光学字符识别OCR
Posted zhibei
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了光学字符识别OCR相关的知识,希望对你有一定的参考价值。
光学字符识别(Optical Character Recognition,OCR),是指将图像上的文字转化为计算机可编辑的文字内容。
分析流程:

作为OCR系统的第一步,特征提取是希望找出图像中候选的文字区域特征,以便我们在第二步 进行文字定位和第三步进行识别。在这部分内容中,我们集中精力模仿肉眼对图像与汉字的处理过程,在图像的处理和汉字的定位方面走了一条创新的道路。这部分工作是整个OCR系统最核心的部分,也是我们工作中最核心的部分。
传统的文本分割思路大多数是“边缘检测 + 腐蚀膨胀 + 联通区域检测”,如论文[1]。 然而,在复杂背景的图像下进行边缘检测会导致背景部分的边缘过多(即噪音增加),同时文字部分的边缘 信息则容易被忽略,从而导致效果变差。 如果在此时进行腐蚀或膨胀,那么将会使得背景区域跟文字区域粘合,效果进一步恶化。(事实上,我们在这条路上已经走得足够远了,我们甚至自己写过边缘检测函数来做这个事情,经过很多测试,最终我们决定放弃这种思路。)
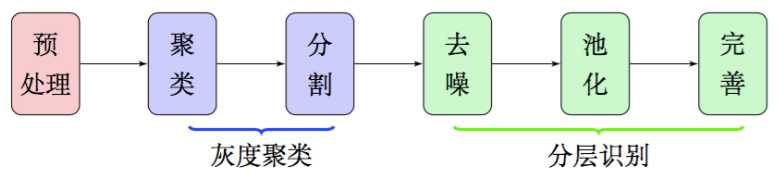
因此,在本文中,我们放弃了边缘检测和腐蚀膨胀,通过聚类、分割、去噪、池化等步骤,得到了比较良好的文字部分的特征,整个流程大致如图2,这些特征甚至可以直接输入到文字识 别模型中进行识别,而不用做额外的处理。由于我们每一部分结果都有相应的理论基础作为支撑,因此能够模型的可靠性得到保证。
在这部分的实验中,我们以图3来演示我们的效果。这个图像的特点是尺寸中等,背景较炫,色彩较为丰富,并且文字跟图片混合排版,排版格式不固定,是比较典型的电商类宣传图片。可以看到,处理这张图片的要点就是如何识别图片区域和文字区域,识别并剔除右端的电饭锅,只保留文字区域。

图像的预处理
首先,我们将原始图片以灰度图像的形式读入,得到一个的灰度矩阵,其中m, n 是图像的长、宽。这样读入比直接读入RGB彩色图像维度更低,同时没有明显损失文字信息。转换为灰度图事实上就是将原来的RGB图像的三个通道以下面的公式整合为一个通道:

图像本身的尺寸不大,如果直接处理,则会导致文字笔画过小,容易被当成噪音处理掉,因此为了保证文字的笔画有一定的厚度,可以先将图片进行放大。在我们的实验中,一般将图像放大为原来的两倍就有比较好的效果了。不过,图像放大之后,文字与背景之间的区分度降低了。这是因为图片放大时会使用插值算法来填补空缺部分的像素。这时候需要相应地增大区分度。经过测试,在大多数图片中,使用次数为2的“幂次变换”效果较好。幂次变换为
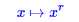
其中x代表矩阵M中的元素,r为次数,在这里我们选取为2。 然后需要将结果映射到[0,255]区间:
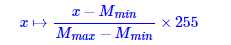
其中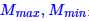 是矩阵的最大值和最小值。 经过这样处理后,图像如下图。
是矩阵的最大值和最小值。 经过这样处理后,图像如下图。

以上是关于光学字符识别OCR的主要内容,如果未能解决你的问题,请参考以下文章
Python,OpenCV中的光学字符识别(OCR Optical Character Recognition)