Zipkin分布式任务追踪
Posted weiker12
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Zipkin分布式任务追踪相关的知识,希望对你有一定的参考价值。
Zipkin分布式任务追踪
zipkin简介
Zipkin 是一款开源的分布式实时数据追踪系统,由基于 Google Dapper 的论文设计而来,由 Twitter 公司提供开源实现,主要功能是聚集来自各个异构系统的实时监控数据,和微服务架构下的接口直接的调用链路和系统延时问题。

Zipkin 提供了自己的UI,应用将自己的监控数据报告给zipkin,由Zipkin 汇集并提供关联图展示,Zipkin可以追踪请求调用链路。Zipkin 以 Trace 的结构表示一次请求的追踪,又把每个Trace拆分为若干个有依赖关系的 Span,在微服务架构中,一次用户的请求可能会被后台的若干个服务处理,这完整的一次用户请求可以一条调用链路Trace,每个调用处理请求的服务可以理解为一个Span(如API服务),这个服务也可能继续调用其他的服务,因此形成一个Span的树形结构,以体现服务间的调用关系。

Zipkin 的用户界面除了可以查看 Span 的依赖关系之外,还以瀑布图的形式显示了每个 Span 的耗时情况,可以一目了然的看到各个服务的性能状况。打开每个 Span,还有更详细的数据以键值对的形式呈现,而且这些数据可以在装备应用的时候自行添加。
Spring Cloud Sleuth是对Zipkin的一个封装,对于Span、Trace等信息的生成、接入HTTP Request,以及向Zipkin Server发送采集信息等全部自动完成。
Spring Cloud Sleuth的简介
以下是Spring Cloud Sleuth的概念图

在Spring Cloud Sleuth的封装中,Zipkin分为两端,一个是Zipkin服务端,一个是Zipkin客户端,客户端也就是微服务的应用,
客户端会配置服务端的url地址,一旦发生服务间的调用的时候,会被配置在微服务里面的Sleuth的监听器监听,并生成相应的 Trace 和 Span 信息写进http报文头里面,并同时向Zipkin服务端上传这些信息,如图所示。
主要方式有两种,一种是消息总线的方式如RabbitMq发送,还有一种是http报文的方式发送,向 Zipkin 服务端发送gzip的数据包,服务端接收到gzip的数据包进行解析,根据每个调用链路汇总成调用链路的信息,这里注意,每个 Zipkin Client 里面如果设置了登录验证,并不会影响Zipkin Server的信息收集,因为 Client 端会自动上传gzip的数据包给 Server 端,而无需 Server 端去调用 Client 端的接口去统计信息,Client 端在生成 Trace 统计信息的同时,如果配置了 MDC 或者在 logback 日志中集成了日志收集工具 logstash,则可以在 Client 端的控制台读到这些 Trace 和 Span 的信息,对每个 Span 的信息都会有对应的 Annotation 进行声明。
Span 的 Annotation 信息
这些 Annotation 分为四种类型:
- cs : Client Sent,这个标识着 Span的开始。
- sr : Server Received,这个标识着服务端接收到客户端发送请求的信息。Sleuth还可以根据 cs 和 sr 的时间戳来计算服务调用的延时。
- ss : Server Sent,这个标识表示服务端接收到客户端后要返回 response 信息。
- cr : Client Received,这个标识表示客户端收到服务端返回的 response 信息。
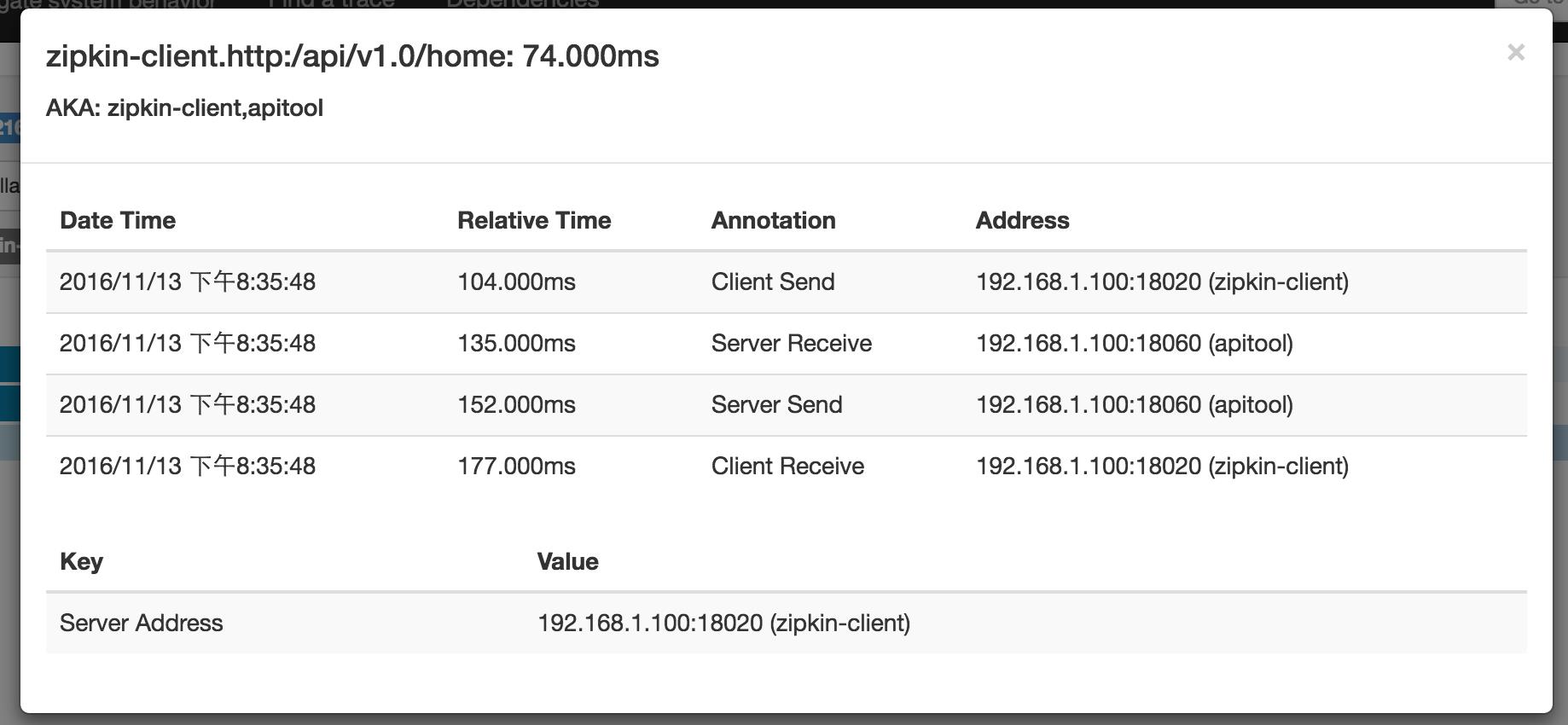
这几个注解反应了一次完整的服务间调用的信息,这些注解结合 Span id 信息可以从不同的应用汇总成调用链路的 Trace 信息,也就是说一次 Trace 的信息如果经过了 A 应用、B 应用,那么 Sleuth 会从 A 应用汇总对B应用调用产生的注解信息 Client Sent 和 Client Received,再从 B 应用汇总对 A 应用调用产生的 Server Received 和 Server Sent,A 应用根据自己调用信息组装成 Span 和携带相应的 Annotation 以gzip包的方式通过http发送给 Zipkin Server,B 应用像 A 应用一样也会组装这些信息给 Zipkin Server,Zipkin Server会根据 A 应用和 B 应用的信息汇总成统计信息展示在 Zipkin UI上。
Span的生命周期
- start:开始对Span命名和记录开始时间戳
- close:结束时记录结束时间戳并检查属性 exportable 然后汇总给 Zipkin,然后移除出当前的线程。
- continue:为 Span 新建实例并拷贝继续进行的 Span
- detach:Span 没有 stop 或者 close,仅仅是移出当前的线程。
- create with explicit parent:在另外的一个线程重新创建一个 Span 并且明确它的 parent。
Span 的存储方式
在 Zipkin Server里面有很多种存储方式,但是比较主流的有这两种:
- 放在内存中存储。
- 放在mysql中存储。
放在内存中的随着服务端的启动会出清空历史数据,如果想持久化保留这些数据,可以选择 mysql 的方式存储。
mysql配置方式参考:Stack Overflow 网友提供的参考方案
mysql 配置后有两个表,如图

更多 zipkin 学习资料:
以上是关于Zipkin分布式任务追踪的主要内容,如果未能解决你的问题,请参考以下文章
SpringCloudSpring Cloud Sleuth + Zipkin 服务调用链路追踪(二十五)
SpringCloudSpring Cloud Sleuth + Zipkin 服务调用链路追踪(二十五)