BloomFilter怎么用?使用布隆过滤器来判断key是否存在?
Posted 你个佬六
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了BloomFilter怎么用?使用布隆过滤器来判断key是否存在?相关的知识,希望对你有一定的参考价值。
一、前言
今天跟一个同事聊了一个问题,说最近在做推荐,如何判断用户是否看过这个片段呢?想了一下,正好可以使用布隆过滤器来完成这个需求。
布隆,可不是LOL的布隆。我们的这个布隆是一个叫布隆的外国人,在1970年提出的一种方案:如果判断这个key不存在,那么就一定不存在,如果key存在,那么有可能不存在。所以不存在的时候,你永远可以详细布隆。

二、布隆的原理是什么?
布隆过滤器是一个高空间利用率的概率性数据结构,由Burton Bloom于1970年提出,用于测试一个元素是否在集合中。
新创建的布隆过滤器是一串被置为0的Bit数组(假设有m位),同时声明k个不同的Hash函数生成统一的随机分布(k是一个小于m的常数)。
插入数据
向布隆过滤器中添加元素时,通过k个Hash函数将元素映射到Bit中的k个点,并将这些位置的值设置为1,一个Bit位可能被不同数据共享。下图展示了假设布隆过滤器的k为3,向其插入X1、X2的过程。

查询
查询元素时,仍通过k个Hash函数得到对应的k个位,判断目标位置是否为1,若目标位置全为1则认为该元素在布隆过滤器内,否则认为该元素不存在,下图展示了在布隆过滤器中查询Y1和Y2是否存在的过程。
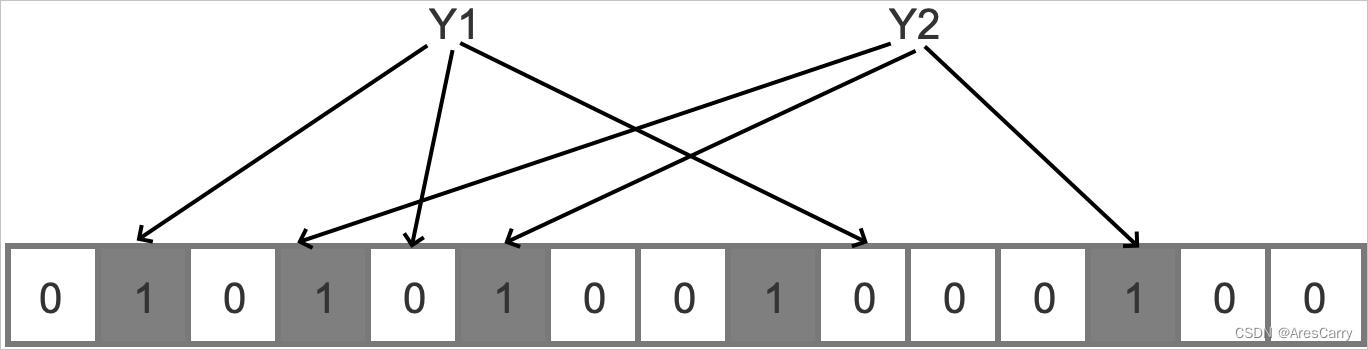
查询y1y2
由上图可以发现,虽然从未向布隆过滤器中插入过Y2这个元素,但是布隆过滤器却判断Y2存在,因此,布隆过滤器是可能存在误判的,即存在假阳性(false positive)。至此,可以得出关于布隆过滤器的几个特性:
- Bit位可能被不同数据共享。
- 存在假阳性(false positive),且布隆过滤器中的元素越多,假阳性的可能性越大,但不存在假阴性(false negative),即不会将存在的元素误判为不存在。
- 元素可以被加入布隆过滤器,但无法被删除,因为Bit位是可以共享的,删除时有可能会影响到其他元素。
- 要判断的数据量越大,占用内存越大。
- 容错率越低,内存越大,因为bit位要更多一些。
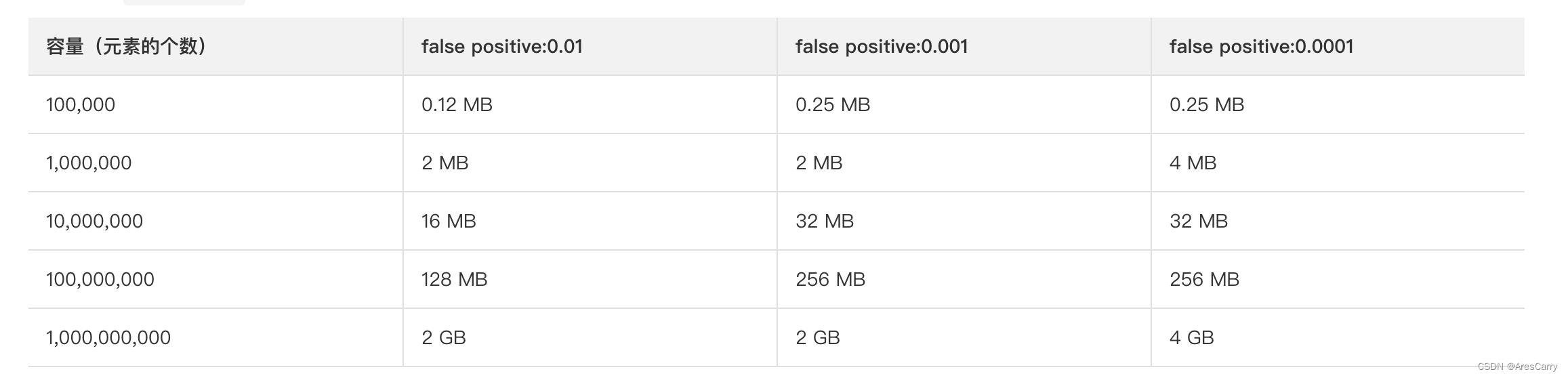
优化
鉴于布隆过滤器会越用越大,我们可以给出几点建议:
- 做好业务拆分,建立多个布隆过滤器,各个业务用相对应的。
这样做的好处是,可以防止数据增长,导致key过大,影响性能,同时也不好扩展,毕竟redis或者内存大小是有上限的。另外的好处就是可以均衡请求,可以防止请求都打到一个节点,造成热点key,访问倾斜。
- 定期重置,定期重建
如果业务允许,我们可以清空数据,从新统计数据。
三、代码实现
简单的HashMap实现
首先我们自己定义一个长度固定的数组,然后通过两次hash,计算出数据值,再和array的size取余,更新对应字段为1,这样做会有很多的容错,这个容错率跟我们的数组长度有关,而且跟我们进行hash的次数有关系。所以要根据业务选择。
另外就是,这个是单节点的,存在我们的机器jvm内存,如果我们重启服务,数据就消失了。
package com.ares.bloom;
public class BloomFilter
/** * 数组长度 */
private int size;
/** * 数组 */
private int[] array;
public BloomFilter(int size)
this.size = size;
this.array = new int[size];
/** * 添加数据 */
public void add(String item)
int firstIndex = func1(item);
int secondIndex = func2(item);
array[firstIndex % size] = 1;
array[secondIndex % size] = 1;
/** * 判断数据 item 是否存在集合中 */
public boolean contains(String item)
int firstIndex = func1(item);
int secondIndex = func2(item);
int firstValue = array[firstIndex % size];
int secondValue = array[secondIndex % size];
return firstValue != 0 && secondValue != 0;
/** * hash 算法 func1 */
private int func1(String key)
int hash = 7;
System.out.println(hash);
hash += 61 * hash + key.hashCode();
System.out.println(hash);
hash ^= hash >> 15;
System.out.println(hash);
hash += hash << 3;
System.out.println(hash);
hash ^= hash >> 7;
System.out.println(hash);
hash += hash << 11;
System.out.println(hash);
return Math.abs(hash);
/** * hash 算法 func2 */
private int func2(String key)
int hash = 7;
for (int i = 0, len = key.length(); i < len; i++)
hash += key.charAt(i);
hash += (hash << 7);
hash ^= (hash >> 17);
hash += (hash << 5);
hash ^= (hash >> 13);
return Math.abs(hash);
public static void main(String[] args)
BloomFilter filter = new BloomFilter(10000);
System.out.println(filter.contains("1"));
System.out.println(filter.contains("2"));
filter.add("1");
System.out.println(filter.contains("1"));
filter.add("2");
System.out.println("---------------------------------");
System.out.println(filter.contains("2"));
结果:
/Library/Java/JavaVirtualMachines/jdk1.8.0_261.jdk/Contents/Home/bin/java -agentlib:jdwp=transport=dt_socket,address=127.0.0.1:60696,suspend=y,server=n -javaagent:/Users/apple/Library/Caches/JetBrains/IntelliJIdea2020.1/captureAgent/debugger-agent.jar -Dfile.encoding=UTF-8 -classpath /private/var/folders/5b/_717vl_x3d1dx5jx8512k7300000gn/T/classpath2097007646.jar com.ares.bloom.BloomFilter
Connected to the target VM, address: '127.0.0.1:60696', transport: 'socket'
7
483
483
4347
4314
8839386
false
7
484
484
4356
4390
8995110
false
7
483
483
4347
4314
8839386
7
483
483
4347
4314
8839386
true
7
484
484
4356
4390
8995110
---------------------------------
7
484
484
4356
4390
8995110
true
Disconnected from the target VM, address: '127.0.0.1:60696', transport: 'socket'
Process finished with exit code 0
使用Google开源的Guava自带布隆过滤器
Guava 提供了自带的布隆过滤器,而且有相关的参数可以配置,可以更好的实现。
但是Guava还是基于单台机器的,在分布式架构上就不通用了。
引入依赖
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>31.0.1-jre</version>
</dependency>
demo:
package com.ares.bloom;
import com.google.common.base.Charsets;
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
import lombok.extern.slf4j.Slf4j;
import java.text.NumberFormat;
import java.util.ArrayList;
import java.util.List;
import java.util.UUID;
@Slf4j
public class GravaBloomTest
public static void main(String[] args)
intBloom();
stringBloom();
public static void intBloom()
Integer count = 5000000;
BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), count,0.01);
for (int i = 0; i < count; i++)
bloomFilter.put(i);
long begin = System.currentTimeMillis();
if (bloomFilter.mightContain(50000))
log.info("成功过滤到 50000");
long end = System.currentTimeMillis();
log.info("布隆过滤器消耗时间"+(end - begin)/1000000L+"毫秒");
public static void stringBloom()
BloomFilter<String> bloomFilter = BloomFilter.create(Funnels.stringFunnel(Charsets.UTF_8),5000000,0.01);
List<String> list = new ArrayList<>(5000000);
for (int i = 0; i < 5000000; i++)
String uuid = UUID.randomUUID().toString();
bloomFilter.put(uuid);
list.add(uuid);
int mightContainNumber1= 0;
NumberFormat percentFormat = NumberFormat.getPercentInstance();
percentFormat.setMaximumFractionDigits(2);
for (int i=0;i < 500;i++)
String key = list.get(i);
if (bloomFilter.mightContain(key))
mightContainNumber1++;
log.info("【key真实存在的情况】布隆过滤器认为存在的key值数:" + mightContainNumber1);
log.info("================================================================================");
int mightContainNumber2 = 0;
for (int i=0;i < 5000000;i++)
String key = UUID.randomUUID().toString();
if (bloomFilter.mightContain(key))
mightContainNumber2++;
log.info("【key不存在的情况】布隆过滤器认为存在的key值数:" + mightContainNumber2);
log.info("【key不存在的情况】布隆过滤器的误判率为:" + percentFormat.format((float)mightContainNumber2 / 5000000));
结果:
从结果可以看到,从500万的数据中判断一个key是否存在时间还是很快的,而且我们知道, String key = UUID.randomUUID().toString(); uuid 每次生成都是不一样的,我们在第二次处理的时候,发现,我们用已经存在的去查,肯定是可以查到的。我们用不存在的差,设置了1%的误差,所以就会有50636命中了存在。这个也是因为,他们hash碰撞到了一个位上。
/Library/Java/JavaVirtualMachines/jdk1.8.0_261.jdk/Contents/Home/bin/java -agentlib:jdwp=transport=dt_socket,address=127.0.0.1:63708,suspend=y,server=n -javaagent:/Users/apple/Library/Caches/JetBrains/IntelliJIdea2020.1/captureAgent/debugger-agent.jar -Dfile.encoding=UTF-8 -classpath /private/var/folders/5b/_717vl_x3d1dx5jx8512k7300000gn/T/classpath815744853.jar com.ares.bloom.GravaBloomTest
Connected to the target VM, address: '127.0.0.1:63708', transport: 'socket'
22:31:31.060 [main] INFO com.ares.bloom.GravaBloomTest - 成功过滤到 50000
22:31:31.062 [main] INFO com.ares.bloom.GravaBloomTest - 布隆过滤器消耗时间0毫秒
22:31:48.839 [main] INFO com.ares.bloom.GravaBloomTest - 【key真实存在的情况】布隆过滤器认为存在的key值数:5000000
22:31:48.839 [main] INFO com.ares.bloom.GravaBloomTest - ================================================================================
22:31:53.642 [main] INFO com.ares.bloom.GravaBloomTest - 【key不存在的情况】布隆过滤器认为存在的key值数:50636
22:31:53.642 [main] INFO com.ares.bloom.GravaBloomTest - 【key不存在的情况】布隆过滤器的误判率为:1.01%
Disconnected from the target VM, address: '127.0.0.1:63708', transport: 'socket'
Process finished with exit code 0
分布式处理——用redis实现布隆过滤器
前面我们用的都是单台机器内存上的布隆过滤器,我们要用到分布式,就要用到redis来处理了。如果用redis的布隆,
首先,如果我们没有钱,自己搭建的redis
我们需要安装插件:
1、点击https://redis.io/modules 找到RedisBloom
2、点击进去下载RedisBloom-master.zip文件,上传到linux
3、解压缩刚才的RedisBloom文件
unzip RedisBloom-master.zip
cd RedisBloom-master
编译安装
make
make完生成redisbloom.so,拷贝到redis的安装目录。
cp redisbloom.so /home/www/server/redis
在redis.conf配置文件中加入如RedisBloom的redisbloom.so文件的地址,如果是集群则每个配置文件中都需要加入redisbloom.so文件的地址
loadmodule /home/www/server/redis/redisbloom.so
保存以后重启redis服务
redis-server redis.conf --loadmodule /home/www/server/redis/redisbloom.so
上面我们有提到需要重启Redis,在本地和测试环境还可以,但是正式环境能不重启就不需要重启,那这么做可以不重启Redis,使用module load命令执行。
> MODULE LOAD /home/www/server/redis/redisbloom.so
> module list
1) 1) "name"
2) "bf"
3) "ver"
4) (integer) 999999
看到以上数据则说明redisbloom加载成功了,模块名name为"bf",模块版本号ver为999999。
pom中引入redisson依赖:
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
<version>3.13.1</version>
</dependency>
demo:
public void patchingConsum(ConsumPatchingVO vo) throws ParseException
Config config = new Config();
SingleServerConfig singleServerConfig = config.useSingleServer();
singleServerConfig.setAddress("redis://127.0.0.1:6379");
singleServerConfig.setPassword("123456");
RedissonClient redissonClient = Redisson.create(config);
RBloomFilter<String> bloom = redissonClient.getBloomFilter("name");
// 初始化布隆过滤器; 大小:100000,误判率:0.01
bloom.tryInit(100000L, 0.01);
// 新增10万条数据
for(int i=0;i<100000;i++)
bloom.add("name" + i);
以上是关于BloomFilter怎么用?使用布隆过滤器来判断key是否存在?的主要内容,如果未能解决你的问题,请参考以下文章
REDIS11_布隆过滤器BloomFilter的概述优缺点使用场景底层原理布谷鸟过滤器
REDIS11_布隆过滤器BloomFilter的概述优缺点使用场景底层原理布谷鸟过滤器
REDIS07_布隆过滤器BloomFilter的概述优缺点使用场景底层原理布谷鸟过滤器