全闪分布式,如何深度性能POC?
Posted 刘爱贵
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了全闪分布式,如何深度性能POC?相关的知识,希望对你有一定的参考价值。
全闪存储已经成为当前存储的新贵,从存储架构的演变角度,软件定义的分布式存储系统替代传统控制器架构的磁盘阵列已是大势所趋。采用分布式架构的全闪存储系统能充分发挥闪存介质的性能,并构建具备云属性的弹性基础设施,是未来全闪存储系统的发展方向。FASS是TaoCloud自研的全闪分布式块存储系统,产品正式发布以来进行了大量多种场景的POC测试,这里将对典型场景的POC测试进行多角度对比分析,用数据验证FASS在不同硬件配置环境下的优异性能表现。
POC性能测试拓扑模型
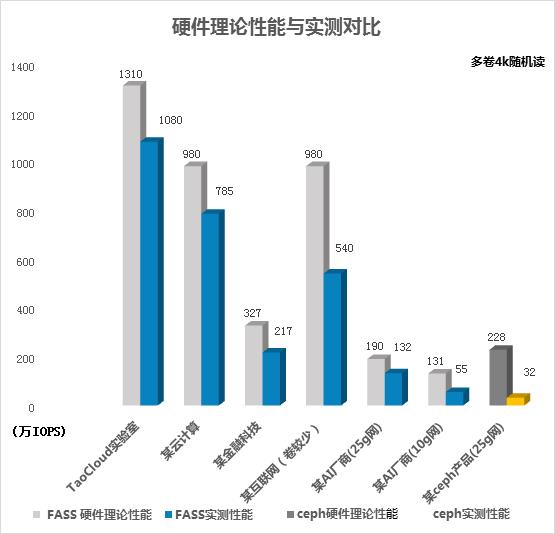
典型场景POC实测对比
实测中FASS可发挥出更多的理论性能:
·在公司实测试中发挥出理论性能的82%;
·在某互联网测试中,因卷较少,未到最佳性能,发挥出55%理论性能;
·在某AI厂商测试中,某Ceph产品(基于RBD)可达到32万IOPS,FASS在少4块SSD盘情况下,达到132万IOPS,IOPS相差4倍之多。
FASS实测最佳性能可达理论80%以上,Ceph发挥出硬件性能的14%左右。
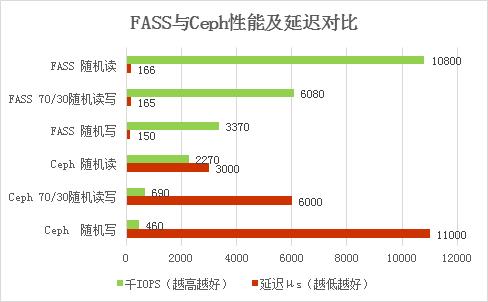
FASS与Ceph性能对比
Ceph是SDS业内较为成熟的解决方案,但是受限于架构设计等原因,Ceph在全闪环境下具有明显的性能瓶颈。
下图是3节点的FASS和优化后的Ceph对比测试:
·可以看出IOPS有5倍~9倍的差异;
·延迟更有18~73倍的差异;
·FASS性能更优于Ceph,拥有更高IOPS,更低延迟。
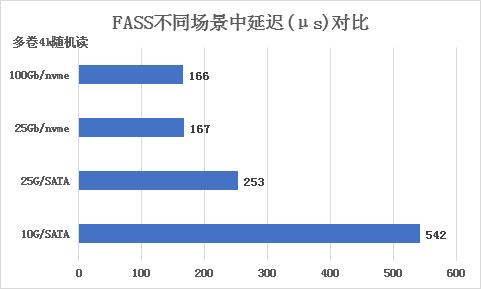
FASS超低延迟:
FASS采用并行流水线设计,将读写I/O均匀分布在各节点的多个CPU核心进行高效的并行协作处理,从而实现了在分布式体系下微秒级的极低时延响应。
如下图,在不同的硬件场景中,延迟均有优异的表现。
·在25G及以上网络,nvme盘环境下,延迟在200μs以内;
·在万兆网络SATA盘中,只有542μs的延迟。
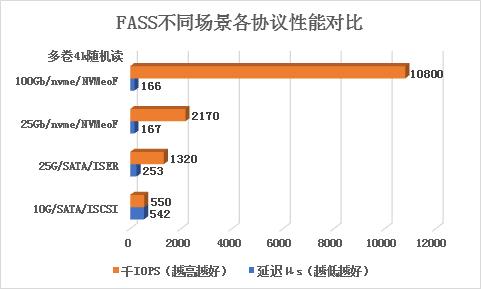
FASS丰富协议
在FASS不同的场景中,支持多种协议,不同的协议有不同的性能表现。
·FASS支持标准iSCSI块存储协议和高性能iSER访问,采用RoCE协议来实现iSER访问;
·FASS目前采用RDMA Transport(Infiniband或 RoCE v2)实现NVMeoF协议访问。
如下图,100Gb/nvme/NVMeoF场景,可达到千万级IOPS,同时具有超低延迟特性仅为166μs。
FASS 特点
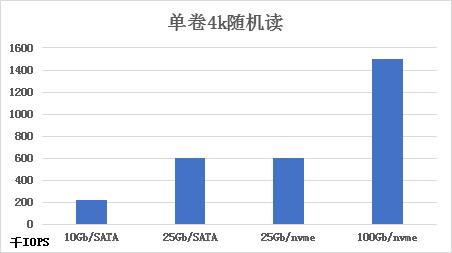
单卷性能
在FASS不同的硬件环境中,单卷性能均能发挥出超高的性能。
随着硬件环境的提升,单卷的极限性能也呈线性增长;
在100Gb网络环境中,单卷可达150万IOPS。
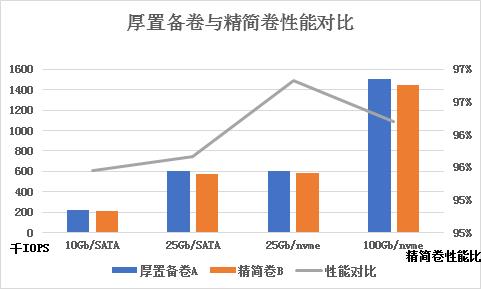
精简卷性能
FASS精简卷与厚置备卷性能相当,精简卷性能损耗不超过5%。
精简卷更可以按需扩容,利于弹性拓展容量而不需提前规划未来容量,更加节约成本。
QoS & 流控
FASS支持卷、集群级别的QoS流控,可灵活控制IOPS或带宽上限。
集群QoS可设置:优先数据修复(recovery全速)或者优先业务(recovery 限速)
Recovery性能爬升
FASS recovery性能爬升较快,对业务io影响小。
如下图实例,FASS的Recovery的性能爬升时间可控制在30秒以内。

管理工具多种多样
FASS支持CLI(命令行管理接口)、REST API、Web GUI、FASS-CSI(对接Kubernetes平台)对整个存储集群进行资源配置、访问控制、数据保护、性能监控等多方面的管理。
FASS 最佳性能关键点
硬件选型
· CPU:频率2.60GHz,L3缓存, 24MB,16core
· 网络:25Gb及以上
· 磁盘:SATA SSD或NVMe SSD
· 内存:128G
系统配置
· 开启NUMA,关闭超线程
· 开启CPU性能模式
· 如用raid卡模式,必须带BBU
· 操作系统:CentOS 7.6 Release版
· 节点需配置节点hostname、/etc/hosts文件、互免密
· 关闭selinux及防火墙
软件相关
· CPU coremask :由cpu核数进行合理配置
· 压力卷数量:Client数量*6
· 网络数量:管理网*1,前端网*2,后端网*2
· 虚拟Vip数量:server数量=虚拟vip数量
本文主要是抛砖引玉,通过POC实测数据对比,与Ceph产品对比等几方面进行分析,体现出FASS具有高灵活性、丰富拓展性,超高性能、极低延迟的特性,FASS无论从性能、性价比等都极具优势。
(TaoCloud团队原创)
以上是关于全闪分布式,如何深度性能POC?的主要内容,如果未能解决你的问题,请参考以下文章