OceanBase存储引擎核心-LSM Tree VS B-tree
Posted hanruikai
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了OceanBase存储引擎核心-LSM Tree VS B-tree相关的知识,希望对你有一定的参考价值。
1.什么是LSM Tree
LSM Tree是一种数据结构,全称是Log Structure Merged Tree,顾名思义,基于日志结构的、可以合并的树。
通过定义,我们发现三个关键点:
- 基于日志结构
- 支持合并
- 树结构
适用场景:写入量比较大的时候,为什么呢?因为LSM Tree是顺序写,避免IO寻址操作,节省时间。
很多的其他NoSQL数据库核心也是这种数据结构,主要包括Cassandra,BigTable,RocksDB等。
SSTables
LSM Tree持久化磁盘利用 Sorted Strings Table (SSTable) 格式。这种格式利用string串储存key value,并且key有序,便于查询。
格式举例如下:
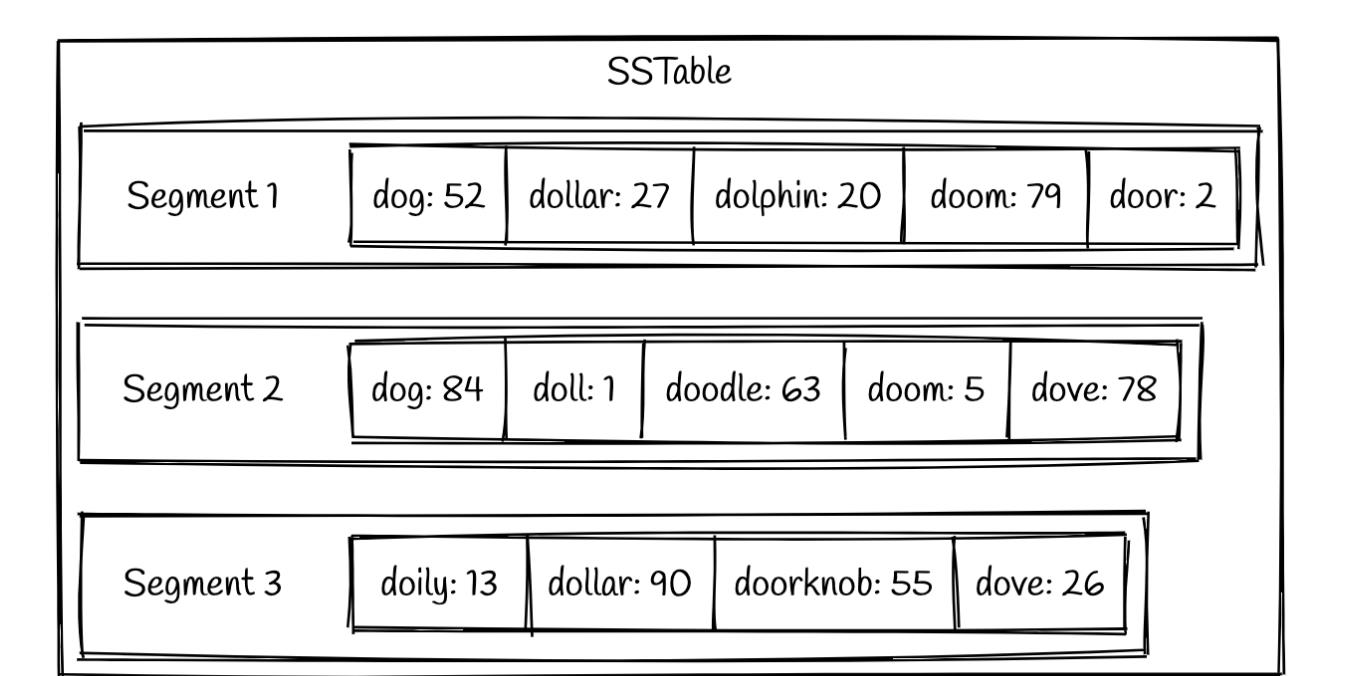
SSTable是有多个Segment组成,每个Segment是有一个key value的有序串组成。
写数据
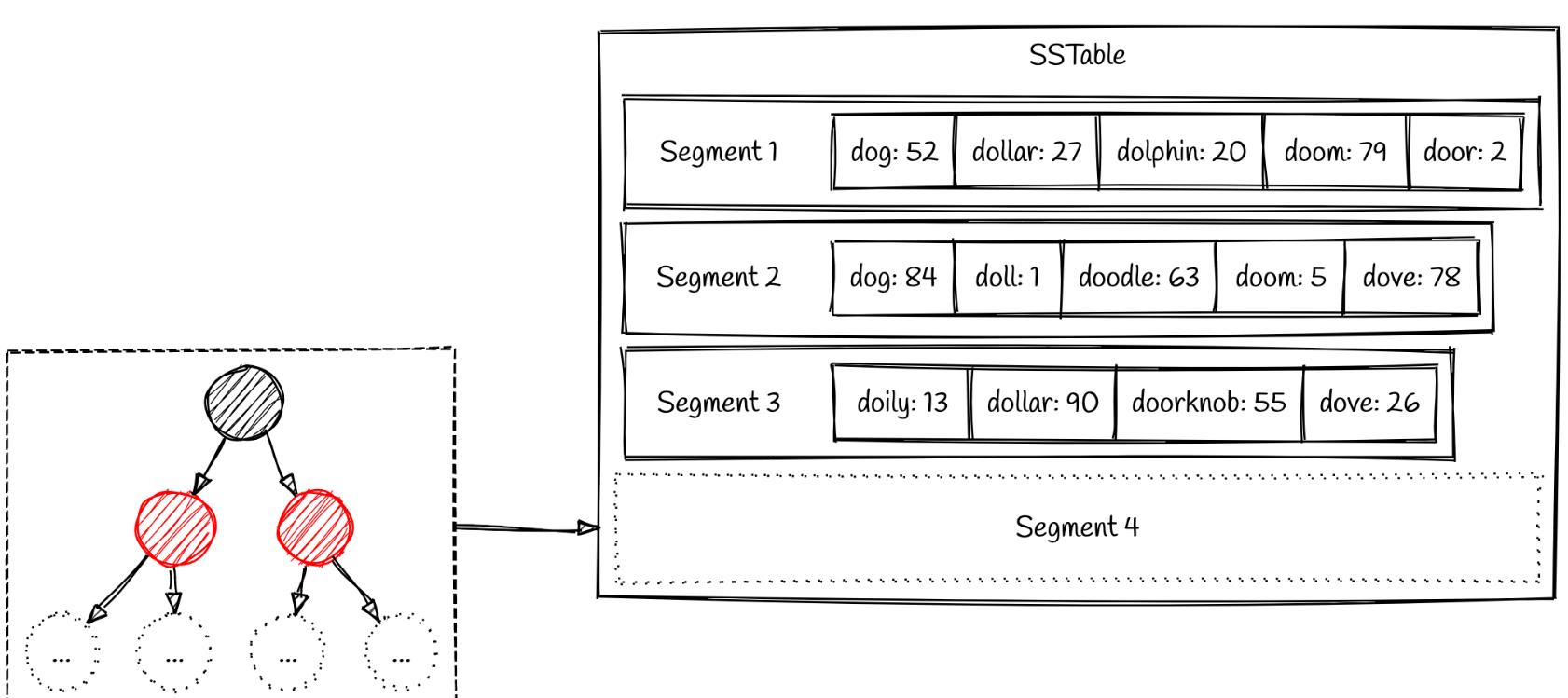
上面说到两个关键点,一个是存储结构是有序的字符串,我们称为segment,一个是顺序写,写入后不可更改。如果在随机写入数据的时候,保证写入的结果是有序的呢?
内存写入,然后排序,达到树的size限制后,最后以segment的格式刷入磁盘。内存采用什么数据结构呢?------著名的红黑树
读数据
我们可以扫描每个segment,依次从最新的segment开始,直到匹配为止。为了提高效率,我们可以基于内存,建立稀疏索引。索引包括key和offset,这就是为什么必须有序!!!
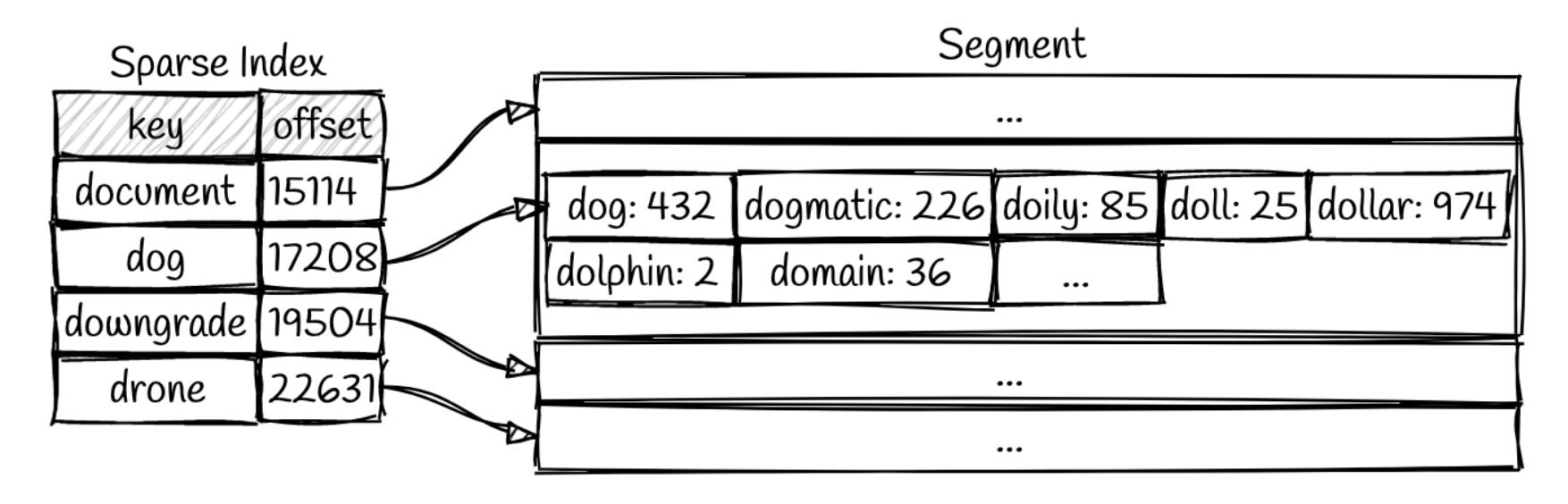
比如,上面的情况,如果我们需要查询dollar这个key,不知道存在与否,这个时候,我们根据排序,利用二分查找,判断dollar在dog和downgrade之间,所以扫描的offset仅仅
在17208-19504。
如果这个值不在segmetn,我们还需要遍历所有的segment。为了提高这种场景的性能,我们可以加入布隆过滤器,利用空间换时间,提高查询不存在数据的性能。
压缩
如果segment数量一直增加,会失去控制,需要压缩进程处理。另外,我们的segment只是增加,不允许修改,如果更新之后,必然原来的key 和lvalue应该删除的。
这也是压缩进程的工作,如下图:
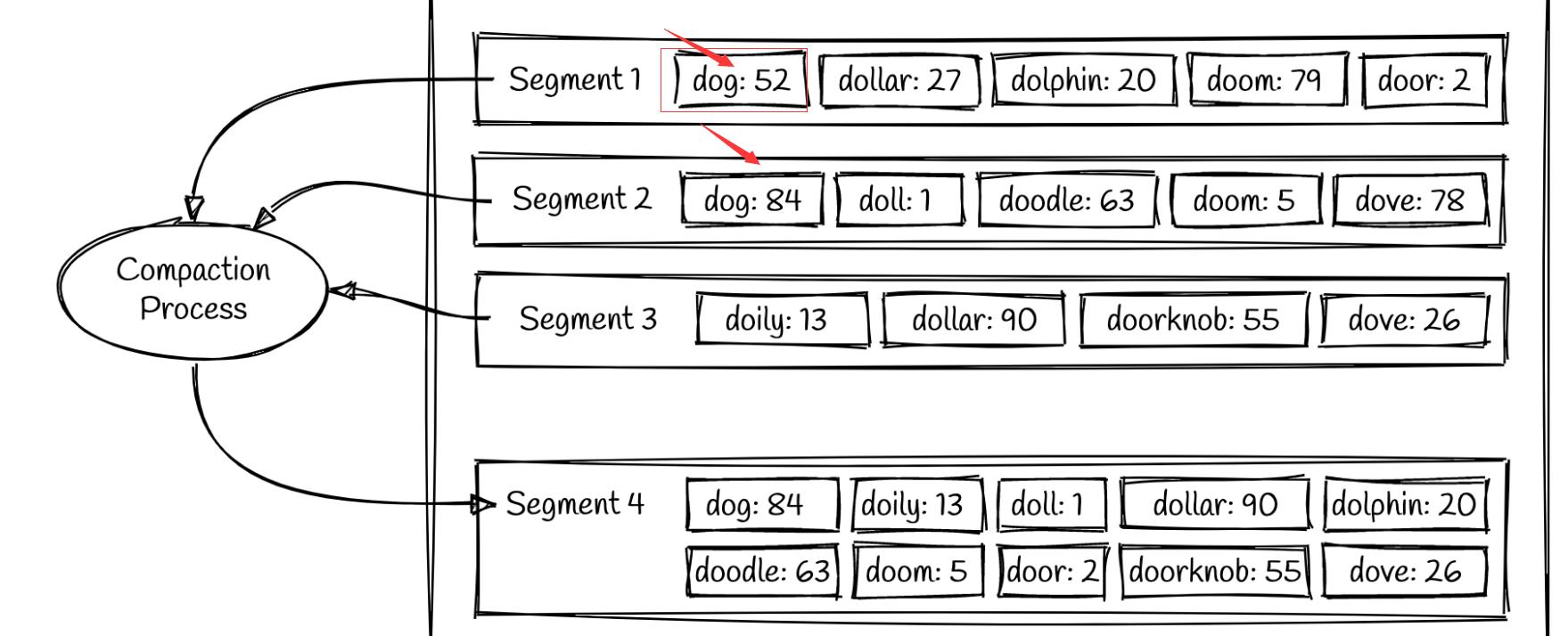
上图中,segment1中的dog值为52,后来修改为84,见segment2,在压缩进程处理后,segment4中仅保存最新值。
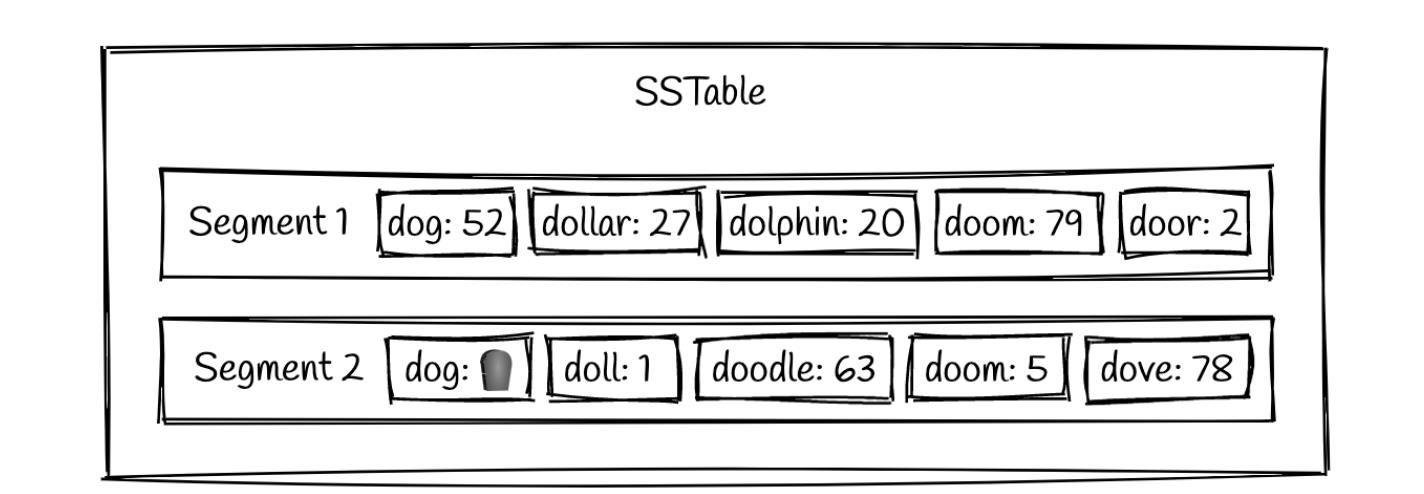
删除数据
删除操作通更新操作一样,删除某个key,把value设置为垃圾桶标志,在压缩的时候,进行更新,如下:
总结
我们总结一下LSM tree的关键点:
- 写入操作是基于内存树结构,称之为memtable,只有这样写入效率才能提高,写入的时候,任何其他的数据结构,比如布隆过滤器、稀疏索引都会更新
- 数据不可能一直保存在磁盘,在tree达到上限设置的size后,刷入磁盘,并且key有序!
对比B-tree
基本区别
NoSQL的key value存储结构越来越流行,在key value存储背后,数据库引擎主要包括以下两种:
- LSM Tree
- B-Tree
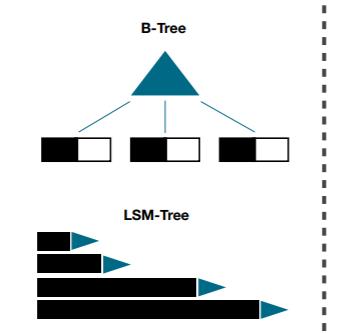
LSM-Tree的数据更新是追加更新文件(最终删除过时的数据)。和LSM-Tree不一样,B-Tree-底层的基本写操作是使用新数据覆盖磁盘上的旧页。可以理解为磁头先移动到正确位置,然后旋转盘面,最后用新的数据覆盖相应的扇区(SSD的覆盖写更加复杂,需要擦写更大的数据块,可能会产生写放大)。也就是说当数据被覆盖时,索引上对该页的引用并不需要改变。
下图展示了基本的不同,我们熟悉的mysql都是基于B-tree结构的。
应用场景
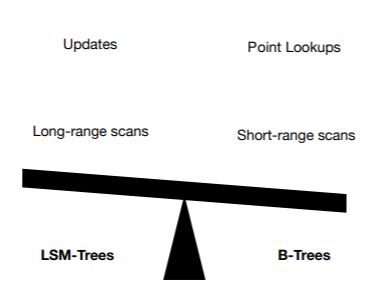
我们根据原理分析一下应用场景,B-Tree是一个多叉树,能够快速定位到某个key。然后LSM Tree是基于红黑树,也就是内存的SSTable,
在磁盘保存给若干个segment,多个key可能存在于多个segment中。
所以如果B-Tree存储引擎适用于短范围查询和给定值查询。LSM Ttree适合于场范围查询和高并发写入,如下图的天平所示:
参考文献:
http://daslab.seas.harvard.edu/doc/undergrad-poster/SIGMOD-UG-BTREE-LSMTREE-BEST-OF-BOTH.pdf
以上是关于OceanBase存储引擎核心-LSM Tree VS B-tree的主要内容,如果未能解决你的问题,请参考以下文章