粗浅了解Apache zookeeper
Posted _wangjianfeng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了粗浅了解Apache zookeeper相关的知识,希望对你有一定的参考价值。
一篇文章粗浅了解Apache zookeeper
前言
Zookeeper是一个分布式应用程序协调服务,提供了简单易用的接口和性能高效、功能稳定的系统让用户可以很轻松解决分布式应用程序下面的出现的协调服务,确保避免出现竞态条件或者死锁等错误。其设计目标是减轻分布式应用从零开始实现分布式协调服务的压力。本篇文章将会在以下几个方面来介绍zookeeper。
zookeeper是什么
zookeeper的数据模型(znode)
znode结构- 数据存储
- 节点类型
- 节点操作
- 监视器
zookeeper的集群架构zookeeper的功能
- 命名服务
- 配置管理
- 集群管理
- 分布式锁
- 队列管理
zookeeper简单部署使用
- 部署
zookeeper集群。 - 基于
zookeeper的分布式锁简单实现。
- 部署
本文参考官方网站以及其他一些博客文章,连接会在文章后面贴出。
zookeeper是什么
引用官方文档的一话来说明zookeeper是什么东西
zookeeper是一个高性能分布式应用协作服务,它提供了基本功能,包括 命名空间。配置管理,集群管理和组同步。提供了一些简单的API,而不必要从头再实现他们,你可以使用它来实现同步,集群管理,选举和出席协议,你可以根据自己特定的需求构建服务。
zookeeper非常快速且非常简单,由于其目标是构建更复杂到的服务的基础,因此他提供了一组保证。
- 顺序一致性:客户端的更新将按照他们发送的顺序进行应用
- 原子性:更新成功或失败,没有部分更新
- 单一性:无论客户端连接到那个服务器,都会看到同一个视图
- 可靠性:一旦客户端进行了修改,他会保持知道一个客户端修改了它
- 及时性:客户端会在一个确定时间内得到最新的数据。
zookeeper 的数据模型:
zookeeper允许分布式进程通过一个共享的被组织成类似一个标准文件系统的命名空间相互协作,这些命名空间可以保存数据,称之为znode,在zookeeper的设定中,它类似于文件和目录但是区别于典型的文件系统,因为他被设计数据保存在内存中,这意味着zookeeper可以实现高吞吐量和低延迟。
znode结构
zookeeper命名空间中的znode,兼具文件和目录两种特点,既像文件一样维护者数据,元信息,ACL,时间戳等数据结构,又可以像目录一样作为标识路径的一部分。每个znode由三部分组成。
stat:状态信息,描述该znode的版本,权限等信息data:与该znode关联的数据children:该znode下的子节点
zookeeper可以关联一些数据,但是没有被设计为常规的数据库或者大数据存储,它用于管理调度数据,比如分布式应用中的配置文件,状态信息等等。zookeeper节点数据被严格控制在1M之内
znode通过路径引用,如同Unix的文件绝对路径,所以路径是由/开始的,除此之外,他们必须是唯一的,也就是说每一个路径只有一个表示,这些路径不能改变。在zookeeper中,路径由Unicode字符串组成,并且有一些限制。字符串/zookeeper用于保存管理信息。
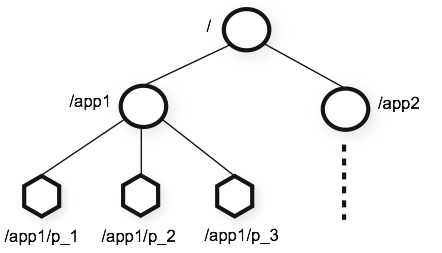
数据存储
zookeeper中的每个节存取的数据操作都是原子性操作,读操作会获取节点相关的所有数据,写操作会替换节点的所有数据,另外,每一个节点都拥有自己的访问控制列表,这个列表规定了用户的权限,限制谁可以做什么
节点类型
zookeeper中的节点分为两种,分别为临时节点和永久节点。节点的类型在创建的时候即被确定,不能改变。
- 临时节点:该节点的声明周期依赖于创建他们的会话,一旦会话结束,临时节点将被自动删除,也可以手动删除。虽然每一个临时节点绑定到一个会话,但是这个节点对所有的客户端会话都是可见的。临时节点不允许有子节点。
- 永久节点:该节点的声明周期不依赖于会话,只有客户端显式删除他们才会消失。
除此之外,还有另外一个概念,有一种叫做顺序节点。在创建znode的时候,zookeeper会在路径结尾添加一个递增的计数。这个计数对于此节点的父节点来说是唯一的。它的格式为%10d,当计数值大于2的32次方-1时,计数器将会溢出。
节点操作
zookeeper的一个设计目标是提供一个非常简单的编程接口,因此,它仅仅支持以下操作:
| 操作 | 描述 |
|---|---|
create | 创建znode,在创建一个节点的时候,必须确保父节点已经存在 |
delete | 删除znode,在删除一个节点的时候,保证该节点没有子节点 |
exists | 判断是否存在znode,并获取他的元数据 |
getData/setData | 获取/设置znode节点关联的数据 |
getChildren | 获取该znode的所有子节点 |
sync | 使客户端的znode视图与zookeeper同步 |
监视器
zookeeper可以为所有的读操作设置一个watcher,这些读操作包括exists(),getChildren()以及getData()。watch时间是一次性的触发器,当watch的对象发生改变时,将会触发此对象上watch所对应的事件,watch事件将被异步发送给客户端,并且zookeeper为watch机制提供了有序的一致性保障。理论上,客户端接收watch时间的时间要快于其看到watch对象状态变化的时间。
zookeeper的集群架构
zookeeper对实现高性能,高可用性,严格有序的访问非常重要,zookeeper可以部署为集群模式。zookeeper的服务器会对信息进行共享,他们保持状态的内存映像,以及持久储存中的事务日志和快照,只要大部分服务器可用,则Zookeeper服务可用。
分布式与数据复制
Zookeeper作为一个集群提供一致的数据服务,自然,它要在所有机器间做数据复制。数据复制的好处:
- 容错:一个节点出错,不致于让整个系统停止工作,别的节点可以接管它的工作;
- 提高系统的扩展能力 :把负载分布到多个节点上,或者增加节点来提高系统的负载能力;
- 提高性能:让客户端本地访问就近的节点,提高用户访问速度。
从客户端读写访问的透明度来看,数据复制集群系统分下面两种:
1、写主(WriteMaster) :对数据的修改提交给指定的节点。读无此限制,可以读取任何一个节点。这种情况下客户端需要对读与写进行区别,俗称读写分离;
2、写任意(Write Any):对数据的修改可提交给任意的节点,跟读一样。这种情况下,客户端对集群节点的角色与变化透明。
对zookeeper来说,它采用的方式是写任意。通过增加机器,它的读吞吐能力和响应能力扩展性非常好,而写,随着机器的增多吞吐能力肯定下降(这也是它建立observer的原因),而响应能力则取决于具体实现方式,是延迟复制保持最终一致性,还是立即复制快速响应。
结构如图:

zookeeper的功能
zookeeper提供了命名服务、配置管理、集群管理、分布式锁、队列管理等一系列的功能。这些功能都是基于znode数据结果来协调完成的。
命名服务
在zookeeper的文件系统里创建一个目录,具有唯一的path,在无法确定分布式架构下其他机器时可以通过这个path进行联系。
配置管理
在分布式架构下,多台机器的配置修改变变得困难,可以把配置信息放在zookeeper上面的某个目录节点中,然后所有相关应用程序对这个目录节点进行监听,一旦配置信息发生改变,每个应用程序都会受到zookeeper的通知。
集群管理
集群管理的问题在于如何确定机器的加入和退出,以及出现故障时,选举master方面的问题。对于机器的加入和退出,可以通过创建一个父节点,然后监听这个节点的子节点变化消息,一旦有机器加入或宕机,则该机器与zookeeper的连接断开,其所创建的临时节点被删除,其他所有机器都收到通知,新的机器加入也是同样的道理。关于选举master,假设我们在创建临时节点的时候,使用顺序节点,每一个节点都带者一个对于父节点唯一的序号,此时,选取最小的节点作为master即可。一旦机器宕机了,节点被删除,又重新选举。
分布式锁
使用zookeeper实现分布式锁,有两种方式:
将一个临时
znode看做一把锁,客户端创建这个节点成功后则表示获得锁,此时其他客户端创建这个znode将会失败,直到获得锁的客户端释放这个锁(删除该节点),其他客户端才能获取锁。创建一个父节点
/distribute_lock,所有客户端在它下面创建临时顺序编号的节点,如果判断到当前客户端的顺序最小则获取锁,用完删除,其他节点依次获得锁。
队列管理
两种类型的队列:
- 同步队列,当一个队列的成员都聚齐时,这个队列才可用,否则一直等待所有成员到达。
- 队列按照
FIFO方式进行入队和出队操作。
第一类,在约定目录下创建临时目录节点,监听节点数目是否是我们要求的数目。
第二类,和分布式锁服务中的控制时序场景基本原理一致,入列有编号,出列按编号
zookeeper简单部署应用
部署zookeeper
这里采用3台本地虚拟机进行部署,操作系统为CentOs 6.5,它们的ip地址分别为:
- 192.168.31.224
- 192.168.31.225
- 192.168.31.226
去到/usr/local/目录
cd /usr/local
下载zookeeper包
wget http://mirrors.hust.edu.cn/apache/zookeeper/zookeeper-3.4.10/zookeeper-3.4.10.tar.gz
解压
tar -zxvf zookeeper-3.4.10.tar.gz
对目录重命名
mv zookeeper-3.4.10 zk
配置环境变量
# vi ~/.bashrc
export ZOOKEEPER_HOME=/usr/local/zk
export PATH=$ZOOKEEPER_HOME/bin
source ~/.bashrc
接着执行以下命令
cd zk/conf
# 复制配置文件,zookeeper默认配置文件为zoo.cfg
cp zoo.sample.cfg zoo.cfg
mkdir data
然后编辑zoo.cfg修改以下内容:
dataDir=/usr/local/zk/data/
server.0=192.168.31.224:2888:3888
server.1=192.168.31.225:2888:3888
server.2=192.168.31.226:2888:2888
然后去到/zk/data/目录下
cd /usr/local/zk/data/
vi myid
myid的内容为zoo.cfg中的server.=192.168.31.xxx中的部分,比如192.168.31.224的ip地址的myid文件内容为0,依次类推,其他两台机器的内容为1和2
在3台机器都部署好之后,执行:
zkServer.sh start
查看状态,在3台机器上执行应该是显示一个leader两个follower
zkServer.sh status
然后可以通过jps命令查看输出结果是否有QuromPeerMain进程,如果存在,则表示zookeeper集群部署成功了。
基于zookeeper的分布式锁简单实现
zookeeper默认提供了Java和C两种语言的接口,我们通过java实现一个简单的分布式锁。
使用IDEA创建一个maven项目,添加如下依赖:
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.4.5</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
接着编写获得分布式锁的代码:
public class ZooKeeperSession
private static CountDownLatch connectedSemaphore = new CountDownLatch(1);
private ZooKeeper zookeeper;
public ZooKeeperSession()
try
this.zookeeper = new ZooKeeper(
"192.168.31.224:2181,192.168.31.225:2181,192.168.31.226:2181",
50000,
new ZooKeeperWatcher());
System.out.println(zookeeper.getState());
connectedSemaphore.await();
System.out.println("ZooKeeper session established......");
catch (Exception e)
e.printStackTrace();
/**
* 获取分布式锁
* @param path
*/
public void acquireDistributedLock(String path)
try
zookeeper.create(path, "".getBytes(),
Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL);
System.out.println("success to acquire lock");
catch (Exception e)
// NodeExistsException
int count = 0;
while(true)
try
Thread.sleep(1000);
zookeeper.create(path, "".getBytes(),
Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL);
catch (Exception e2)
count++;
System.out.println("the " + count + " times try to acquire lock......");
continue;
System.out.println("success to acquire lock after " + count + " times try......");
break;
/**
* 释放掉一个分布式锁
* @param productId
*/
public void releaseDistributedLock(String path)
try
zookeeper.delete(path, -1);
System.out.println("release the lock......");
catch (Exception e)
e.printStackTrace();
/**
* 建立zk session的watcher
* @author Administrator
*
*/
private class ZooKeeperWatcher implements Watcher
public void process(WatchedEvent event)
System.out.println("Receive watched event: " + event.getState());
if(KeeperState.SyncConnected == event.getState())
connectedSemaphore.countDown();
上述代码实现了一个最简单的分布式锁,在构造函数中,连接上zookeeper,然后在获取分布式锁的代码也是很简单粗暴。
首先创建了一个临时节点(CreateMode.EPHEMERAL),如果创建这个节点失败了,则证明这个锁已经在占用,则无限循环知道获取到这个锁为止,当锁的持有者释放掉锁之后(delete node),则可以获取该锁。
总结
其实这篇文章不算原创,有很多内容都摘自其他博客,自己也没有研究得这么深入,写这篇文章的目的是为了记录一下一些知识,其实写博客的一个很重要的原因就是记录一些知识,因为我觉得有时候找资料上网找不如上自己博客找。找到的信息还比较可靠吧,毕竟是自己的经验。
参考
以上是关于粗浅了解Apache zookeeper的主要内容,如果未能解决你的问题,请参考以下文章