程序的机器级表示
Posted geeklove01
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了程序的机器级表示相关的知识,希望对你有一定的参考价值。
Procedure Example

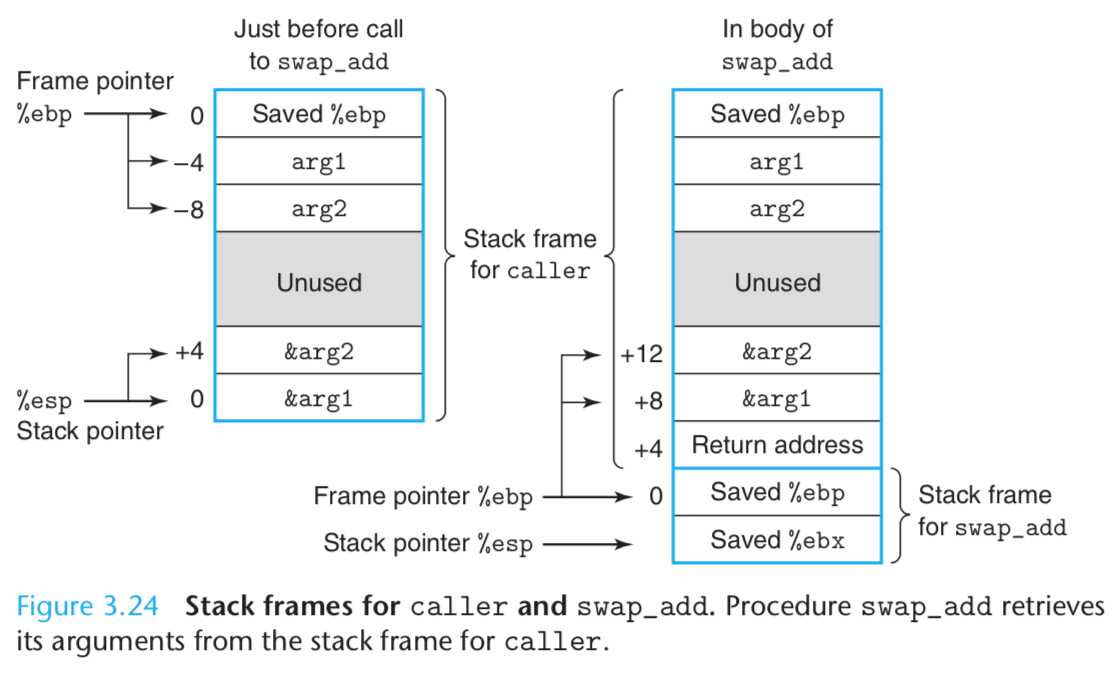
准备调用swap_add之前的代码:

此时,ebp指向顶部,esp指向中部,call之后push return address
要改变ebp之前必须保存,以便之后恢复:
setup code for swap_add:

此时,ebp指向中部,esp指向中部
body code for swap_code:
finishing code for swap_code:

关于这一句ret的影响:
resetting the stack pointer so that it points to the stored return address, so that the ret instruction transfers control back to caller.
code for caller:

leave的影响:
Observe the use of the leave instruction to reset both the stack and the frame pointer prior to return. We have seen in our code examples that the code generated by gcc sometimes uses a leave instruction to deallocate a stack frame, and sometimes it uses one or two popl instructions. Either approach is acceptable。
leave =
![]()
总结:
We can see from this example that the compiler generates code to manage the stack structure according to a simple set of conventions. Arguments are passed to a function on the stack, where they can be retrieved using positive offsets (+8, +12, . . .) relative to %ebp. Space can be allocated on the stack either by using push instructions or by subtracting offsets from the stack pointer. Before returning, a function must restore the stack to its original condition by restoring any callee-saved registers and %ebp, and by resetting %esp so that it points to the return address.
Recursive Procedures :
We can see that calling a function recursively proceeds just like any other function call. Our stack discipline provides a mechanism where each invocation of a function has its own private storage for state information (saved values of the return location, frame pointer, and callee-save registers). If need be, it can also provide storage for local variables. The stack discipline of allocation and deallocation naturally matches the call-return ordering of functions. This method of implementing function calls and returns even works for more complex patterns, including mutual recursion (for example, when procedure P calls Q, which in turn calls P).
Data Alignment :
好处:
Many computer systems place restrictions on the allowable addresses for the primitive data types, requiring that the address for some type of object must be a multiple of some value K (typically 2, 4, or 8). Such alignment restrictions simplify the design of the hardware forming the interface between the processor and the memory system. For example, suppose a processor always fetches 8 bytes from memory with an address that must be a multiple of 8. If we can guarantee that any double will be aligned to have its address be a multiple of 8, then the value can be read or written with a single memory operation. Otherwise, we may need to perform two memory accesses, since the object might be split across two 8-byte memory blocks.
传统:
The IA32 hardware will work correctly regardless of the alignment of data. However, Intel recommends that data be aligned to improve memory system performance. Linux follows an alignment policy where 2-byte data types (e.g., short) must have an address that is a multiple of 2, while any larger data types (e.g., int, int *, float, and double) must have an address that is a multiple of 4. Note that this requirement means that the least significant bit of the address of an object of type short must equal zero. Similarly, any object of type int, or any pointer, must be at an address having the low-order 2 bits equal to zero.
A case of mandatory alignment :
some of the SSE instructions for implementing multimedia operations will not work correctly with unaligned data. These instructions operate on 16-byte blocks of data, and the instructions that transfer data between the SSE unit and memory require the memory addresses to be multiples of 16. Any attempt to access memory with an address that does not satisfy this alignment will lead to an exception.
This is the motivation behind the IA32 convention of making sure that every stack frame is a multiple of 16 bytes long
.align 4
This ensures that the data following it (in this case the start of the jump table) will start with an address that is a multiple of 4. Since each table entry is 4 bytes long, the successive elements will obey the 4-byte alignment restriction.
细节:
Library routines that allocate memory, such as malloc, must be designed so that they return a pointer that satisfies the worst-case alignment restriction for the machine it is running on, typically 4 or 8. For code involving structures, the compiler may need to insert gaps in the field allocation to ensure that each structure element satisfies its alignment requirement. The structure then has some required alignment for its starting address.
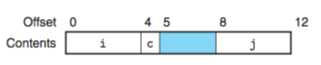
对于:
struct S1{ int i; char c; int j; };
对齐后应为:
对于
struct S2{ int I; int j; char c; };
对齐后应为:

Machine code generated with higher levels of optimization
In our presentation, we have looked at machine code generated with level-one optimization (specified with the command-line option ‘-O1’). In practice, most heavily used programs are compiled with higher levels of optimization. For example, all of the GNU libraries and packages are compiled with level-two optimization, specified with the command-line option ‘-O2’.
Here are some examples of the optimizations that can be found at level two:
-
The control structures become more entangled. Most procedures have multiple return points, and the stack management code to set up and complete a function is intermixed with the code implementing the operations of the procedure.
-
Procedure calls are often inlined, replacing them by the instructions implementing the procedures. This eliminates much of the overhead involved in calling and returning from a function, and it enables optimizations that are specific to individual function calls. On the other hand, if we try to set a breakpoint for a function in a debugger, we might never encounter a call to this function.
Recursion is often replaced by iteration. (Calling a function is often replaced with a process like ‘while‘)
Out-of-Bounds Memory References and Buffer Overflow
We have seen that C does not perform any bounds checking for array references, and that local variables are stored on the stack along with state information such as saved register values and return addresses. This combination can lead to serious program errors, where the state stored on the stack gets corrupted by a write to an out-of-bounds array element. When the program then tries to reload the register or execute a ret instruction with this corrupted state, things can go seriously wrong.
A particularly common source of state corruption is known as buffer overflow. Typically some character array is allocated on the stack to hold a string, but the size of the string exceeds the space allocated for the array. This is demonstrated by the following program example:
1 /* Sample implementation of library function gets() */ 2 char *gets(char *s) 3{ 4 int c; 5 char *dest = s; 6 int gotchar = 0; /* Has at least one character been read? */ 7 while ((c = getchar()) != ’ ’ && c != EOF) { 8 *dest++ = c; /* No bounds checking! */ 9 gotchar = 1; 10 } 11 *dest++ = ’0’; /* Terminate string */ 12 if (c == EOF && !gotchar) 13 return NULL; /* End of file or error */ 14 return s; 15 } /* Read input line and write it back */ void echo() { char buf[8]; /* Way too small! */ gets(buf); puts(buf); }
如图所示:
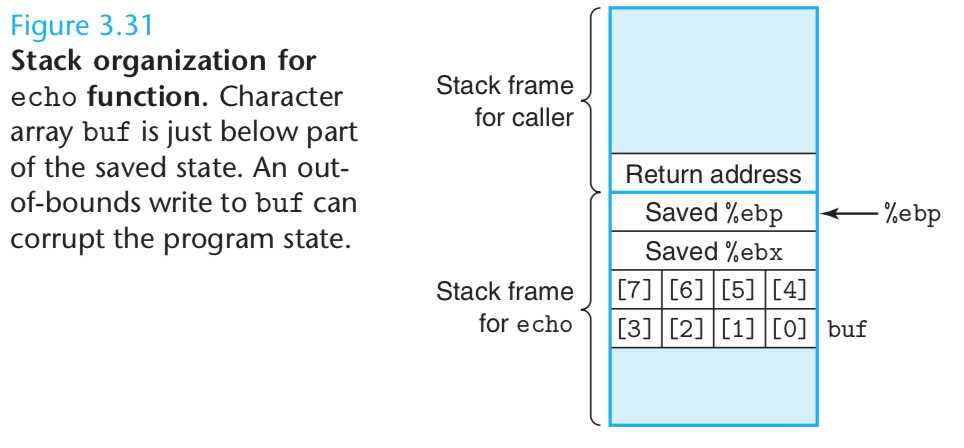
In conclusion:

-
If the stored value of %ebx is corrupted, then this register will not be restored properly in line 12, and so the caller will not be able to rely on the integrity of this register, even though it should be callee-saved.
-
If the stored value of %ebp is corrupted, then this register will not be restored properly on line 13, and so the caller will not be able to reference its local variables or parameters properly.
-
If the stored value of the return address is corrupted, then the ret instruction (line 14) will cause the program to jump to a totally unexpected location.
A better version involves using the function fgets, which includes as an argument a count on the maximum number of bytes to read.
Unfortunately, a number of commonly used library functions, including strcpy, strcat, and sprintf, have the property that they can generate a byte sequence without being given any indication of the size of the destination buffer [94]. Such conditions can lead to vulnerabilities to buffer overflow.
A more pernicious use of buffer overflow is to get a program to perform a function that it would otherwise be unwilling to do. This is one of the most common methods to attack the security of a system over a computer network. Typically, the program is fed with a string that contains the byte encoding of some executable code, called the exploit code, plus some extra bytes that overwrite the return address with a pointer to the exploit code. The effect of executing the ret instruction is then to jump to the exploit code.
攻击原理:
In one form of attack, the exploit code then uses a system call to start up a shell program, providing the attacker with a range of operating system functions. In another form, the exploit code performs some otherwise unauthorized task, repairs the damage to the stack, and then executes ret a second time, causing an (apparently) normal return to the caller.
对策:
Any interface to the external environment should be made “bullet proof” so that no behavior by an external agent can cause the system to misbehave.
Thwarting Buffer Overflow Attacks
1 Stack Randomization
In order to insert exploit code into a system, the attacker needs to inject both the code as well as a pointer to this code as part of the attack string.
核心与实现方法:
The idea of stack randomization is to make the position of the stack vary from one run of a program to another. Thus, even if many machines are running identical code, they would all be using different stack addresses. This is implemented by allocating a random amount of space between 0 and n bytes on the stack at the start of a program, for example, by using the allocation function alloca, which allocates space for a specified number of bytes on the stack. This allocated space is not used by the program, but it causes all subsequent stack locations to vary from one execution of a program to another. The allocation range n needs to be large enough to get sufficient variations in the stack addresses, yet small enough that it does not waste too much space in the program.
举例:

运行结果解释:
Running the code 10,000 times on a Linux machine in 32-bit mode, the addresses ranged from 0xff7fa7e0 to 0xffffd7e0, a range of around 223. By comparison, running on an older Linux system, the same address occurred every time. Running in 64-bit mode on the newer machine, the addresses ranged from 0x7fff00241914 to 0x7ffffff98664, a range of nearly 232.
关于ASLR:
It is one of a larger class of techniques known as address-space layout randomization, or ASLR [95]. With ASLR, different parts of the program, including program code, library code, stack, global variables, and heap data, are loaded into different regions of memory each time a program is run. That means that a program running on one machine will have very different address mappings than the same program running on other machines. This can thwart some forms of attack.
隐忧:
If we set up a 256-byte nop sled, then the randomization over n = 223 can be cracked by enumerating 215 = 32,768 starting addresses, which is entirely feasible for a determined attacker. For the 64-bit case, trying to enumer- ate 224 = 16,777,216 is a bit more daunting. We can see that stack randomization and other aspects of ASLR can increase the effort required to successfully attack a system, and therefore greatly reduce the rate at which a virus or worm can spread, but it cannot provide a complete safeguard.
Stack Corruption Detection
A second line of defense is to be able to detect when a stack has been corrupted.
实现方法:
Recent versions of gcc incorporate a mechanism known as stack protector into the generated code to detect buffer overruns. The idea is to store a special canary value4 in the stack frame between any local buffer and the rest of the stack state, as illustrated in Figure 3.33 [32, 94]. This canary value, also referred to as a guard value, is generated randomly each time the program is run, and so there is no easy way for an attacker to determine what it is. Before restoring the register state and returning from the function, the program checks if the canary has been altered by some operation of this function or one that it has called. If so, the program aborts with an error.
命令细节:
In fact, for our earlier demonstration of stack overflow, we had to give the command-line option “-fno-stack-protector” to prevent gcc from inserting this code.
Limiting Executable Code Regions
非常关键:
A final step is to eliminate the ability of an attacker to insert executable code into a system. One method is to limit which memory regions hold executable code. In typical programs, only the portion of memory holding the code generated by the compiler need be executable. The other portions can be restricted to allow just reading and writing. As we will see in Chapter 9, the virtual memory space is logically divided into pages, typically with 2048 or 4096 bytes per page. The hardware supports different forms of memory protection, indicating the forms of access allowed by both user programs and by the operating system kernel. Many systems allow control over three forms of access: read (reading data from memory), write (storing data into memory), and execute (treating the memory contents as machine-level code).
Combining assembly code with C programs :
原因:
Although a C compiler does a good job of converting the computations we express in a program into machine code, there are some features of a machine that cannot be accessed by a C program.
方法:
There are two ways to incorporate assembly code into C programs. First, we can write an entire function as a separate assembly-code file and let the assembler and linker combine this with code we have written in C. Second, we can use the inline assembly feature of gcc, where brief sections of assembly code can be incorporated into a C program using the asm directive. This approach has the advantage that it minimizes the amount of machine-specific code.
限制:
Of course, including assembly code in a C program makes the code specific to a particular class of machines (such as IA32), and so it should only be used when the desired feature can only be accessed in this way.
以上是关于程序的机器级表示的主要内容,如果未能解决你的问题,请参考以下文章