Lucene初探之数据格式详情
Posted Derrick_gu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Lucene初探之数据格式详情相关的知识,希望对你有一定的参考价值。
Lucene初探之数据格式详情(五)
在前几篇文章中我们了解了索引文件中关于索引的正向信息和反向信息的存储格式。除了正向信息和反向信息之外,还有一种不可或缺的信息也保存在索引文件中–索引因子。
我们在开篇几张中介绍索引的搜索过程时,提到搜索引擎在将用户的查询关键词和倒序索引表进行比对,然后取出所有命中的文档之后,为了将最符合用户预期的文档展示在用户第一眼就看到的地方,需要对文档进行打分,计算文档和用户的query语句之间的相关性权重,权重越高的文档会越往前排序。在进行相关性权重打分计算的时候,我们使用的是向量空间模型对文档进行相关性打分,在计算相关性之前,需要先计算Term weight,这表示一个term相对其所对应的文档的重要性。
在计算Term weight时,主要有两个影响因素,一个是此Term在此文档中出现的次数,还有一个是此Term在所有文档中的出现频次,也就是普通程度。一个Term在文档中出现的次数越多,则其相对于此文档的重要性越高。
这种Term weight计算方式是最普通的计算方式,其存在以下几个问题:
- 不同的文档重要性不同,有的文档重要一点,有的文档不是那么重要,比如对于一个软件相关的行业的用户,可能他想要和软件相关的文档排在前面一点,而和文学相关的文档排在后面一点;再比如对于一家旅游网站而言,搜索出来的信息应该都是和旅游相关的排在最前面,而其他一些无关紧要的其他行业的文档在搜索结果中排在后面一点。
- 不同的域重要性不同,有的域重要一点,比如标题,关键词,tag标签等,而有的域则相关不是那么重要,或者说是无关紧要,比如附件等。同一个词,其出现在标题中绝对比出现在文末的结尾一句话中要重要得多。
- 根据词在文档中出现的频次来进行Term weight打分,其中一个不合理的地方在于:篇幅长的文档相比篇幅短的文档而言计算词在文档中出现的次数时要占有优势。
由于以上的一些缺陷和一些其他的考量因素,Lucene在计算Term weight时会乘上一个标准因子来减少上面三个因素的影响。
标准化因子对打分计算有直接的影响,Lucene的打分计算的过程一部分是发生在索引的过程中,包括标准化因子,另一部分发生在搜索的过程中,后面我们会有详细的讲解。
标准化因子在索引的过程中总的计算如下:

其中:
- Document boost:此值越大,说明此文档的重要性越高;
- Field boost:此值越大,说明此域越重要;
- lengthNorm(field) = 1.0/Math.sqrt(numTerms);一个域中包含的Term总数越多,也就是文档篇幅越长,此值越小;
从上面的公式中,我们可以知道,一个词在不同的文档和不同的域中的重要性不同。
比如有两个文档,每个文档两个域,忽略掉文档的长度的话,它们的组合有四种:重要文档的重要域,重要文档的非重要域……每种组合的标准化因子不同。
Lucene中的标准化因子一共保存了(DocumentNum * FieledNum)种,其格式如下:
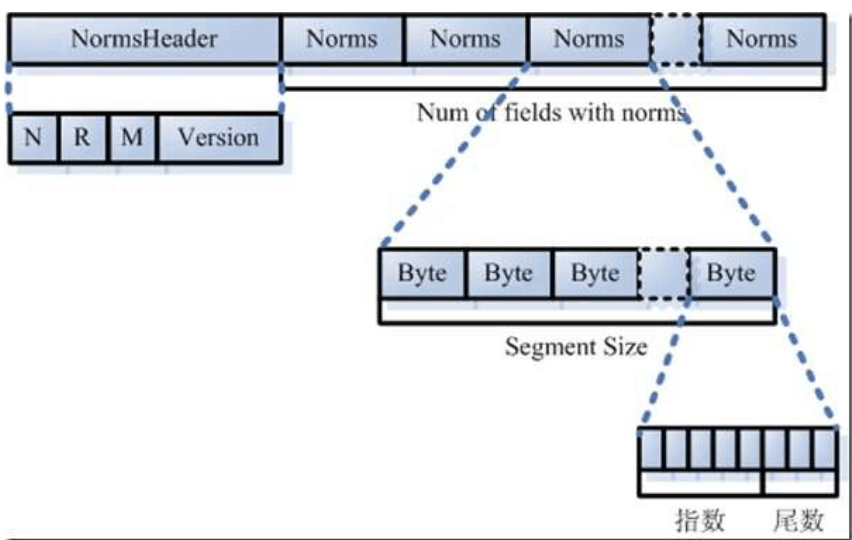
- 标准化因子文件:nrm
-NormsHeader:字符串“NRM” 外加version;
-NumField个Norms,一个域对应一项;
-Norms本身是一个byte数组,个数为segment size,其每一个Byte表示一个浮点数;
以上是关于Lucene初探之数据格式详情的主要内容,如果未能解决你的问题,请参考以下文章