深度学习系列33:统一图像视频文字的女娲模型
Posted IE06
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习系列33:统一图像视频文字的女娲模型相关的知识,希望对你有一定的参考价值。
1. 输入
文字:使用使用BPE进行分词,tokenizer.encode(txt_str)转化为向量,然后embedding为
R
1
×
1
×
s
×
d
R^1\\times1\\times s \\times d
R1×1×s×d
图片:输入
I
∈
R
H
×
W
×
C
I\\in R^H\\times W\\times C
I∈RH×W×C,通过VQ-VAE或者VQ-GAN中的生成器E和离散编码器B转化并摊平为
R
h
×
w
×
1
×
d
R^h\\times w\\times 1 \\times d
Rh×w×1×d。
视频:逐帧编码图片,并合并为
R
h
×
w
×
s
×
d
R^h\\times w\\times s \\times d
Rh×w×s×d。
草图:输入
I
∈
R
H
×
W
×
C
I\\in R^H\\times W\\times C
I∈RH×W×C,其中C是分割类型编号,同样通过VQ-GAN生成
R
h
×
w
×
1
×
d
R^h\\times w\\times 1 \\times d
Rh×w×1×d。
注意这里对每一个维度j都进行离散化,而不是整体进行离散化:

注意
z
q
z_q
zq里的每一个分量都是下标,即
z
q
∈
0
,
1
,
.
.
.
,
N
−
1
h
×
w
z_q\\in \\0,1,...,N-1\\^h\\times w
zq∈0,1,...,N−1h×w
下图说明了两类任务的流程:

text和sketch等C需要然后经过3D编码模块,然后再进行3D解码生成Y;
图像和视频等X补全,则是直接经过3D解码器生成Y。
Y再通过VQ-GAN或者VA-VAE的解码器生成图像/视频。
2. 编码解码模块
使用了3DNA模块进行编码和解码。3DNA模块是一个使用了注意力的模块:


在C的条件下生成目标Y,我们通用的编解码过程是:首先使用L层3DNA模块生成
C
(
L
)
C^(L)
C(L):

然后使用L层3DNA模块生成
Y
(
L
)
Y^(L)
Y(L):

三个任务(Text-to-Image (T2I), Video Prediction (V2V) and Text-to-Video (T2V))同时进行训练,目标函数使用交叉熵为:
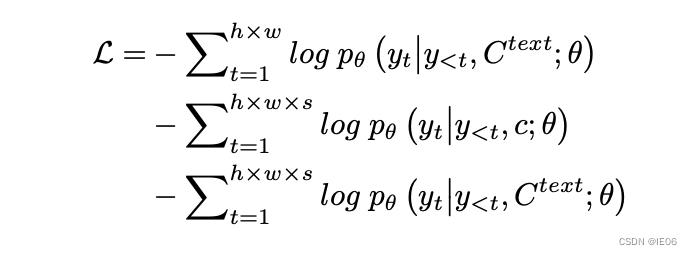
3. 代码解析
参考这篇实现:https://github.com/lucidrains/nuwa-pytorch
安装:pip install nuwa-pytorch
3.1 总流程
1)训练图像表示模块,使用VQGAN_VAE得到图像编码器
import torch
from nuwa_pytorch import VQGanVAE
vae = VQGanVAE()
imgs = torch.randn(10, 3, 256, 256)
loss = vae(imgs, return_loss = True)
loss.backward()
# and the discriminator ...
discr_loss = vae(imgs, return_discr_loss = True)
discr_loss.backward()
# do above for many steps
# return reconstructed images and make sure they look ok
recon_imgs = vae(imgs)
将训练好的vae带入nuwa模块:
nuwa = NUWA().cuda()
text = torch.randint(0, 20000, (1, 256)).cuda()
video = torch.randn(1, 10, 3, 256, 256).cuda() # (batch, frames, channels, height, width)
loss = nuwa(
text = text,
video = video,
return_loss = True # set this to True, only for training, to return cross entropy loss
)
loss.backward()
# do above with as much data as possible
# then you can generate a video from text
video = nuwa.generate(text = text, num_frames = 5) # (1, 5, 3, 256, 256)
3.2 VQGAN_VAE模块
VQGanAttention可作为可选层,计算公式为:

其中B用ContinuousPositionBias得到。我们来看下对应的代码:
class VQGanAttention(nn.Module):
def __init__(
self,
*,
dim,
dim_head = 64,
heads = 8,
dropout = 0.
):
super().__init__()
self.heads = heads
self.scale = nn.Parameter(torch.ones(1, heads, 1, 1) * math.log(0.01))
inner_dim = heads * dim_head
self.dropout = nn.Dropout(dropout)
self.post_norm = LayerNormChan(dim)
self.cpb = ContinuousPositionBias(dim = dim // 4, heads = heads)
self.to_qkv = nn.Conv2d(dim, inner_dim * 3, 1, bias = False)
self.to_out = nn.Conv2d(inner_dim, dim, 1)
def forward(self, x):
h = self.heads
height, width, residual = *x.shape[-2:], x.clone()
q, k, v = self.to_qkv(x).chunk(3, dim = 1)
q, k, v = map(lambda t: rearrange(t, 'b (h c) x y -> b h c (x y)', h = h), (q, k, v))
q, k = map(l2norm, (q, k)) # q,k 正则化
sim = einsum('b h c i, b h c j -> b h i j', q, k) * self.scale.exp() # qk/sqrt(d)
sim = self.cpb(sim) # 加上B
attn = stable_softmax(sim, dim = -1) # softmax
attn = self.dropout(attn)
out = einsum('b h i j, b h c j -> b h c i', attn, v) # 乘以v
out = rearrange(out, 'b h c (x y) -> b (h c) x y', x = height, y = width)
out = self.to_out(out) # 卷积
return self.post_norm(out) + residual
接着来看下整体的网络结构:
append = lambda arr, t: arr.append(t)
prepend = lambda arr, t: arr.insert(0, t)
for layer_index, (dim_in, dim_out), layer_num_resnet_blocks, layer_use_attn in zip(range(num_layers), dim_pairs, num_resnet_blocks, use_attn):
# 堆叠卷积层或者上采样层
append(self.encoders, nn.Sequential(nn.Conv2d(dim_in, dim_out, 4, stride = 2, padding = 1), leaky_relu()))
prepend(self.decoders, nn.Sequential(nn.Upsample(scale_factor = 2, mode = 'bilinear', align_corners = False), nn.Conv2d(dim_out, dim_in, 3, padding = 1), leaky_relu()))
# 加入注意力模块
if layer_use_attn:
prepend(self.decoders, VQGanAttention(dim = dim_out, heads = attn_heads, dim_head = attn_dim_head, dropout = attn_dropout))
for _ in range(layer_num_resnet_blocks):
# 加入残差
append(self.encoders, ResBlock(dim_out, groups = resnet_groups))
prepend(self.decoders, GLUResBlock(dim_out, groups = resnet_groups))
if layer_use_attn:
append(self.encoders, VQGanAttention(dim = dim_out, heads = attn_heads, dim_head = attn_dim_head, dropout = attn_dropout))
prepend(self.encoders, nn.Conv2d(channels, dim, first_conv_kernel_size, padding = first_conv_kernel_size // 2))
append(self.decoders, nn.Conv2d(dim, channels, 1))
接着看一下forward函数:
def forward():
fmap, indices, commit_loss = self.encode(img)
fmap = self.decode(fmap)
if return_discr_loss: # 训练discriminator时
loss = self.discr_loss(fmap_discr_logits, img_discr_logits)
return loss
# reconstruction loss
recon_loss = self.recon_loss_fn(fmap, img)
# perceptual loss
img_vgg_feats = self.vgg(img_vgg_input)
recon_vgg_feats = self.vgg(fmap_vgg_input)
perceptual_loss = F.mse_loss(img_vgg_feats, recon_vgg_feats)
# generator loss
gen_loss = self.gen_loss(self.discr(fmap))
# combine losses
loss = recon_loss + perceptual_loss + commit_loss + adaptive_weight * gen_loss
return loss
另外包含图片/视频与codebook转换的函数
def codebook_indices_to_video(self, indices):
b = indices.shape[0]
codes = self.codebook[indices]
codes = rearrange(codes, 'b (f h w) d -> (b f) d h w', h = self.fmap_size, w = self.fmap_size)
video = self.decode(codes)
return rearrange(video, '(b f) ... -> b f ...', b = b)
def get_video_indices(self, video):
b, f, _, h, w = video.shape
images = rearrange(video, 'b f ... -> (b f) ...')
_, indices, _ = self.encode(images) # 使用codebook进行编码
return rearrange(indices, '(b f) ... -> b f ...', b = b)
3.3 主模块
先来看主函数
class NUWA(nn.Module):
def forward():
frame_embeddings = self.image_embedding(frame_indices_input)
frame_embeddings = self.video_transformer(
frame_embeddings,
context = text_embeds,
context_mask = text_mask
)
logits = self.to_logits(frame_embeddings)
loss = F.cross_entropy(rearrange(logits, 'b n c -> b c n'), frame_indices)
return loss
再来看文字输入模块:
def embed_text(self, text, mask = None):
# 使用一个embedding层,text_num_tokens = 49408
text_embedding = Embedding(text_num_tokens, dim, frac_gradient = embed_gradient_frac)
tokens = text_embedding(text)
# 位置编码
if exists(self.text_abs_pos_emb):
pos_emb = self.text_abs_pos_emb(torch.arange(seq_len, device = device))
tokens = tokens + rearrange(pos_emb, 'n d -> 1 n d')
rotary_pos_emb = None
if exists(self.text_rotary_pos_emb):
rotary_pos_emb = self.text_rotary_pos_emb(seq_len, device = device)
# 加上一个transformer
return self.text_transformer(
tokens,
mask = mask,
rotary_pos_emb = rotary_pos_emb
)
以上是关于深度学习系列33:统一图像视频文字的女娲模型的主要内容,如果未能解决你的问题,请参考以下文章