LSM设计一个数据库引擎
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了LSM设计一个数据库引擎相关的知识,希望对你有一定的参考价值。
Log-Structured Merge-Tree,简称 LSM。
以 mysql、postgresql 为代表的传统 RDBMS 都是基于 b-tree 的 page-orented 存储引擎。现代计算机的最大处理瓶颈在磁盘的读写上,数据存储无法绕开磁盘的读写,纯内存型数据库除外,但由于内存存储的不稳定性,我们一般只将内存型的存储作为缓存系统。
为提升数据库系统的写性能,我们发现磁盘的顺序写性能远远大于随机写性能,甚至性能高于内存的随机写。所以在很多偏向写性能的数据库系统中,以牺牲一部分读性能和增大写放大的情况下引入了 LSM 数据结构。
设计一个数据库引擎
我们从头开始设计一个数据库引擎。数据模型很简单,我们选最简单的 Key-Value 结构,一条数据只有一个 Key 和一个 Value。操作只有 get 和 put,如下:
get(key);
put(key, value);从最简单的开始,每个数据库一个data.db文件,我们像写日志一样,将每条记录 append 到文件结尾。
key1,value1
key2,value2
key3,value3
key10,value10
key8,value8这样我们已经完成了 80%了,然后需要完成读功能。如上数据文件,若需要查询 key2 数据,我们只能从文件开头开始遍历,当直到读取到 key2 数据:
for (row in rows) {
if (row.key == "key1") {
return row;
}
}好了,一个简单的数据库就完成了。
什么?完成了?是的,完成了,虽然说拿出去会被砍死,但谁也不能否认它已经完成了一个数据库系统的最基本功能。
这样的遍历是十分耗费性能的。那么怎么提高读取性能呢?创建一个内存索引“Index”即可,最简单的方式,在内存中维护一个 Map,存储每个 key 对应的文件内容偏移量。这样读取一条记录就只需要一次内存操作加上一次磁盘操作就可以了。
b-tree 是因何出现的?想一想上面的 Map 结构的索引有什么缺点?Map 索引解决了随机单点读的性能问题,但无法解决 Rang 查询,比如需要查询 key 在 key1 和 key200 之间的数据。于是,就有了 b-tree,b 树是有序的结构树,可以很简单的进行 Rang 查询。
b-tree 将所有数据都索引在内存中,当数据无限增长时,将无法在内存中存放这么大的索引文件。
我们来看看 LSM 的实现。
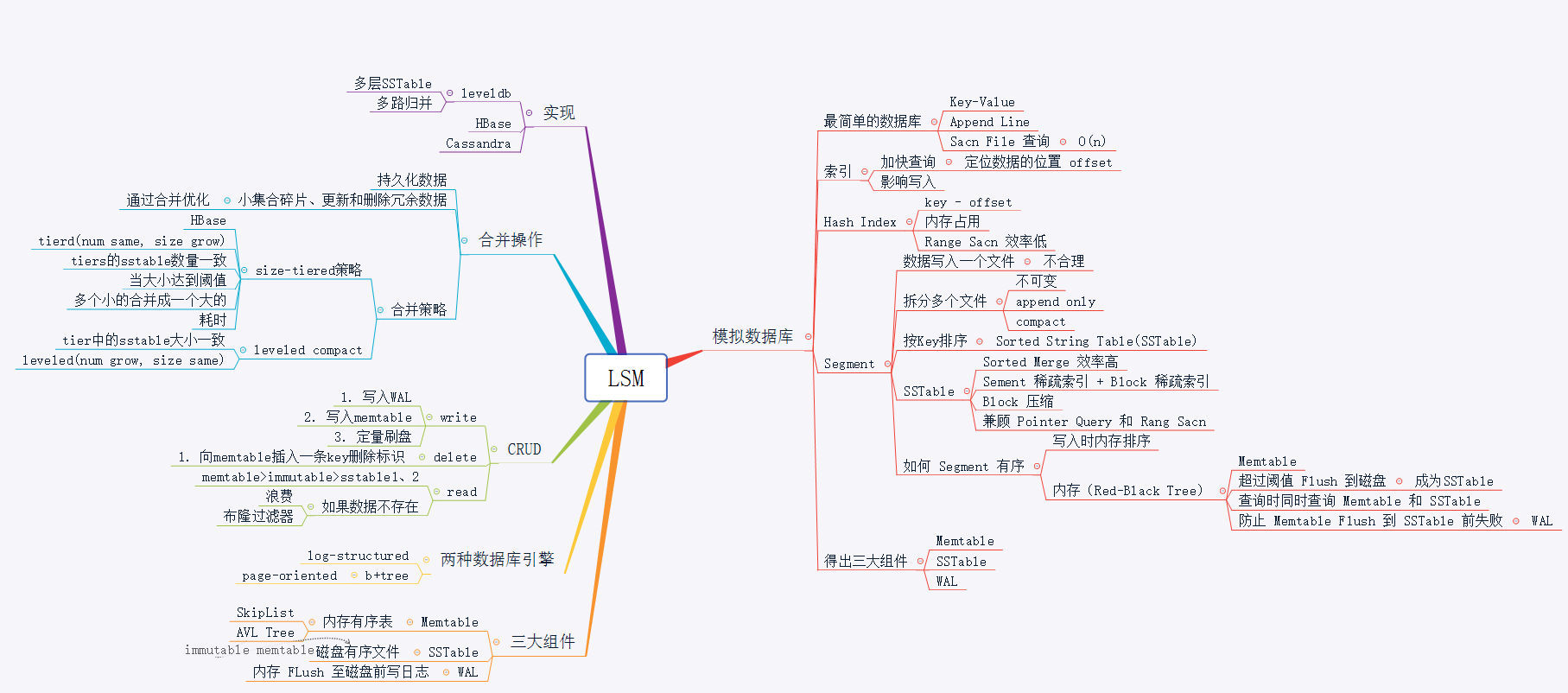
LSM 架构
SSTable:LSM 的磁盘文件,称作SSTable(Sorted String Table)。望文得意,LSM 存储在磁盘中的文件,数据也是按 Key 排序存储的,这样就可以解决上面讲到的数据量大了之后无法将数据全部索引到内存中的问题。如果磁盘文件也是有序的,那么内存索引可以采取”稀疏索引“(Sparse Index),可以每一段记录一个索引,将数据逻辑上分成多个block,稀疏索引只需要记录每个block的偏移量,每条数据通过遍历block实现。这样索引量将大大减小。
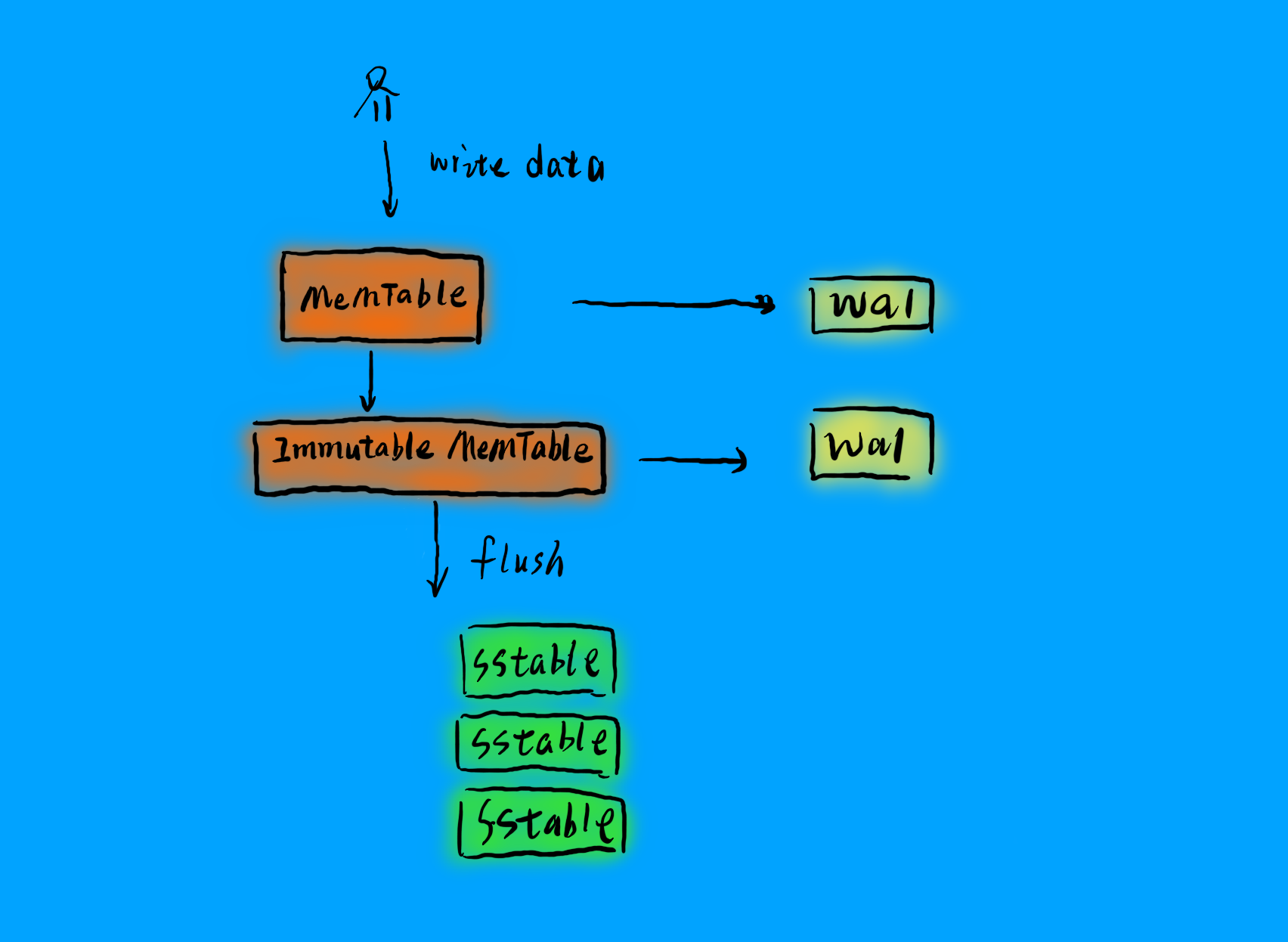
Memtable:LSM 的内存结构叫做Memtable。Memtable是一个有序结构,同样可以采用树结构,可以用跳表。LSM 写数据时,只需要写入内存中的Memtable,当Memtable到达一定量之后,会异步刷入磁盘,就是上面的SSTable。
immutable Memtable:在数据从内存Memtable刷入SSTable时,为避免读写锁导致的性能问题,LSM 会在内存中 copy 一份immutable Memtable表,顾名思义,这个数据结构不可改变,新写入的数据只会写入新的Memtable,immutable Memtable供刷盘线程读取,查询数据的请求也可以访问这个数据结构,这样如果数据在内存中,就不需要访问磁盘,可以提供数据查询的效率。
WAL:write ahead log,预写日志,关于 WAL,可以参考我之前的文章[《你常听说的 WAL 到底是什么》]()。在 LSM 中,在数据刷入磁盘前,为防止异常导致数据丢失,LSM 会先将数据写入 WAL,然后写入 SSTable,系统重启时,LSM 会从 WAL 中回溯 SSTable,当写完一个 SSTable 时,LSM 会清理掉过期的 WAL 日志,防止 WAL 过量。
LSM 写
LSM 的写包括四个流程:
- 写入 WAL
- 写入 memtable
- memtable 达到阈值时,复制 imutable memtable
- 异步刷入磁盘
LSM 删除
为保证顺序写磁盘,LSM 不会去直接删除数据,而是通过写一条 delete 标识来表示数据被删除,数据只有在被 Compact 时才会被真正删除。
LSM 读
LSM 读取数据将从memtable、imutable、sstable依次读取,直到读取到数据或读完所有层次的数据结构返回无数据。所以当数据不存在时,需要依次读取各层文件。LSM 可以通过引入布隆过滤器来先判断一个数据是否存在,避免无效的扫文件。
LSM 合并
LSM 的合并策略是 LSM 很重要的一个部分,我们将放在下一篇文章中单独讲解。
LSM 结构的应用十分广泛,诸如Bigtable,HBase,LevelDB,SQLite4, Tarantool , RocksDB,WiredTiger ,Apache Cassandra,InfluxDB 底层都使用了 LSM。只好的文章,我们将详细讲解 LSM 在 leveldb 或 Cassandra 中的实现。
推荐:
Mysql 大表问题和解决
Mysql 主键问题
列式存储
时间序列数据库(TSDB)初识与选择
十分钟了解 Apache Druid
Apache Druid 底层存储设计
Apache Druid 的集群设计与工作流程

Log-Structured Merge-Tree,简称 LSM。
以 Mysql、postgresql 为代表的传统 RDBMS 都是基于 b-tree 的 page-orented 存储引擎。现代计算机的最大处理瓶颈在磁盘的读写上,数据存储无法绕开磁盘的读写,纯内存型数据库除外,但由于内存存储的不稳定性,我们一般只将内存型的存储作为缓存系统。
为提升数据库系统的写性能,我们发现磁盘的顺序写性能远远大于随机写性能,甚至性能高于内存的随机写。所以在很多偏向写性能的数据库系统中,以牺牲一部分读性能和增大写放大的情况下引入了 LSM 数据结构。
设计一个数据库引擎
我们从头开始设计一个数据库引擎。数据模型很简单,我们选最简单的 Key-Value 结构,一条数据只有一个 Key 和一个 Value。操作只有 get 和 put,如下:
get(key);
put(key, value);从最简单的开始,每个数据库一个data.db文件,我们像写日志一样,将每条记录 append 到文件结尾。
key1,value1
key2,value2
key3,value3
key10,value10
key8,value8这样我们已经完成了 80%了,然后需要完成读功能。如上数据文件,若需要查询 key2 数据,我们只能从文件开头开始遍历,当直到读取到 key2 数据:
for (row in rows) {
if (row.key == "key1") {
return row;
}
}好了,一个简单的数据库就完成了。
什么?完成了?是的,完成了,虽然说拿出去会被砍死,但谁也不能否认它已经完成了一个数据库系统的最基本功能。
这样的遍历是十分耗费性能的。那么怎么提高读取性能呢?创建一个内存索引“Index”即可,最简单的方式,在内存中维护一个 Map,存储每个 key 对应的文件内容偏移量。这样读取一条记录就只需要一次内存操作加上一次磁盘操作就可以了。
b-tree 是因何出现的?想一想上面的 Map 结构的索引有什么缺点?Map 索引解决了随机单点读的性能问题,但无法解决 Rang 查询,比如需要查询 key 在 key1 和 key200 之间的数据。于是,就有了 b-tree,b 树是有序的结构树,可以很简单的进行 Rang 查询。
b-tree 将所有数据都索引在内存中,当数据无限增长时,将无法在内存中存放这么大的索引文件。
我们来看看 LSM 的实现。
LSM 架构
SSTable:LSM 的磁盘文件,称作SSTable(Sorted String Table)。望文得意,LSM 存储在磁盘中的文件,数据也是按 Key 排序存储的,这样就可以解决上面讲到的数据量大了之后无法将数据全部索引到内存中的问题。如果磁盘文件也是有序的,那么内存索引可以采取”稀疏索引“(Sparse Index),可以每一段记录一个索引,将数据逻辑上分成多个block,稀疏索引只需要记录每个block的偏移量,每条数据通过遍历block实现。这样索引量将大大减小。
Memtable:LSM 的内存结构叫做Memtable。Memtable是一个有序结构,同样可以采用树结构,可以用跳表。LSM 写数据时,只需要写入内存中的Memtable,当Memtable到达一定量之后,会异步刷入磁盘,就是上面的SSTable。
immutable Memtable:在数据从内存Memtable刷入SSTable时,为避免读写锁导致的性能问题,LSM 会在内存中 copy 一份immutable Memtable表,顾名思义,这个数据结构不可改变,新写入的数据只会写入新的Memtable,immutable Memtable供刷盘线程读取,查询数据的请求也可以访问这个数据结构,这样如果数据在内存中,就不需要访问磁盘,可以提供数据查询的效率。
WAL:write ahead log,预写日志,关于 WAL,可以参考我之前的文章[《你常听说的 WAL 到底是什么》]()。在 LSM 中,在数据刷入磁盘前,为防止异常导致数据丢失,LSM 会先将数据写入 WAL,然后写入 SSTable,系统重启时,LSM 会从 WAL 中回溯 SSTable,当写完一个 SSTable 时,LSM 会清理掉过期的 WAL 日志,防止 WAL 过量。
LSM 写
LSM 的写包括四个流程:
- 写入 WAL
- 写入 memtable
- memtable 达到阈值时,复制 imutable memtable
- 异步刷入磁盘
LSM 删除
为保证顺序写磁盘,LSM 不会去直接删除数据,而是通过写一条 delete 标识来表示数据被删除,数据只有在被 Compact 时才会被真正删除。
LSM 读
LSM 读取数据将从memtable、imutable、sstable依次读取,直到读取到数据或读完所有层次的数据结构返回无数据。所以当数据不存在时,需要依次读取各层文件。LSM 可以通过引入布隆过滤器来先判断一个数据是否存在,避免无效的扫文件。
LSM 合并
LSM 的合并策略是 LSM 很重要的一个部分,我们将放在下一篇文章中单独讲解。
LSM 结构的应用十分广泛,诸如Bigtable,HBase,LevelDB,SQLite4, Tarantool , RocksDB,WiredTiger ,Apache Cassandra,InfluxDB 底层都使用了 LSM。只好的文章,我们将详细讲解 LSM 在 leveldb 或 Cassandra 中的实现。
推荐:
Mysql 大表问题和解决
Mysql 主键问题
列式存储
时间序列数据库(TSDB)初识与选择
十分钟了解 Apache Druid
Apache Druid 底层存储设计
Apache Druid 的集群设计与工作流程
以上是关于LSM设计一个数据库引擎的主要内容,如果未能解决你的问题,请参考以下文章