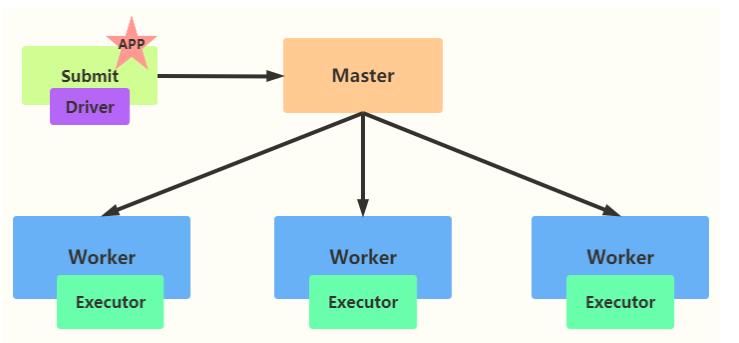
- cluster 模式
- -deploy-mode cluster
如果采用cluster模式运行应用,应用Driver Program运行在集群从节点Worker某台机器上。
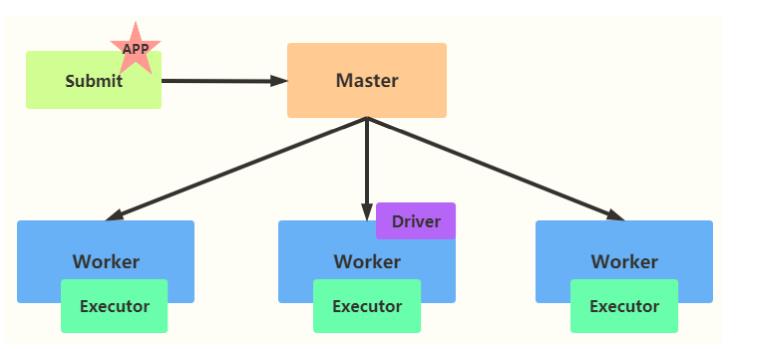
Cluster和Client模式最最本质的区别是:Driver程序运行在哪里
cluster模式:生产环境中使用该模式
- Driver程序在YARN集群中
- 应用的运行结果不能在客户端显示
client 模式:测试时使用,开发不用
- Driver运行在Client上的SparkSubmit进程中
- 应用程序运行结果会在客户端显示
以上是关于Spark:基础知识02的主要内容,如果未能解决你的问题,请参考以下文章