系统学习机器学习之特征工程--多重共线性
Posted Eason.wxd
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了系统学习机器学习之特征工程--多重共线性相关的知识,希望对你有一定的参考价值。
什么是多重共线性?
回归中的多重共线性是一个当模型中一些预测变量与其他预测变量相关时发生的条件。严重的多重共线性可能会产生问题,因为它可以增大回归系数的方差,使它们变得不稳定。以下是不稳定系数导致的一些后果:
- 即使预测变量和响应之间存在显著关系,系数也可能看起来并不显著。
- 高度相关的预测变量的系数在样本之间差异很大。
- 从模型中去除任何高度相关的项都将大幅影响其他高度相关项的估计系数。高度相关项的系数甚至会包含错误的符号。
其实,通俗来讲,就是说,假设变量A、B都对结果Y有影响,也就是,A、B是你回归模型中的特征,一般我们假设特征都是IID,实际中A、B相关的情况是避免不了的,因此,在A、B相关的情况下,需要控制A或者B,否则结果会有偏,回归系数的方差,跟A、B的相关程度有关,如果相关性太强,结果显著性就不好,这种情况叫做多重共线性。
要度量多重共线性,可以检查预测变量的相关性结构,也可以查看方差膨胀因子 (VIF)。VIF 用于在您的预测变量相关时,度量估计回归系数的方差增加的幅度。如果所有 VIF 都为 1,则不存在多重共线性,但如果有些 VIF 大于 1,则预测变量为相关。VIF 大于 5 时,该项的回归系数的估计结果不理想。如果某个预测变量与其他预测变量的关联接近完美,则 Minitab 将显示一条消息,指出无法估计该项。无法估计的项的 VIF 值数通常超过十亿。
方差膨胀因子(Variance Inflation Factor),计算方法如下,对每个变量构建一个如下的最小二乘模型:

对于线性回归模型来说,模型的方差就是估计出的系数方差:
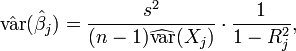
多重共线性反映在最后一项上,也就是说系数的方差变大了。方差膨胀因子,用于在预测变量相关时,度量估计回归系数的方差增加的幅度:
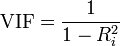
其中R^2为模型的确定系数,计算公式如下:

其中:
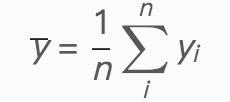
矩阵的特征值也可以用来衡量变量之间的共线性,如果几个变量之前存在共线性问题,那么有几个特征值就很小。
另外一个指标是条件数(Condition Number),条件数的计算方法为最大的特征值除上最小的特征值:
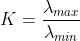
当矩阵的条件数较小时说明该矩阵的共线性问题较小,当条件数较大时则表示数据可能存在比较大的共线性问题。一般来说,条件数在100以下则表示问题不大,在100到1000之间可能需要关注下共线性问题,如果大于1000则表示存在比较严重的共线性问题。
每一个特征值都对应一个条件指数(Condition Indices),计算方法为最大的特征值除上当前特征值:
方差比例(Variance Proportion)可以用来找出存在共线性的变量,方差比例体现了变量对于特征值的贡献程度,当一个特征值对应的几个变量的方差比例同时比较大时,则表示这几个变量可能存在多重共线性,方差比例的计算方法如下:
首先求得每个特征值所对应的特征向量:

于是,第i个特征值所对应的第j个变量的方差分解比例为:

在分析多重共线性问题时,一般会先找到最大的条件指数,看是否在容忍范围内,若超出范围,则在该行找到方差比例较大的几个变量,这几个变量即可能存在多重共线性的问题。
多重共线性不会影响拟合优度和预测优度。系数(线性判别函数)无法可靠地进行解译,但拟合(分类)值不会受到影响。
注意:多重共线性在判别分析中的效应与在回归中相同。
补充一份来自知乎的解释:






其实,到这里应该就很清楚了,也就是说,多重共线性影响的是模型的系数确定性、解释性,通俗一点讲,就是线性回归模型的系数没有训练准确。
多重共线性的纠正方法
严重多重共线性的可能解决办法:
- 如果要对多项式进行拟合,请将预测变量值减去预测变量的均值。
- 从模型中删除那些高度相关的预测变量。由于它们提供了冗余信息,因此删除它们通常不会显著减少 R2。考虑使用逐步回归、最佳子集回归或数据集的专门知识来删除这些变量。
- 使用偏最小二乘或主成分分析。这些方法可以将预测变量的数量减少为更小的不相关分量集。
- 增加样本数,实际上,对大多数模型来说,多重共线性并不是一个很严重的问题
以上是关于系统学习机器学习之特征工程--多重共线性的主要内容,如果未能解决你的问题,请参考以下文章