机器学习之Kmeans
Posted 未央夜色
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习之Kmeans相关的知识,希望对你有一定的参考价值。
聚类
非监督学习,输入的数据没有标签,通过学习找出数据内在的性质和规律。
两个基本问题来衡量聚类效果的好坏:
性能度量
最佳的效果是簇内相似度高,簇间相似度低(类似高内聚低耦合)
簇间度量(越大越好)
- Jrccard系数
- FM系数
- Rand系数
簇内度量
- DB系数(越小越好)
- Dumn系数(越大越好)
距离计算
有序属性
- 闵可夫斯基距离

- 曼哈顿距离
是闵可夫斯基距离参数=1 的情况
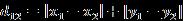
- 欧氏距离
是闵可夫斯基距离参数=2 的情况
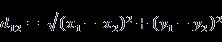
无序属性
Kmeans算法
综述
一种典型的无监督聚类算法。
根据距离计算,把相似度更近的放在一起的算法。
分类和聚类的最大区别是:分类的目标事先已知。聚类产生哪些类,事先不知道。
根据用户的要求,把数据集分成K类。结果性能的好坏,关键是K的选择
凸函数:fx的二次导数严格大于0
算法
- 随机选择K个点作为起始质心。
- 计算数据中每个点和起始质心之间的距离
- 将数据分给最近的簇
- 对于每个簇,计算平均中心,作为新的质心
- 重复上述变换,直到质心的变换小于给定的阀值
递归部分:计算距离,分配,重置质心
- 计算点到每个中心点的距离
- 距离哪个中心点近,就归为哪个类
- 求中心点和新点的均值。
- 重置该类中心点
- 计算下一个点
评价
最终得出的结果和最开始质心的选择有关。
容易陷入局部最优,而非全局最
分级聚类
综述
分级聚类通过将数据集中最相似的两个数据合并,得出一个新的群组
以后的操作都是合并两个最相近的群组,直到最后只剩下一个群组
层次聚类
分为自顶向下和自底向上两类
算法
自底向上:
将原始数据集中的每个数据都当做一个簇
找出距离最近的两个簇进行合并
直到达到预计的簇的个数
最近距离,最远距离,平均距离
以上是关于机器学习之Kmeans的主要内容,如果未能解决你的问题,请参考以下文章