目标检测算法——YOLOv5/YOLOv7改进之结合ASPP(空洞空间卷积池化金字塔)
Posted 加勒比海带66
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了目标检测算法——YOLOv5/YOLOv7改进之结合ASPP(空洞空间卷积池化金字塔)相关的知识,希望对你有一定的参考价值。

>>>深度学习Tricks,第一时间送达<<<
目录
2.空洞空间卷积池化金字塔(Atrous Spatial Pyramid Pooling)
3.配置yolov5/yolov7_ASPP.yaml文件
一、前沿介绍
首先要介绍Atrous Convolution(空洞卷积),它是一种增加感受野的方法。
1.空洞卷积(Atrous Convolution)
空洞卷积和普通的卷积操作不同的地方在于卷积核中按照一定的规律插入了一些(rate-1)为零的值,使得感受野增加,而无需通过减小图像大小来增加感受野。
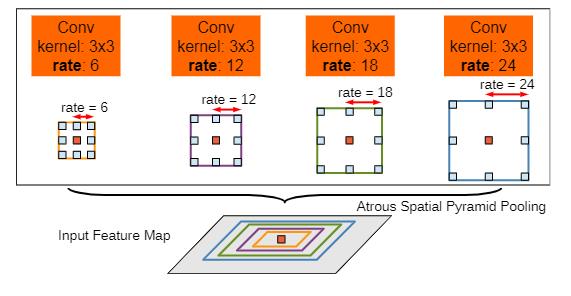
2.空洞空间卷积池化金字塔(Atrous Spatial Pyramid Pooling)
空洞空间卷积池化金字塔(Atrous Spatial Pyramid Pooling,ASPP)对所给定的输入以不同采样率的空洞卷积并行采样,相当于以多个比例捕捉图像的上下文。
二、YOLOv5/YOLOv7改进之结合ASPP
共分三步走:
1.配置common.py文件
#ASPP
class ASPP(nn.Module):
def __init__(self, in_channel=512, out_channel=256):
super(ASPP, self).__init__()
self.mean = nn.AdaptiveAvgPool2d((1, 1)) # (1,1)means ouput_dim
self.conv = nn.Conv2d(in_channel,out_channel, 1, 1)
self.atrous_block1 = nn.Conv2d(in_channel, out_channel, 1, 1)
self.atrous_block6 = nn.Conv2d(in_channel, out_channel, 3, 1, padding=6, dilation=6)
self.atrous_block12 = nn.Conv2d(in_channel, out_channel, 3, 1, padding=12, dilation=12)
self.atrous_block18 = nn.Conv2d(in_channel, out_channel, 3, 1, padding=18, dilation=18)
self.conv_1x1_output = nn.Conv2d(out_channel * 5, out_channel, 1, 1)
def forward(self, x):
size = x.shape[2:]
image_features = self.mean(x)
image_features = self.conv(image_features)
image_features = F.upsample(image_features, size=size, mode='bilinear')
atrous_block1 = self.atrous_block1(x)
atrous_block6 = self.atrous_block6(x)
atrous_block12 = self.atrous_block12(x)
atrous_block18 = self.atrous_block18(x)
net = self.conv_1x1_output(torch.cat([image_features, atrous_block1, atrous_block6,
atrous_block12, atrous_block18], dim=1))
return net2.配置yolo.py文件
加入ASPP模块。

3.配置yolov5/yolov7_ASPP.yaml文件
# anchors
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Focus, [64, 3]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 9, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 1, ASPP, [1024]],
[-1, 3, C3, [1024, False]], # 9
]
# YOLOv5 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]关于算法改进及论文投稿可关注并留言博主的CSDN
>>>一起交流!互相学习!共同进步!<<<
以上是关于目标检测算法——YOLOv5/YOLOv7改进之结合ASPP(空洞空间卷积池化金字塔)的主要内容,如果未能解决你的问题,请参考以下文章
目标检测算法——YOLOv5/YOLOv7改进之结合SPD-Conv(低分辨率图像和小目标涨点明显)
YOLO Air一款面向科研小白的YOLO项目|包含大量改进方式教程|适用YOLOv5,YOLOv7,YOLOX,YOLOv4,YOLOR,YOLOv3,transformer等算法
改进YOLOv7系列:最新结合即插即用CA(Coordinate attention) 注意力机制(适用于YOLOv5),CVPR 2021 顶会助力分类检测涨点!
YOLOv5改进YOLOv7改进IoU损失函数:YOLOv7涨点Trick,改进添加SIoU损失函数EIoU损失函数GIoU损失函数α-IoU损失函数
Yolov5/Yolov7 引入CVPR 2023 BiFormer: 基于动态稀疏注意力构建高效金字塔网络架构,对小目标涨点明显