Tensorflow - Tutorial : Variables的保存与恢复
Posted Joe-Han
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Tensorflow - Tutorial : Variables的保存与恢复相关的知识,希望对你有一定的参考价值。
1. 主要方法
我们在训练一个模型时,常希望保存训练过程中的variables,这些variables通常指的是模型的参数。通过保存这些参数以便下次可以继续进行训练或者基于已有的参数进行测试。Tensorflow针对这一需求提供了Saver类,通过Saver类提供的相关方法可以保存和恢复训练过程中的变量,该文件称为检查点文件(checkpoints)。检查点文件是一个二进制文件主要包含从变量名到tensor值的映射关系。当你创建一个Saver对象时,你可以选择性地为检查点文件中的变量挑选变量名。
通过如下语句可创建一个saver 对象来管理模型中的所有变量,需要说明的是:只有在saver之前创建的variables才会被保存到checkpoints文件中,也就是说,写在saver = tf.train.Saver()之后的variables则不会被保存。
saver = tf.train.Saver()Saver()的两个常用参数介绍如下,更多的参数可参考:init
Args:
- max_to_keep:指定要保留的检查点文件的最大数量。 创建新文件时,会删除较旧的文件。 如果该参数为None或0,则保留所有检查点文件。 默认为5(即保留最新的5个检查点文件)
- keep_checkpoint_every_n_hours:用于设置在训练中每N小时保存一个检查点文件。 例如,设置keep_checkpoint_every_n_hours = 2 可确保每2个小时保存一个检查点文件。 默认值为10,000小时(禁用该功能)
- var_list : 有时候在检查点文件中明确定义变量的名称很有用。举个例子,你也许已经训练得到了一个模型,其中有个变量命名为”weights”,你想把它的值恢复到一个新的变量”params”中。有时候仅保存和恢复模型的一部分变量很有用。例如你也许训练得到了一个5层神经网络,现在想训练一个6层的新模型,可以将之前5层模型的参数导入到新模型的前5层中。可以通过给tf.train.Saver()构造函数传入Python字典,很容易地定义需要保持的变量及对应名称:键对应使用的名称,值对应被管理的变量。
通过如下方法可保存当前会话中的变量,当从文件中恢复变量时,不需要事先对它们做初始化。:
saver.save(sess, ckpt_dir, global_step=global_step)Args:
- sess :用于保存变量的会话
- save_path:检查点文件名的路径,如果saver 共享一个save_path,则save_path是检查点文件名的前缀
- global_step:如果提供,则global_step将加到save_path末尾作为检查点文件的名字,如下所示:
- saver.save(sess, ‘my-model’, global_step=0) ==> filename: ‘my-model-0’
- saver.save(sess, ‘my-model’, global_step=1000) ==> filename: ‘my-model-1000’
从“检查点”文件目录返回CheckpointState proto,并获得最近一次保存的检查点文件的路径:
ckpt = tf.train.get_checkpoint_state(ckpt_dir)
checkpoint_path = ckpt.model_checkpoint_path通过如下方法将检查点文件中保存的变量值恢复到当前会话中:
saver.restore(sess, checkpoint_path)2. 代码
利用神经网络进行手写数字识别的代码如下,其中加入了变量的保存与恢复。NIST数据集的格式与数据预处理代码 input_data.py的讲解请参考 :Tutorial (2)
# -*- coding: utf-8 -*-
import tensorflow as tf
import numpy as np
import input_data
import os
# This shows how to save/restore your model (trained variables).
# To see how it works, please stop this program during training and resart.
def init_weights(shape):
return tf.Variable(tf.random_normal(shape, stddev=0.01))
def model(X, w_h, w_h2, w_o, p_keep_input, p_keep_hidden): # this network is the same as the previous one except with an extra hidden layer + dropout
X = tf.nn.dropout(X, p_keep_input)
h = tf.nn.relu(tf.matmul(X, w_h))
h = tf.nn.dropout(h, p_keep_hidden)
h2 = tf.nn.relu(tf.matmul(h, w_h2))
h2 = tf.nn.dropout(h2, p_keep_hidden)
return tf.matmul(h2, w_o)
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
trX, trY, teX, teY = mnist.train.images, mnist.train.labels, mnist.test.images, mnist.test.labels
X = tf.placeholder("float", [None, 784])
Y = tf.placeholder("float", [None, 10])
w_h = init_weights([784, 625])
w_h2 = init_weights([625, 625])
w_o = init_weights([625, 10])
p_keep_input = tf.placeholder("float")
p_keep_hidden = tf.placeholder("float")
py_x = model(X, w_h, w_h2, w_o, p_keep_input, p_keep_hidden)
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=py_x, labels=Y))
train_op = tf.train.RMSPropOptimizer(0.001, 0.9).minimize(cost)
predict_op = tf.argmax(py_x, 1)
ckpt_dir = "./ckpt_dir"
if not os.path.exists(ckpt_dir):
os.makedirs(ckpt_dir)
global_step = tf.Variable(0, name='global_step', trainable=False)
# Call this after declaring all tf.Variables.
saver = tf.train.Saver()
# This variable won't be stored, since it is declared after tf.train.Saver()
non_storable_variable = tf.Variable(777)
# Launch the graph in a session
with tf.Session() as sess:
# you need to initialize all variables
tf.global_variables_initializer().run()
ckpt = tf.train.get_checkpoint_state(ckpt_dir)
if ckpt and ckpt.model_checkpoint_path:
print(ckpt.model_checkpoint_path)
saver.restore(sess, ckpt.model_checkpoint_path) # restore all variables
start = global_step.eval() # get last global_step
print("Start from:", start)
for i in range(start, 50):
for start, end in zip(range(0, len(trX), 128), range(128, len(trX)+1, 128)):
sess.run(train_op, feed_dict=X: trX[start:end], Y: trY[start:end],
p_keep_input: 0.8, p_keep_hidden: 0.5)
global_step.assign(i).eval() # set and update(eval) global_step with index, i
saver.save(sess, ckpt_dir + "/model.ckpt", global_step=global_step)
print(i, np.mean(np.argmax(teY, axis=1) ==
sess.run(predict_op, feed_dict=X: teX,
p_keep_input: 1.0,
p_keep_hidden: 1.0)))3. 实验结果
模型训练10次后停止,运行结果如下图所示:
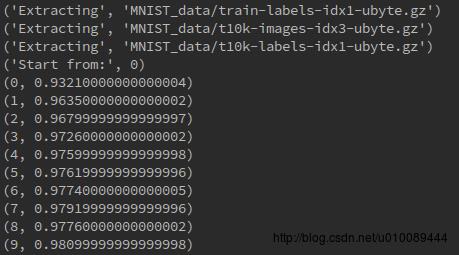
生成的检查点文件如下图所示:
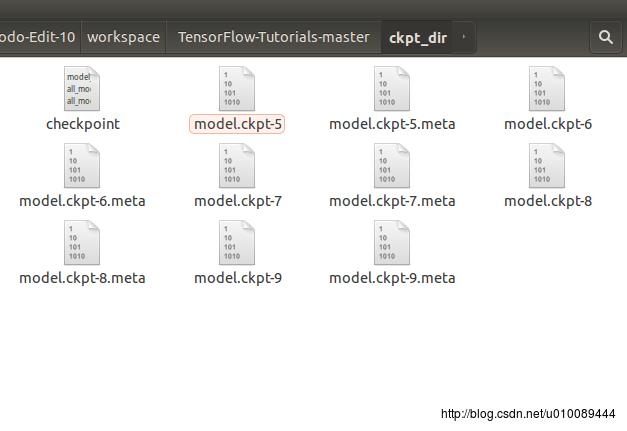
打开名为checkpoint的文件,可以看到保存记录,和最新的模型存储位置:

重新运行程序,从第10轮迭代开始继续训练:

以上是关于Tensorflow - Tutorial : Variables的保存与恢复的主要内容,如果未能解决你的问题,请参考以下文章
Tensorflow - Tutorial : GAN生成图片
Tensorflow - Tutorial : GAN生成图片
python 来自https://github.com/MorvanZhou/Tensorflow-Tutorial/blob/master/tutorial-contents/305_tensorb
Tensorflow - Tutorial : Variables的保存与恢复