训练大模型的九大深度学习库;谷歌转向文字→视频生成的两大利器|AI系统前沿动态...
Posted OneFlow深度学习框架
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了训练大模型的九大深度学习库;谷歌转向文字→视频生成的两大利器|AI系统前沿动态...相关的知识,希望对你有一定的参考价值。

训练大型深度学习模型需要极大的内存,才能储存中间层的激活函数输出和权重等。一些模型只能在单个GPU上训练,训练时须将批大小(batch size)设置得极小;还有一些模型则太大,单个GPU放不下。这些问题会导致在某些情况下模型训练效率极低,甚至无法训练。训练大型深度学习模型主要有两大方法:数据并行、模型并行。
当单个GPU的内存可以完整容纳整个模型时,这是可实现数据并行的最简单的情况。但此时,模型训练可用的batch size就变得较小,增加了训练难度。解决办法是将不同的模型实例放在不同的GPU上运行,每个模型实例计算不同的数据批次。

每个模型实例都有相同的参数初始化,但在前向传播中,每个模型实例会收到不同的数据批次。每个模型实例产生的梯度会被集结起来,用以计算梯度更新,然后进行模型参数更新,更新后的参数将被发送到每个模型示例中。
当单个GPU无法容纳整个模型时,模型并行就十分必要。模型并行要求将模型切分到多个GPU上进行训练。模型并行是训练大模型的有效办法,但它的缺点是算力的利用率太低。因为同一时间只有一个GPU正在运行,其余GPU都将闲置。
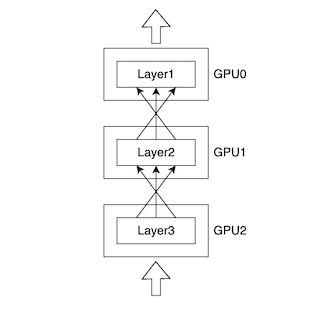
目前,数据并行和模型并行都取得了一定的进步,可以提升训练和推理时的效率。以下是业内流行的九大深度学习库。
1. Megatron-LM
Megatron是NVIDIA应用深度学习研究团队研发的大规模Transformer语言模型训练框架,支持模型并行(张量并行、序列并行与流水并行)与多节点预训练(multi-node pre-training),目前已支持BERT、GPT和T5模型。
链接:https://github.com/NVIDIA/Megatron-LM
2. DeepSpeed
DeepSpeed是Microsoft推出的深度学习库,用于训练Megatron-Turing NLG 530B和BLOOM等大型模型,在训练、推理和压缩三方面都有所创新。
DeepSpeed具有如下优点:
可进行十亿乃至万亿级参数的稀疏/密集模型的训练/推理
可实现超高系统吞吐量,可高效扩展至数千个GPU
可在资源有限的GPU系统上进行训练/推理
可实现前所未有的低延时与高推理吞吐量
可用低成本实现压缩,从而大幅降低推理延迟并缩减模型大小
链接:https://github.com/microsoft/DeepSpeed
3. FairScale
FairScale是由Facebook Research开发的PyTorch扩展库,具备高性能,可用于大型训练。FairScale的愿景如下:
易用性,开发简单易懂的FairScale API,使用户方便上手。
模块化,实现模块化,使用户可将多个FairScale API无缝加入其训练循环。
性能,实现 FairScale API的高可扩展性和高效率。
FairScale支持完全分片数据并行(FullyShardedDataParallel,FSDP),FSDP是扩展大型神经网络训练的推荐方法。
链接:https://github.com/facebookresearch/fairscale
4. ParallelFormers
Parallelformers是基于Megatron-LM的开源库。它与HuggingFace库高度融合,只用一行代码即可将HuggingFace库中的模型并行化。目前,Parallelformers只支持推理。
链接:https://github.com/tunib-ai/parallelformers
5. ColossalAI
Colossal-AI提供用于分布式/并行训练的一套并行组件。Colossal-AI支持下列并行策略与优化措施:数据并行、流水并行、1D, 2D, 2.5D, 3D 张量并行、序列并行、零冗余优化器 (ZeRO)、异构内存管理(Heterogeneous Memory Management),用于推理系统Energon-AI。
链接:https://github.com/hpcaitech/ColossalAI
6. Alpa
Alpa是一个用于训练和服务大型神经网络的系统。其特点如下:
自动并行化:Alpa可自动将用户的单设备代码并行化,用于分布式集群,实现数据并行、算子并行和流水并行。
出色的性能:Alpa在使用分布式集群训练含十亿级参数的大模型时可实现线性扩展。
密切整合机器学习生态:Alpa由Jax、XLA和Ray等高性能且生产就绪的开源库提供支持。
链接:https://github.com/alpa-projects/alpa
7. Hivemind
Hivemind库可以让用户通过网络使用PyTorch进行去中心化深度学习训练。它起初的设计目的是让来自各地的高校、企业和自发参与人员能够通过数百台不同电脑训练同一大型模型。
Hivemind的主要特点包括:
可实现无主节点的分布式训练:其底层的分布式哈希表可在去中心化网络中连接所有计算机。
反向传播容错:即使某些节点无反应或反应时间较长,也不会导致前向传播和反向传播失败。
去中心化参数平均化: 来自多个worker的参数更新可以进行迭代累计,而无须在整个网络中同步。
可训练任意大小的神经网络:部分神经网络层可通过去中心化混合专家系统(Decentralized Mixture-of-Experts)分布在多台计算机中。
链接:https://github.com/learning-at-home/hivemind
8. OneFlow
OneFlow是一个高效、易用、可扩展的深度学习框架,可实现以下功能:
兼容PyTorch的API对模型进行编程
运用全局视角(Global View)API将模型扩展至n维并行执行或分布式执行
用静态图编译器(Static Graph Compiler)进行模型加速/部署
链接:https://github.com/Oneflow-Inc/oneflow(论文:
https://arxiv.org/abs/2110.15032)
9. Mesh-Tensorflow
Mesh TensorFlow (mtf)是一种专用于分布式深度学习的语言,可指定多种分布式张量计算。其名称中的Mesh意为“网”,表示多个处理器和计算设备互相连接形成的网络。
链接:https://github.com/tensorflow/mesh
(以上内容经授权后编译发布,原文:https://medium.com/@mlblogging.k/9-libraries-for-parallel-distributed-training-inference-of-deep-learning-models-5faa86199c1f)
在模型比较小时(如 100G 以下),还有可能采用单机存储。当模型参数量比较大时,要求的样本数也更大,训练后做 dump 出来的模型也会很大,单机肯定放不下。本文将介绍 OneFlow 的大模型分片保存、加载策略以及使用方法。
链接:https://mp.weixin.qq.com/s/2Z400_r_ZVwYYnGH7vw9zg
11. 强化学习发现矩阵乘法算法,DeepMind再登Nature封面推出AlphaTensor
在最新一期 Nature 封面论文《Discovering faster matrix multiplication algorithms with reinforcement learning》中,DeepMind 提出了 AlphaTensor,并表示它是第一个可用于为矩阵乘法等基本任务发现新颖、高效且可证明正确的算法的人工智能系统。简单来说,使用 AlphaTensor 能够发现新算法。这项研究揭示了 50 年来在数学领域一个悬而未决的问题,即找到两个矩阵相乘最快方法。
AlphaTensor 建立在 AlphaZero 的基础上,而 AlphaZero 是一种在国际象棋、围棋和将棋等棋盘游戏中可以打败人类的智能体。这项工作展示了 AlphaZero 从用于游戏到首次用于解决未解决的数学问题的一次转变。
链接:https://mp.weixin.qq.com/s/kCayZUk1MNZqE7j_l_bLOA
12. 谷歌多模态大模型PaLI:采用参数量为4B的ViT-e,效果超过BEiT-3
语言和视觉任务的建模中,更大的神经网络模型能获得更好的结果,几乎已经是共识。在语言方面,T5、GPT-3、Megatron-Turing、GLAM、Chinchilla和PaLM等模型显示出了在大文本数据上训练大型Transformer 的明显优势。视觉方面,CNN、视觉Transformer和其他模型都从大模型中取得了很好的结果。language-and-vision建模也是类似的情况,如SimVLM、Florence、CoCa、GIT、BEiT 和 Flamingo。来自谷歌的研究者通过一个名为 PaLI (Pathways Language and Image)的模型来延续这一方向的研究。
链接:https://mp.weixin.qq.com/s/naWS149JaZSaQweVRRFDTw
13. 谷歌全面转向文字→视频生成,两大利器同时挑战分辨率和长度
在文本转图像上卷了大半年之后,Meta、谷歌等科技巨头又将目光投向了一个新的战场:文本转视频。Meta 公布了一个能够生成高质量短视频的工具——Make-A-Video,利用这款工具生成的视频非常具有想象力。当然,谷歌也不甘示弱。该公司 CEO Sundar Pichai 亲自安利了他们在这一领域的最新成果:两款文本转视频工具——Imagen Video 与 Phenaki。前者主打视频品质,后者主要挑战视频长度,可以说各有千秋。
链接:https://mp.weixin.qq.com/s/uf1xAg3e1DGDAS7tDMG-KQ
14. 层出不穷的机器学习框架到底在“卷”什么?
10月19日19:00,小红书技术REDtech邀请到了国内的深度学习框架初创公司OneFlow的创始人袁进辉,与小红书智能分发部负责人瑞格带来新一期【REDtech 来了】技术直播。他们将围绕机器学习框架在工业界实际应用的挑战与前景展开精彩分享。
链接:https://mp.weixin.qq.com/s/mtptKgY5qJ-uQngOV3Iq2Q
其他人都在看
点击“阅读原文”,欢迎体验OneFlow v0.8.0

以上是关于训练大模型的九大深度学习库;谷歌转向文字→视频生成的两大利器|AI系统前沿动态...的主要内容,如果未能解决你的问题,请参考以下文章