Redis 高级主题之布隆过滤器(BloomFilter)
Posted 天澄技术杂谈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis 高级主题之布隆过滤器(BloomFilter)相关的知识,希望对你有一定的参考价值。
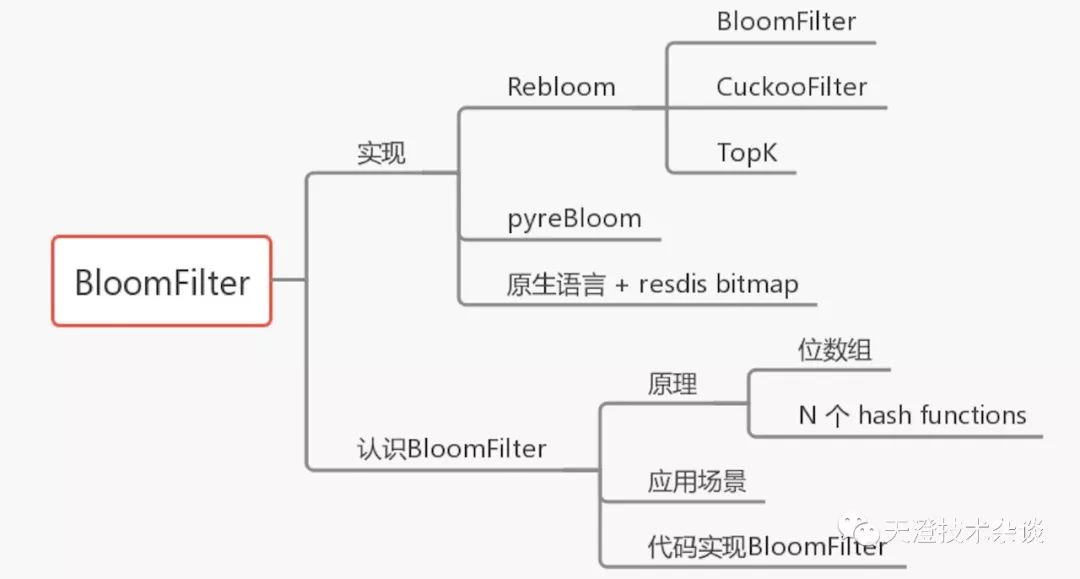
最近计划准备整理几篇关于Reids高级主题的博文,本文整理的是关于布隆过滤器在Redis中如何应用,先来一张思维导图浏览全文。
1. 认识BloomFilter
1.1 原理
布隆过滤器,英文叫BloomFilter,可以说是一个二进制向量和一系列随机映射函数实现。 可以用于检索一个元素是否在一个集合中。
下面来看看布隆过滤器是如何判断元素在一个集合中,如下图:
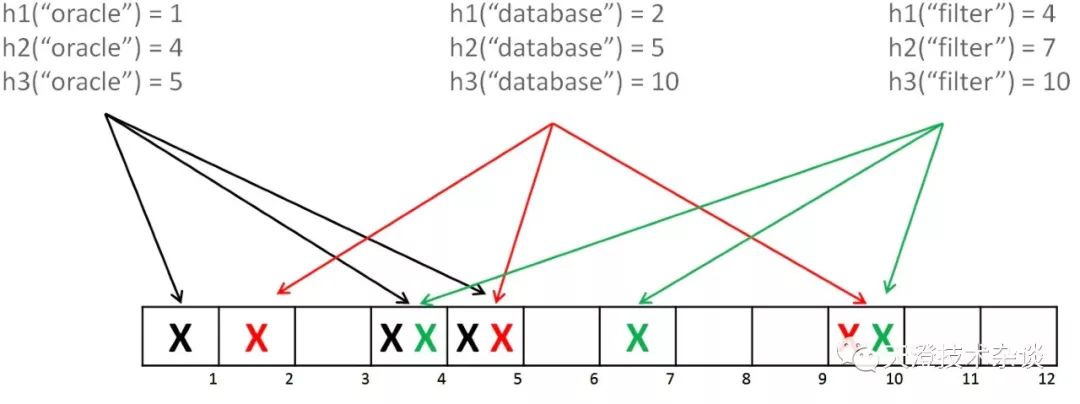
有三个hash函数和一个位数组,oracle经过三个hash函数,得到第1、4、5位为1,database同理得到2、5、10位1,这样如果我们需要判断oracle是否在此位数组中,则通过hash函数判断位数组的1、4、5位是否均为1,如果均为1,则判断oracle在此位数组中,database同理。这就是布隆过滤器判断元素是否在集合中的原理。
想必聪明的读者已经发现,如果bloom经过三个hash算法,需要判断 1、5、10位是否为1,恰好因为位数组中添加oracle和database导致1、5、10为1,则布隆过滤器会判断bloom会判断在集合中,这不是Bug吗,导致误判。但是可以保证的是,如果布隆过滤器判断一个元素不在一个集合中,那这个元素一定不会在集合中。
是的,这个是布隆过滤器的缺点,有一点的误识别率,但是布隆过滤器有2大优点,使得这个缺点在某些应用场景中是可以接受的,2大优点是空间效率和查询时间都远远高于一般的算法。常规的数据结构set,也是经过被用于判断一个元素是否在集合中,但如果有上百万甚至更高的数据,set结构所占的空间将是巨大的,布隆过滤器只需要上百万个位即可,10多Kb即可。
导致这个缺点是因为hash碰撞,但布隆过滤器通过多个hash函数来降低hash碰撞带来的误判率,如下图:
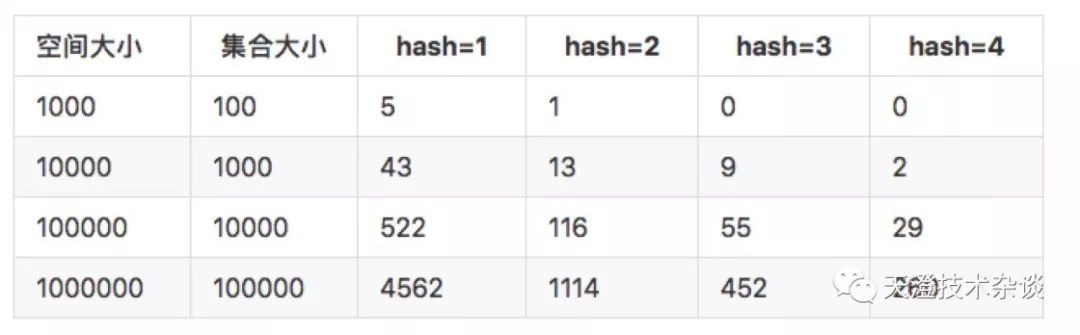
当只有1个hash函数的时候,误判率很高,但4个hash函数的时候已经缩小10多倍,可以动态根据业务需求所允许的识别率来调整hash函数的个数,当然hash函数越多,所带来的空间效率和查询效率也会有所降低。
第二个缺点相对set来说,不可以删除,因为布隆过滤器并没有存储key,而是通过key映射到位数组中。
总结,敲黑板:
布隆过滤器是用于判断一个元素是否在集合中。通过一个位数组和N个hash函数实现。
优点:
空间效率高,所占空间小。
查询时间短。
缺点:
元素添加到集合中后,不能被删除。
有一定的误判率
1.2 应用场景
数据库防止穿库。 Google Bigtable,HBase 和 Cassandra 以及 Postgresql 使用BloomFilter来减少不存在的行或列的磁盘查找。避免代价高昂的磁盘查找会大大提高数据库查询操作的性能。
业务场景中判断用户是否阅读过某视频或文章,比如抖音或头条,当然会导致一定的误判,但不会让用户看到重复的内容。还有之前自己遇到的一个比赛类的社交场景中,需要判断用户是否在比赛中,如果在则需要更新比赛内容,也可以使用布隆过滤器,可以减少不在的用户查询db或缓存的次数。
缓存宕机、缓存击穿场景,一般判断用户是否在缓存中,如果在则直接返回结果,不在则查询db,如果来一波冷数据,会导致缓存大量击穿,造成雪崩效应,这时候可以用布隆过滤器当缓存的索引,只有在布隆过滤器中,才去查询缓存,如果没查询到,则穿透到db。如果不在布隆器中,则直接返回。
WEB拦截器,如果相同请求则拦截,防止重复被攻击。用户第一次请求,将请求参数放入布隆过滤器中,当第二次请求时,先判断请求参数是否被布隆过滤器命中。可以提高缓存命中率。
1.3 动手实现布隆过滤器
根据布隆过滤器的原理,来用 Python 手动实现一个布隆过滤器。
首先需要安装 mmh3,mmh3是 MurmurHash3 算法的实现,Redis 中也是采用此hash算法。然后还需要安装 bitarray,Python 中位数组的实现。
pip install mmh3
pip install bitarray
准备好环境后,开始实现布隆过滤器,直接上代码
# python 3.6 simple_bloomfilter.py
import mmh3
from bitarray import bitarray
class BloomFilter(object):
def __init__(self, bit_size=10000, hash_count=3, start_seed=41):
self.bit_size = bit_size
self.hash_count = hash_count
self.start_seed = start_seed
self.initialize()
def initialize(self):
self.bit_array = bitarray(self.bit_size)
self.bit_array.setall(0)
def add(self, data):
bit_points = self.get_hash_points(data)
for index in bit_points:
self.bit_array[index] = 1
def is_contain(self, data):
bit_points = self.get_hash_points(data)
result = [self.bit_array[index] for index in bit_points]
return all(result)
def get_hash_points(self, data):
return [
mmh3.hash(data, index) % self.bit_size
for index in range(self.start_seed, self.start_seed + self.hash_count)]
完整代码均记录在 https://github.com/fuzctc/tc-redis-practice
上述代码中实现了BloomFilter类,初始化三个变量,bit_size 位数组的大小,hash_count Hash函数的数量,start_seed 起始hash随机种子数。
实现了2个方法,add 方法是根据data经过多个hash函数得到不同的bit位,将位数组中相关位置1,is_contain是判断data是否在BloomFilter中。
测试一下代码:
>>> from simple_bloomfilter import BloomFilter
>>> bloomFilter = BloomFilter(1000000, 6)
>>> bloomFilter.add('databases')
>>> bloomFilter.add('bloomfilter')
>>> bloomFilter.is_contain('databases')
True
>>> bloomFilter.is_contain('bloomfilter')
True
>>> bloomFilter.is_contain('bloomfilte')
False
测试BloomFilter功能有效,但是实际在生产过程中,存储的量级非常大,通常采用redis的bitmap数据结构来代替自己实现的位数组,下面来实践一下在Redis中如何使用布隆过滤器。
2. Redis-BloomFilter实践
Redis在4.0版本推出了 module 的形式,可以将 module 作为插件额外实现Redis的一些功能。官网推荐了一个 RedisBloom 作为 Redis 布隆过滤器的 Module。
除了这个还有别的方式可以实现,下面一一列举一下:
RedisBloom - Bloom Filter Module for Redis
pyreBloom
lua脚本来实现 redis-lua-scaling-bloom-filter
原生语言,调用 Redis 的 bitmap 相关操作来实现
下面一一来实践一下。
2.1 RedisBloom
RedisBloom需要先进行安装,推荐使用Docker进行安装,简单方便:
docker pull redislabs/rebloom:latest
docker run -p 6379:6379 --name redis-redisbloom redislabs/rebloom:latest
docker exec -it redis-redisbloom bash
# redis-cli
# 127.0.0.1:6379> bf.add tiancheng hello
当然也可以直接编译进行安装:
git clone https://github.com/RedisBloom/RedisBloom.git
cd RedisBloom
make //编译 会生成一个rebloom.so文件
redis-server --loadmodule /path/to/rebloom.so
redis-cli -h 127.0.0.1 -p 6379
此模块不仅仅实现了布隆过滤器,还实现了 CuckooFilter(布谷鸟过滤器),以及 TopK 功能。CuckooFilter 是在 BloomFilter 的基础上主要解决了BloomFilter不能删除的缺点。先来看看 BloomFilter,后面介绍一下 CuckooFilter。
2.1.1 BloomFilter 相关操作
先来熟悉一下布隆过滤器基本指令:
bf.add 添加元素到布隆过滤器
bf.exists 判断元素是否在布隆过滤器
bf.madd 添加多个元素到布隆过滤器,bf.add只能添加一个
bf.mexists 判断多个元素是否在布隆过滤器
127.0.0.1:6379> bf.add tiancheng tc01
(integer) 1
127.0.0.1:6379> bf.add tiancheng tc02
(integer) 1
127.0.0.1:6379> bf.add tiancheng tc03
(integer) 1
127.0.0.1:6379> bf.exists tiancheng tc01
(integer) 1
127.0.0.1:6379> bf.exists tiancheng tc02
(integer) 1
127.0.0.1:6379> bf.exists tiancheng tc03
(integer) 1
127.0.0.1:6379> bf.exists tiancheng tc04
(integer) 0
127.0.0.1:6379> bf.madd tiancheng tc05 tc06 tc07
1) (integer) 1
2) (integer) 1
3) (integer) 1
127.0.0.1:6379> bf.mexists tiancheng tc05 tc06 tc07 tc08
1) (integer) 1
2) (integer) 1
3) (integer) 1
4) (integer) 0
2.1.2 测试误判率
接下来来测试一下误判率:
import redis
client = redis.StrictRedis()
client.delete("tiancheng")
size = 100000
count = 0
for i in range(size):
client.execute_command("bf.add", "tiancheng", "tc%d" % i)
result = client.execute_command("bf.exists", "tiancheng", "tc%d" % (i + 1))
if result == 1:
# print(i)
count += 1
print("size: {} , error rate: {}%".format(
size, round(count / size * 100, 5)))
测试结果如下:
➜ BloomFilter git:(master) ✗ python redisbloom_test.py
size: 1000 , error rate: 1.0%
➜ BloomFilter git:(master) ✗ python redisbloom_test.py
size: 10000 , error rate: 1.25%
➜ BloomFilter git:(master) ✗ python redisbloom_test.py
size: 100000 , error rate: 1.304%
size=1000,就出现1%的误判率,size越高误判率会越高,那有没有办法控制误判率了,答案是有的。
实际上布隆过滤器是提供自定义参数,之前都是使用默认的参数,此模块还提供了一个命令bf.reserve,提供了三个参数, key, error_rate和initial_size。错误率越低,需要的空间越大,initial_size参数表示预计放入布隆过滤器的元素数量,当实际数量超出这个数值时,误判率会上升。 默认的参数是 error_rate=0.01, initial_size=100。
接下来测试一下:
import redis
client = redis.StrictRedis()
client.delete("tiancheng")
size = 10000
count = 0
client.execute_command("bf.reserve", "tiancheng", 0.001, size) # 新增
for i in range(size):
client.execute_command("bf.add", "tiancheng", "tc%d" % i)
result = client.execute_command("bf.exists", "tiancheng", "tc%d" % (i + 1))
if result == 1:
#print(i)
count += 1
print("size: {} , error rate: {}%".format(
size, round(count / size * 100, 5)))
新增一行代码,简单测试一下效果:
➜ BloomFilter git:(master) ✗ python redisbloom_test.py
size: 10000 , error rate: 0.0%
➜ BloomFilter git:(master) ✗ python redisbloom_test.py
size: 100000 , error rate: 0.001%
误判率瞬间少了1000多倍。
但是要求误判率越低,所需要的空间是需要越大,可以有一个公式计算,由于公式较复杂,直接上类似计算器,感受一下:
如果一千万的数据,误判率允许 1%, 大概需要11M左右,如下图:
如果要求误判率为 0.1%,则大概需要 17 M左右。
但这空间相比直接用set存1000万数据要少太多了。
2.1.3 扩展学习
RedisBloom 模块 还实现了 布谷鸟过滤器,简单了解了一下,有一篇论文有兴趣的通信可以读一下 https://www.cs.cmu.edu/~dga/papers/cuckoo-conext2014.pdf
文章中对比了布隆过滤器和布谷鸟过滤器,相比布谷鸟过滤器,布隆过滤器有以下不足:
查询性能弱
查询性能弱是因为布隆过滤器需要使用N个 hash函数计算位数组中N个不同的点,这些点在内存上跨度较大,会导致CPU缓存命中率低。空间利用效率低
在相同的误判率下,布谷鸟的空间利用率要高于布隆过滤器,能节省40%左右。不支持删除操作
这是布谷鸟过滤器相对布隆过滤器最大的优化,支持反向操作,删除功能。不支持计数
因暂时未对布谷鸟过滤器进行比较深入的了解,不清楚它到底是不是文章说的那么好,有时间再研究一下。
2.2 pyreBloom
pyreBloom 是 Python 中 Redis + BloomFilter 模块,是c语言实现。如果觉得Redis module的形式部署很麻烦或者线上环境Redis版本不是 4.0 及以上,则可以采用这个,但是它是在 hiredis 基础上,需要安装hiredis,且不支持重连和重试,如果用到生产环境上需要进行简单的封装。
安装:
git clone https://github.com/redis/hiredis.git src/hiredis && \
cd src/hiredis && make && make PREFIX=/usr install && ldconfig
// mac brew install hiredis
git clone https://github.com/seomoz/pyreBloom src/pyreBloom && \
cd src/pyreBloom && python setup.py install
演示代码:
from pyreBloom import pyreBloom
redis_conf = {'host': '127.0.0.1', 'password': '', 'port': 6379, 'db': 0}
for k, v in redis_conf.items():
redis_conf = convert_utf8(redis_conf)
key = convert_utf8('tc')
value = convert_utf8('hello')
p = pyreBloom(key, 10000, 0.001, **redis_conf)
p.add(value)
print(p.contains(value))
2.3 原生语言 + redis 实现
Python 原生语言比较慢,如果是Go语言,没有找到合适的开源redis的BloomFilter,就可以自己用 原生语言 + redis的 bitmap 相关操作实现。 Java 语言的话,RedisBloom项目里有实现 JReBloom,因非Java开发者,这块自行了解。
这里演示用 Python 语言,Go 语言版本有时间再补充:
# python3.6 bloomfilter_py_test.py
import mmh3
import redis
class BloomFilter(object):
def __init__(self, bf_key, bit_size=10000, hash_count=3, start_seed=41):
self.bit_size = bit_size
self.hash_count = hash_count
self.start_seed = start_seed
self.client = redis.StrictRedis()
self.bf_key = bf_key
def add(self, data):
bit_points = self._get_hash_points(data)
for index in bit_points:
self.client.setbit(self.bf_key, index, 1)
def madd(self, m_data):
if isinstance(m_data, list):
for data in m_data:
self.add(data)
else:
self.add(m_data)
def exists(self, data):
bit_points = self._get_hash_points(data)
result = [
self.client.getbit(self.bf_key, index) for index in bit_points
]
return all(result)
def mexists(self, m_data):
result = {}
if isinstance(m_data, list):
for data in m_data:
result[data] = self.exists(data)
else:
result[m_data] = self.exists[m_data]
return result
def _get_hash_points(self, data):
return [
mmh3.hash(data, index) % self.bit_size
for index in range(self.start_seed, self.start_seed +
self.hash_count)
]
在上文的simple_bloomfilter.py的基础引入redis的setbit 和 getbit,替换掉 bitarray。同时实现了类似BloomFilter的 madd 和 mexists 方法,测试结果如下:
>>> from bloomfilter_py_test import BloomFilter
>>> bf_obj = BloomFilter('bf.tc')
>>> bf_obj.add('tc01')
>>> bf_obj.madd('tc02')
>>> bf_obj.madd(['tc03', 'tc04'])
>>> bf_obj.exists('tc01')
True
>>> bf_obj.mexists(['tc02', 'tc03', 'tc04', 'tc05'])
{'tc02': True, 'tc03': True, 'tc04': True, 'tc05': False}布隆过滤器相关内容就实践到这里。相关代码上传在 https://github.com/fuzctc/tc-redis-practice
以上是关于Redis 高级主题之布隆过滤器(BloomFilter)的主要内容,如果未能解决你的问题,请参考以下文章