汇编语言--高级汇编技术
Posted 大忽悠爱忽悠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了汇编语言--高级汇编技术相关的知识,希望对你有一定的参考价值。
汇编语言--高级汇编技术
子程序的封装
- 这是我们之前调用子程序的写法

- 下面给出的是c语言中程序的写法,可以看到max函数其实就是一段子程序,但是其被 包围,使得该子程序的分界线非常清晰,对于程序的可读性有很大提升

- 汇编语言为了提升程序可读性,也提供了类似的功能进行封装
名称 proc
...; 实现逻辑功能的指令
(ret)
名称 endp
参考上面给出的汇编新结构,上面的一开始给出的汇编程序,可以写成下面这样:

- 段间转移也可以这样写

程序的多文件组织
- 一个程序可以由多个程序文件链接而成,每个程序文件下面又可以有多个子程序
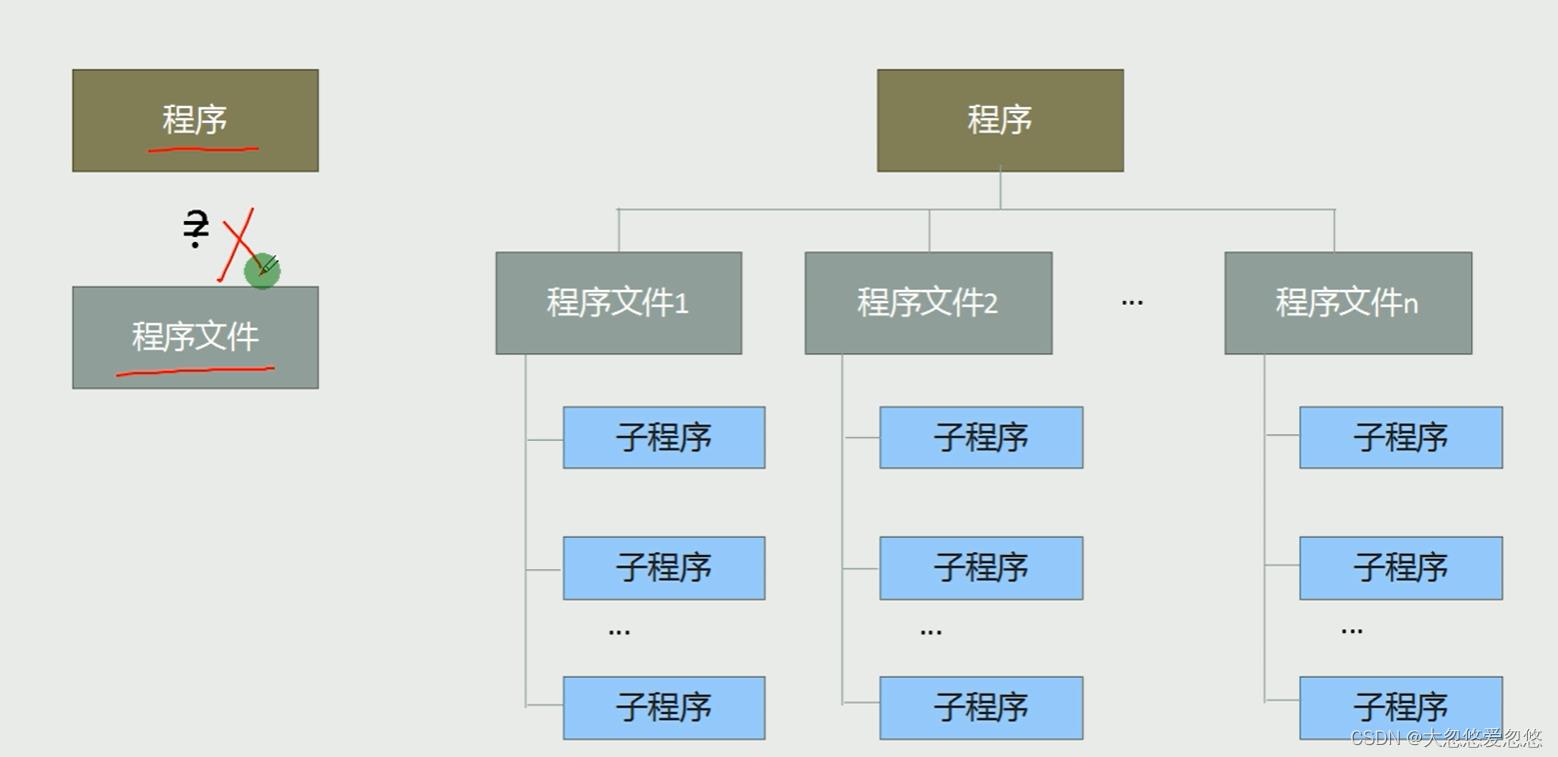
- 将下面这段汇编程序中的子程序拆分出来
ASSUME CS:CODE, DS:DATA, SS:STACK
STACK segment
db 16 dup(0)
STACK ends
code segment
start: mov ax,STACK
mov ss,ax
mov sp,16
mov ax,1000
call far ptr s ;调用子程序
mov ax,4c00h
int 21h
s: add ax,ax ;子程序开始
retf ;子程序结束
code ends
end start
- 子程序, subp表示当前subp子程序可以对外公开访问
public subp
assume cs:code
code segment
subp proc
s: add ax,ax
retf
subp endp
code ends
end
- 主程序,extrn声明子程序来自与外部文件
extrn subp:far
ASSUME CS:CODE, DS:DATA, SS:STACK
STACK segment
db 16 dup(0)
STACK ends
code segment
main proc
start: mov ax,STACK
mov ss,ax
mov sp,16
mov ax,1000
call far ptr subp ;调用子程序
mov ax,4c00h
int 21h
main endp
code ends
end start
- 编译和链接步骤如下
masm p1;
masm p2;
link p1.obj+p2.obj;
汇编指令汇总
每个指令详细用法,大家咨询查询资料,这里只列举出常用的一些汇编指令汇总
数据传送指令
- 通用数据传送指令
MOV,PUSH,POP,XCHG

- 累加器专用传送指令
IN,OUT,XLAT
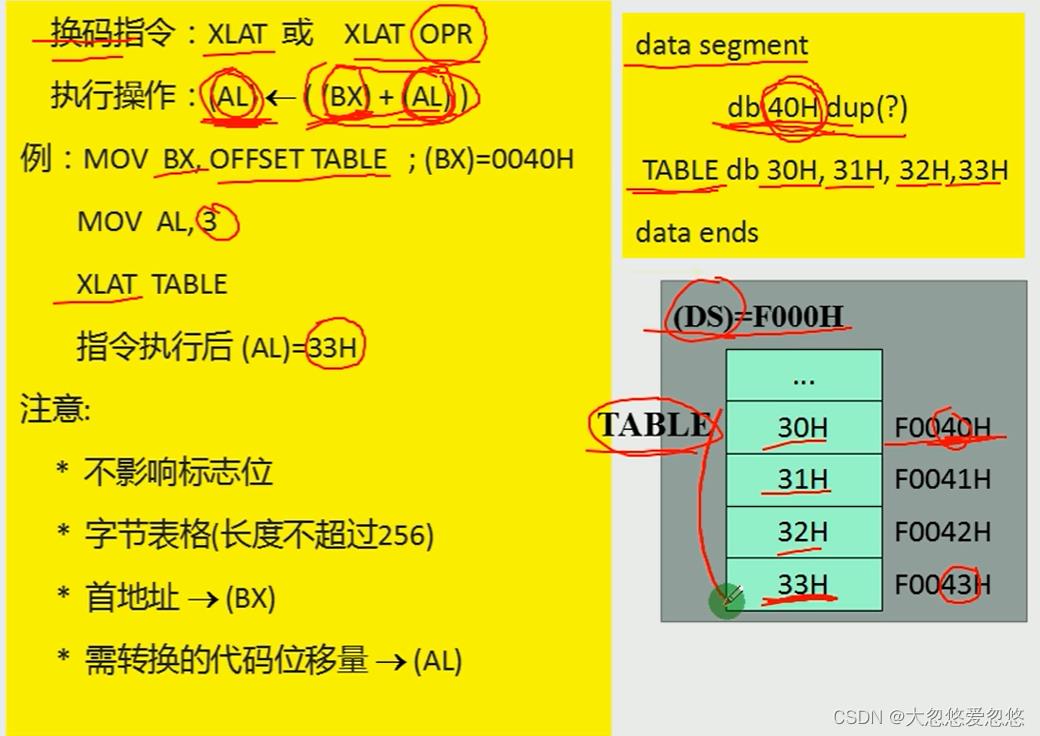
- 地址传送指令
LEA,LDS,LES

- LEA指令中的SRC可以是一个数据标号,这样就直接把一个数据标号代表的地址赋给了REG寄存器
- LDS和LES都是取出SRC代表内存空间开始四个字节值取出,前两个字节放REG,后两个字节放入DS或者ES中
- 标志寄存器传送指令
LAHF,SAHF,PUSHF,POPF

- 类型转换指令
CBW:字节扩展到字
CWD: 字扩展到双字

算术指令
- 加法指令
ADD,ADC,INC
- 减法指令
SUB,SBB,DEC,NEG,CMP
- 乘法指令
MUL,IMUL
- 除法指令
DIV,IDIV
- 十进制调整指令
DAA,DAS,AAA,AAS,AAM,AAD

逻辑指令
- 逻辑运算指令
AND,OR,NOT,XOR,TEST
- 移位指令
SHL,SHR,SAL,SAR,ROL,ROR,RCL,RCR

串处理指令
- 设置方法标志指令
CLD: 设置方法为正向处理,di++
STD: 设置方法为负向处理,di--
- 串处理指令

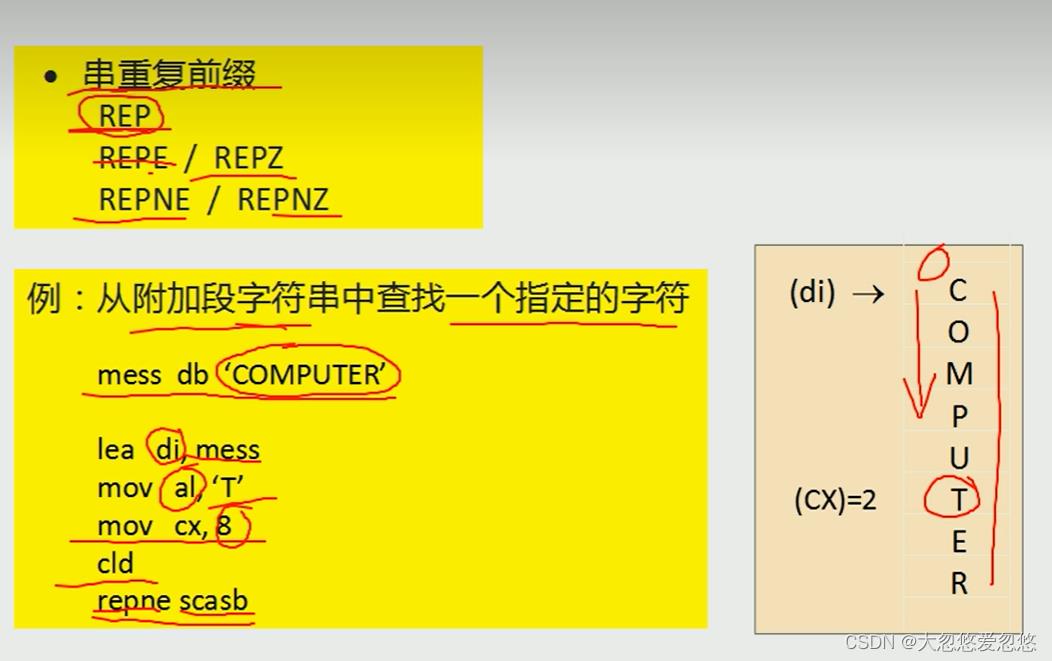
控制转移指令

处理机控制与杂项操作指令

汇编伪操作汇总

处理机选择伪操作

段定义伪操作
assume cs:code,ds:data,es:extra
data segment ;定义数据段
...
data ends
;-------------------------------
extra segment ;定义附加段
...
extra ends
;--------------------------------
extra segment ;定义代码段
start:
mov ax,data
mov ds,ax ;段地址 段寄存器
...
code ends
end start
- 完整段定义操作
ASSUME 段寄存器:段名[,其他段声明]
段名 SEGMENT [定位类型] [组合类型] [使用类型] ['类别']
....
....
段名 ENDS
定位类型 align_type ---指明当前段的内存对齐方式,即该段再进行内存分配时的一个策略
PARA BYTE(字节对齐) WORD(字对齐) DWORD(双字对齐) PAGE(整页对齐)
组合类型 combine_type (多文件组织时,对存储空间和栈空间共享策略)
PRIVATE PUBLIC COMMON STACK AT exp
使用类型 use_type (16位或者32位)
USE16 USE32
类型 'class'
- 定义存储模式,指定在内存中如何安放各段
.MODEL 存储模式 [,其他选项]
存储模式:
- tiny
- small
- medium
- compact
- large
- huge
- flat
- 简化的段定义–伪操作
.code[name]
.data
.data?
.fardata[name]
.fardata?[name]
.const
.stack[size]
- 一个输出hello world的例子

程序开始和结束伪操作
- TITLE text :定义标题
- NAME module_name: 定义模块名
- END [label]: 表示程序结束
- .STARTUP : 程序开始伪操作
- . EXIT [return_value] 程序结束伪操作
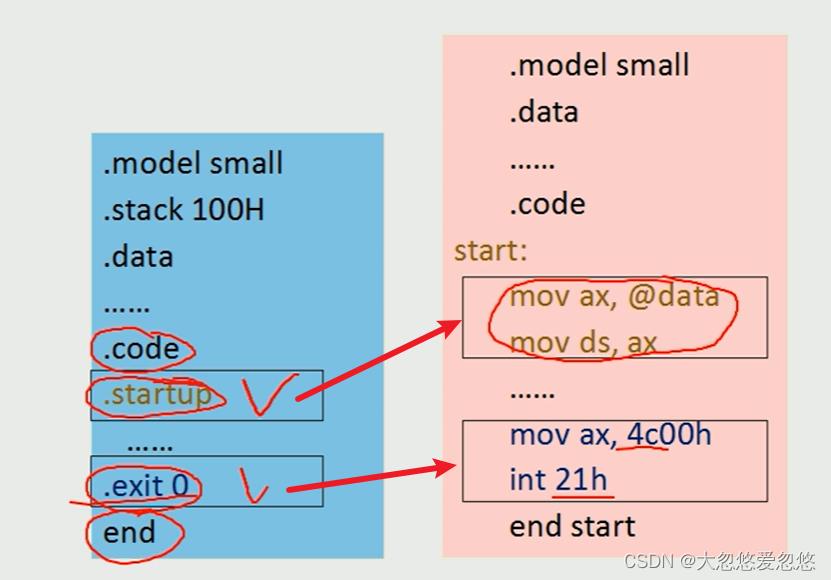
MASM 5.0/5.1不支持.startup和.exit
数据定义及存储器分配伪操作
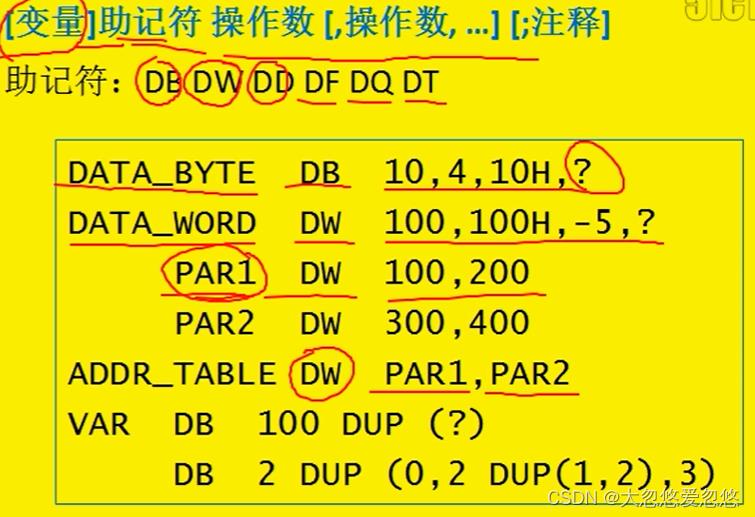
- DB定义字节数据,DW定义字数据,DD定义双字数据
变量名 LABEL type
功能: 同一个变量(同一个空间)将具有不同的类型
BYTE_ARRAY LABEL BYTE
WORD_ARRAY DW 50 DUP(?)

- 使用WORD_ARRAY标号来操作这块内存时,会按字为单位进行操作
- 使用BYTE_ARRAY标号来操作这块内存时,会按字节为单位进行操作
表达式赋值伪操作
- 表达式名 EQU 表达式
ALPUA EQU 9
BETA EQU ALPUA+18
BB EQU [BP+8]
- = 伪操作(可以重复定义)
EMP=7
EMP=EMP+1
因为EQU和=都是针对常量进行操作,因此这些值在编译时就可以确定下来,不会等待运行时再去通过cpu来确定
mov ax,beta+emp
等同于,写成上面那样,方便管理,但是常量编译时可以确定,因此编译后其实长下面这样
mov ax,0023H
地址计数器与对准伪操作
- ORG伪操作: 设置当前地址计数器的值
- 地址计数器$ :保存当前正在汇编的指令的地址
SEG1 SEGMENT
OGR 10
//默认分配在0地址处,但是上面有0RG,因此从10地址处进行分配
VAR1 DW 1234H
ORG 20
//从20地址处开始分配
VAR2 DW 5678H
//$为上面一条指令的地址
ORG $+8
//在$地址的基础上,加8,然后再对应的地址分配下面这个变量内存空间
VAR3 DW 1357H
- ALIGN伪操作: 包装数组边界从2的整数次幂地址开始
- EVEN伪操作: 使下一个变量或指令开始与偶数字节地址
ALIGN 4
ARRAY db 100 DUP(?)
A DB 'morning'
EVEN
B DW 2 DUP(?)
基数控制伪操作

如果不明确指定,默认使用当前规定的基数,如果在数值末尾明确指定了基数,则不使用全局默认基数。
汇编操作符汇总

算术操作符
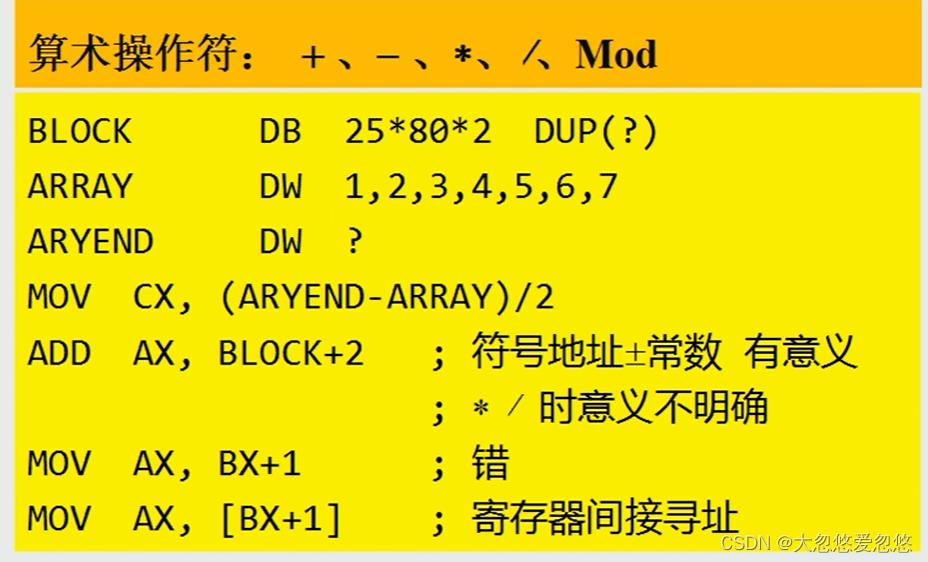
将一些基础的地址运算或者值计算,交给编译器在编译期间完成,等到编译完成后,形成的机器代码中,这些可以被计算出来的常量表达式都会被替换为对应的值
逻辑和移位操作符

关系操作符

为真的时候,是-1,是因为把0FFFFH看做是有符号数
数值回送操作符
- 数值回送操作符有下面这些:
OFFSET,SEG,TYPE,LENGTH,SIZE

ARRAY DW 100 DUP(?)
TABLE DB 'ABCD'
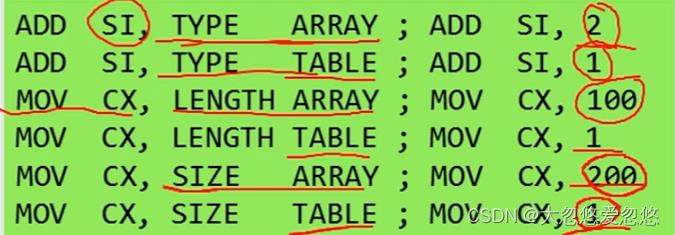
属性操作符


汇编过程
.exe的诞生

程序运行步骤及生成的文件
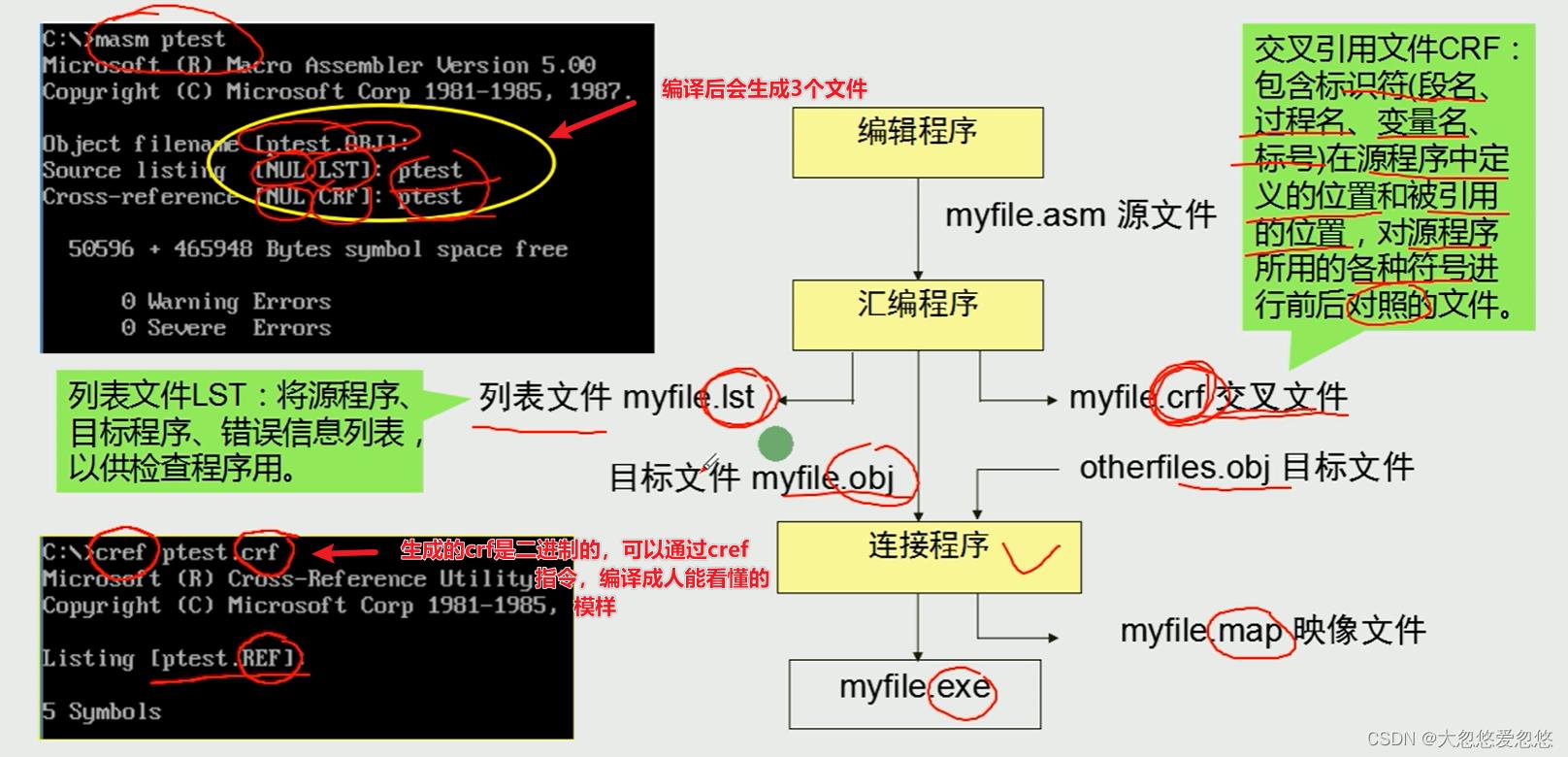
汇编过程

宏汇编
C语言中的预处理命令
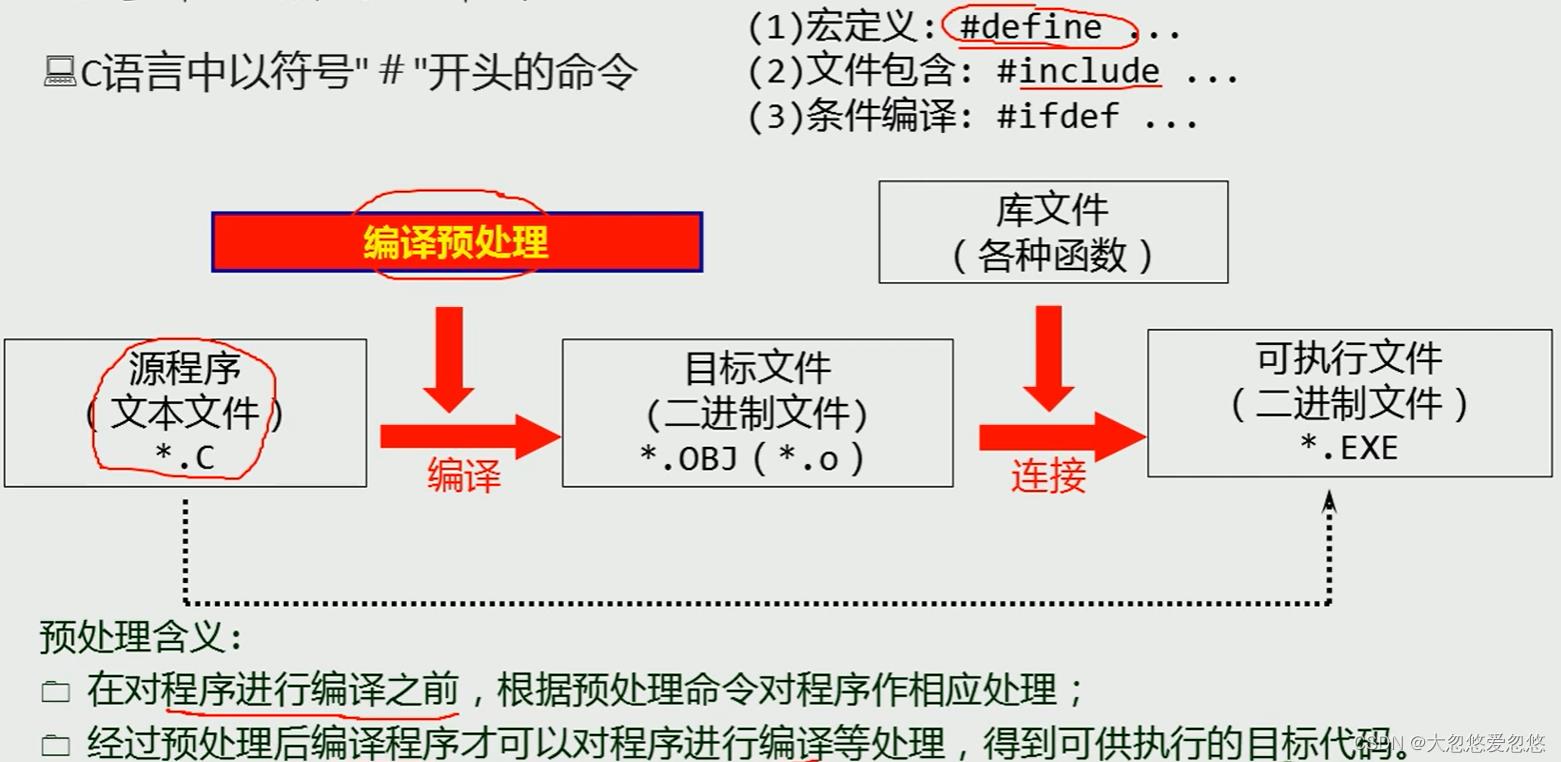
汇编中的宏—由C中的宏定义说起

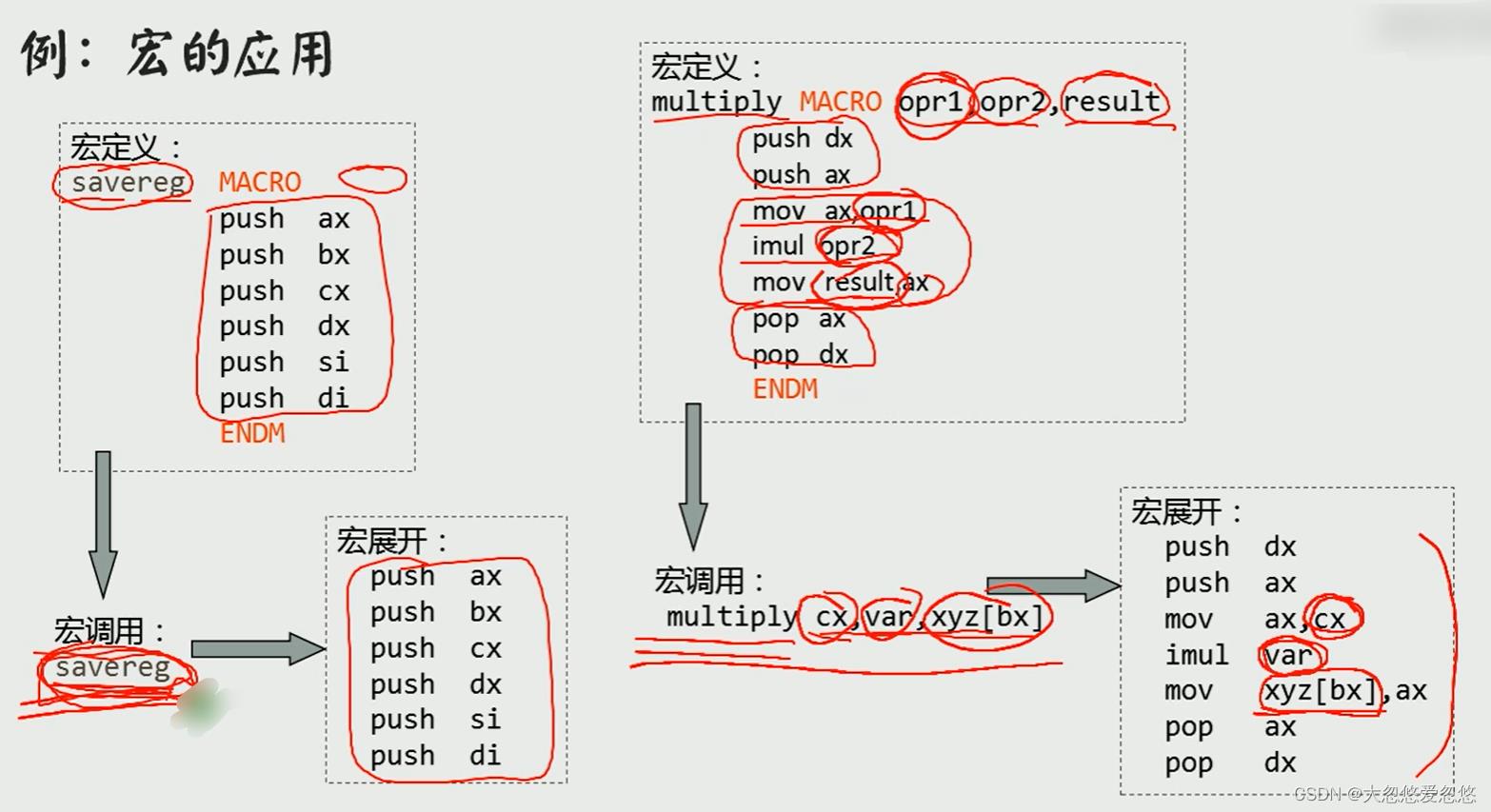
举例
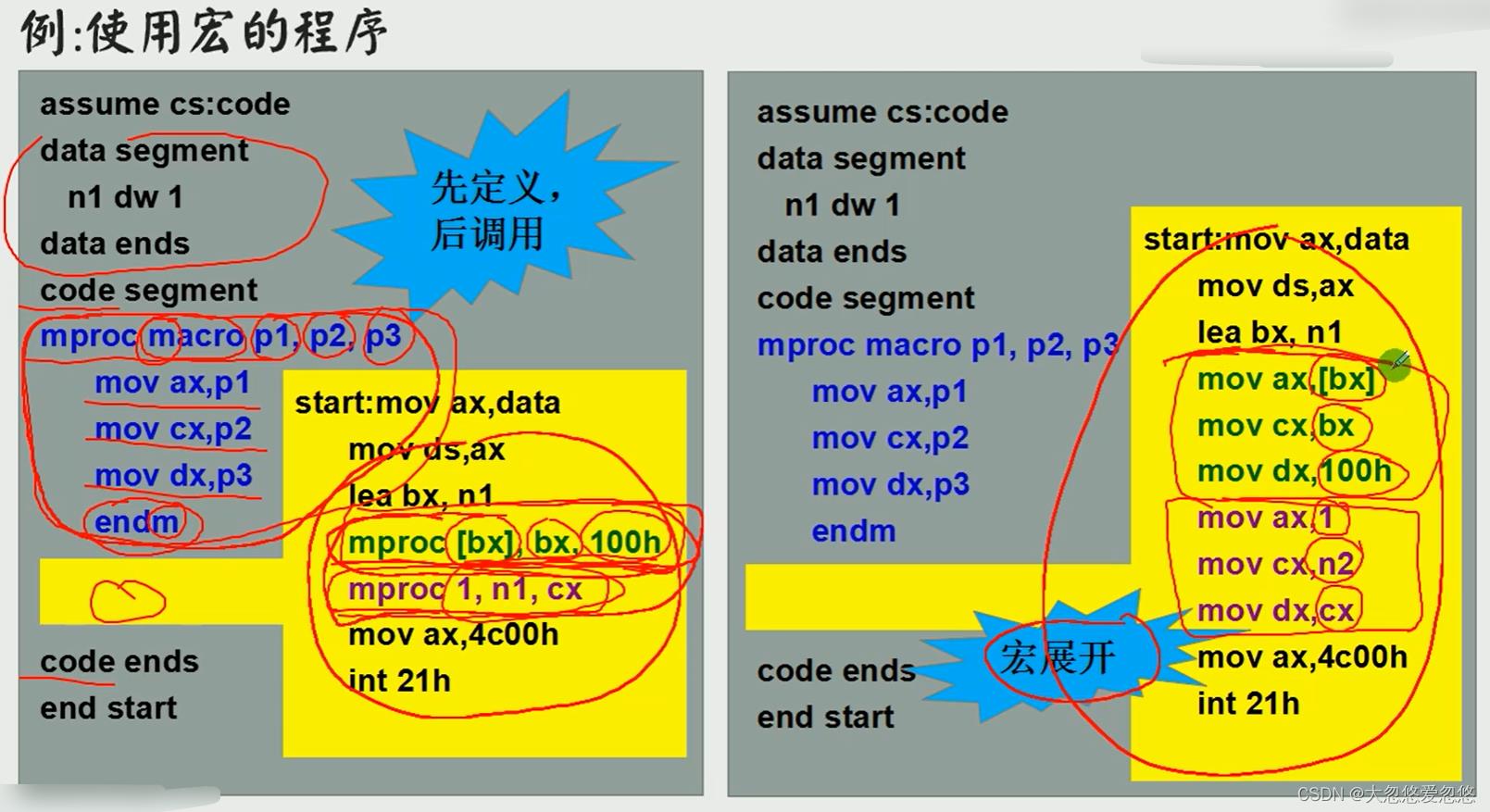
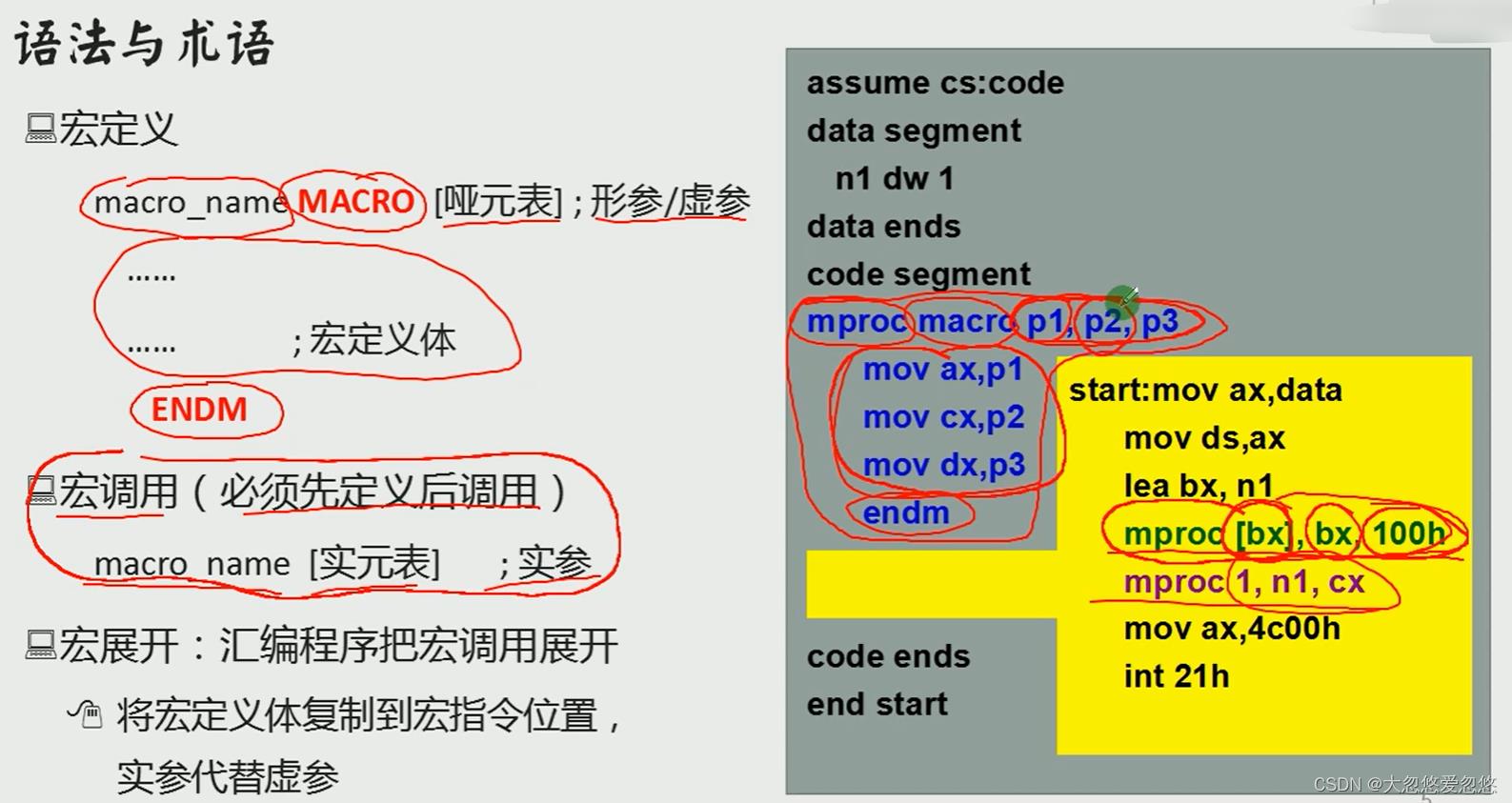
语法和术语
子程序VS宏定义
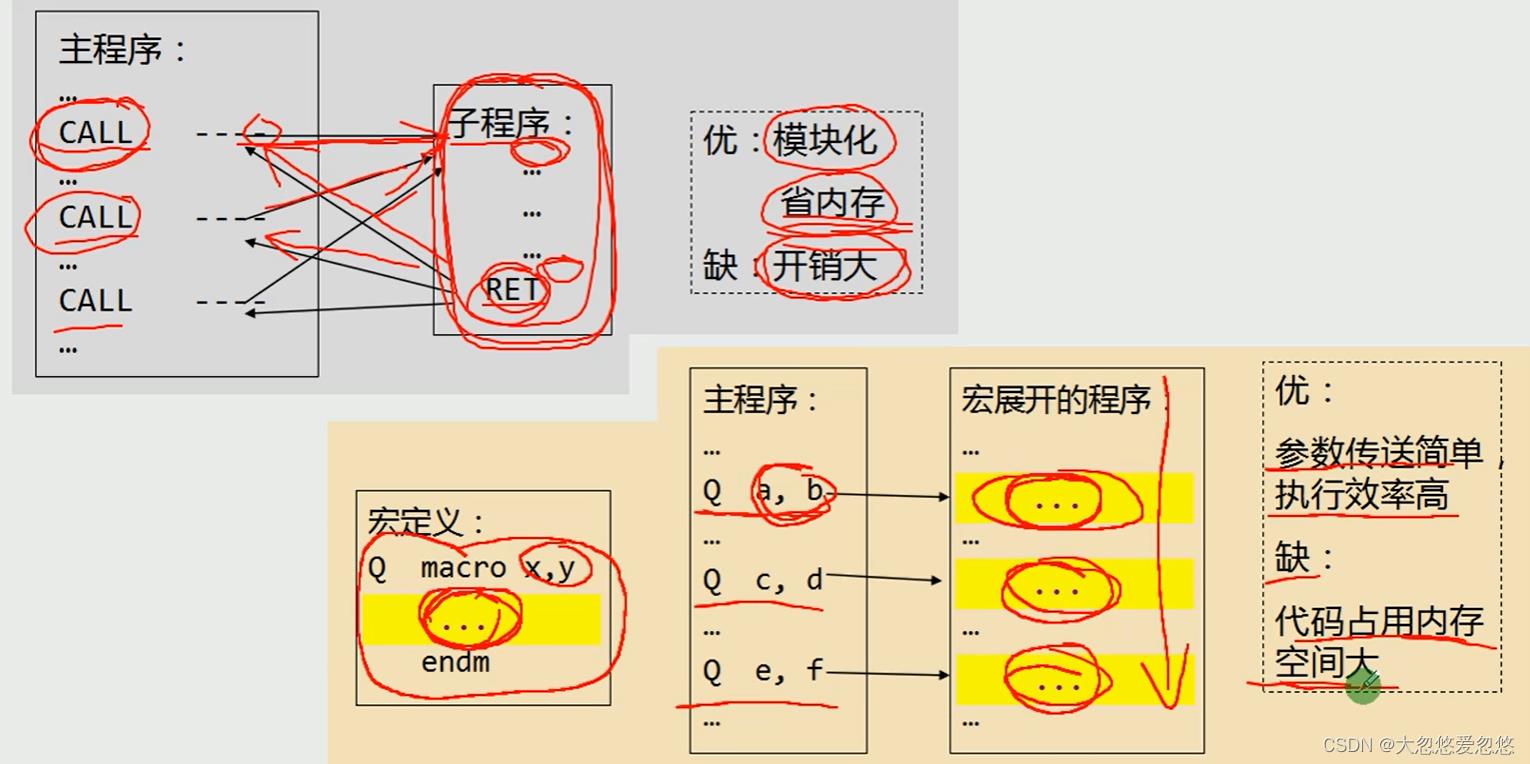
- 子程序每一次调用都需要保存现场,执行结束后,再恢复现场,因此开销很大
- 宏定义,会在编译时,进行宏展开,即将程序中用到宏的地方,全部替换为其本来的宏代码,这样带来的后果是,代码占用内存大,但是没有了保存现场和恢复现场带来的开销,开销小
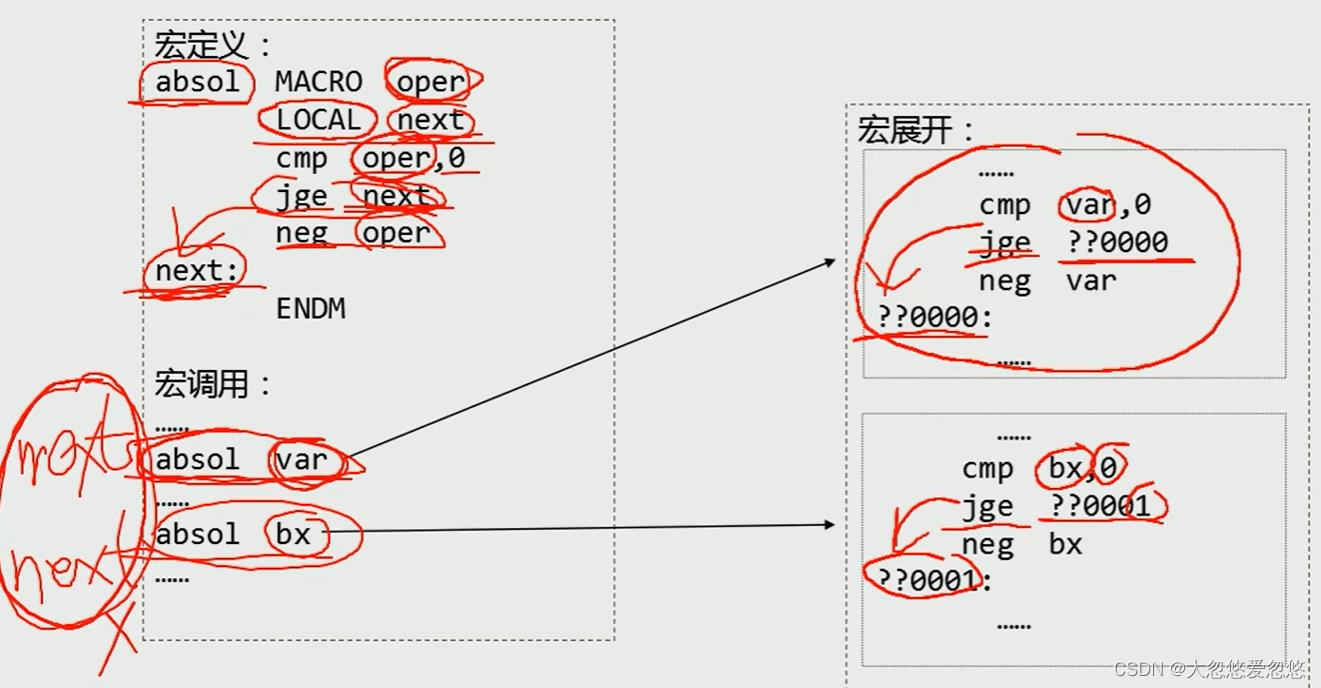
宏中的局部标号
- 一段子程序中不能出现两个重复的标号,但是如果一个宏定义里面,存在关于标号的定义,那么再一段子程序中,重复调用宏,再编译展开宏的时候,便会出现标号重复的问题,因此在宏中引入了局部标号,确保宏不会重复
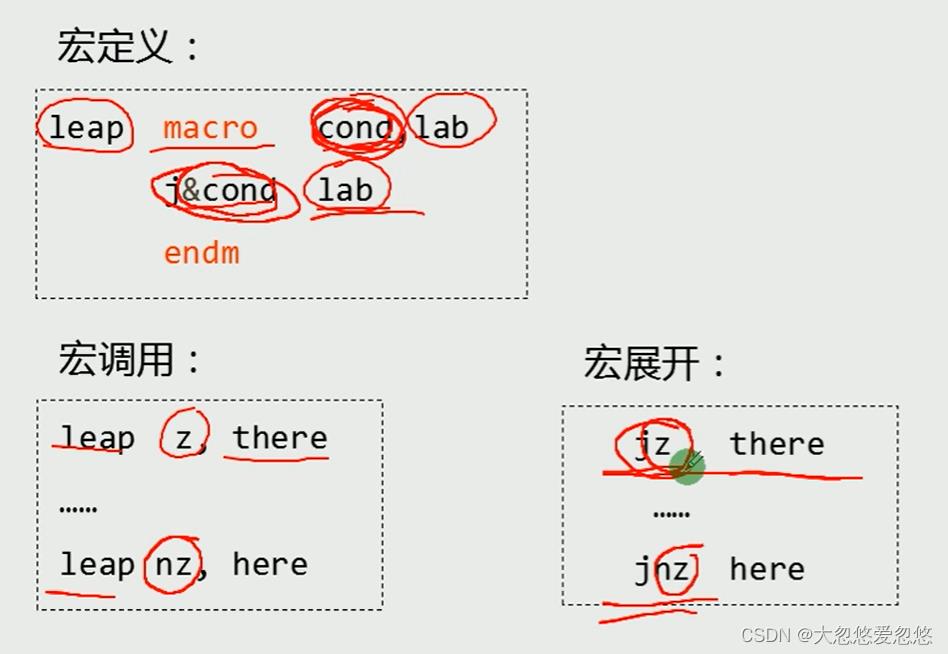
变元是操作码的一部分
- 变元也可以用在操作码部分,而不只是操作数部分
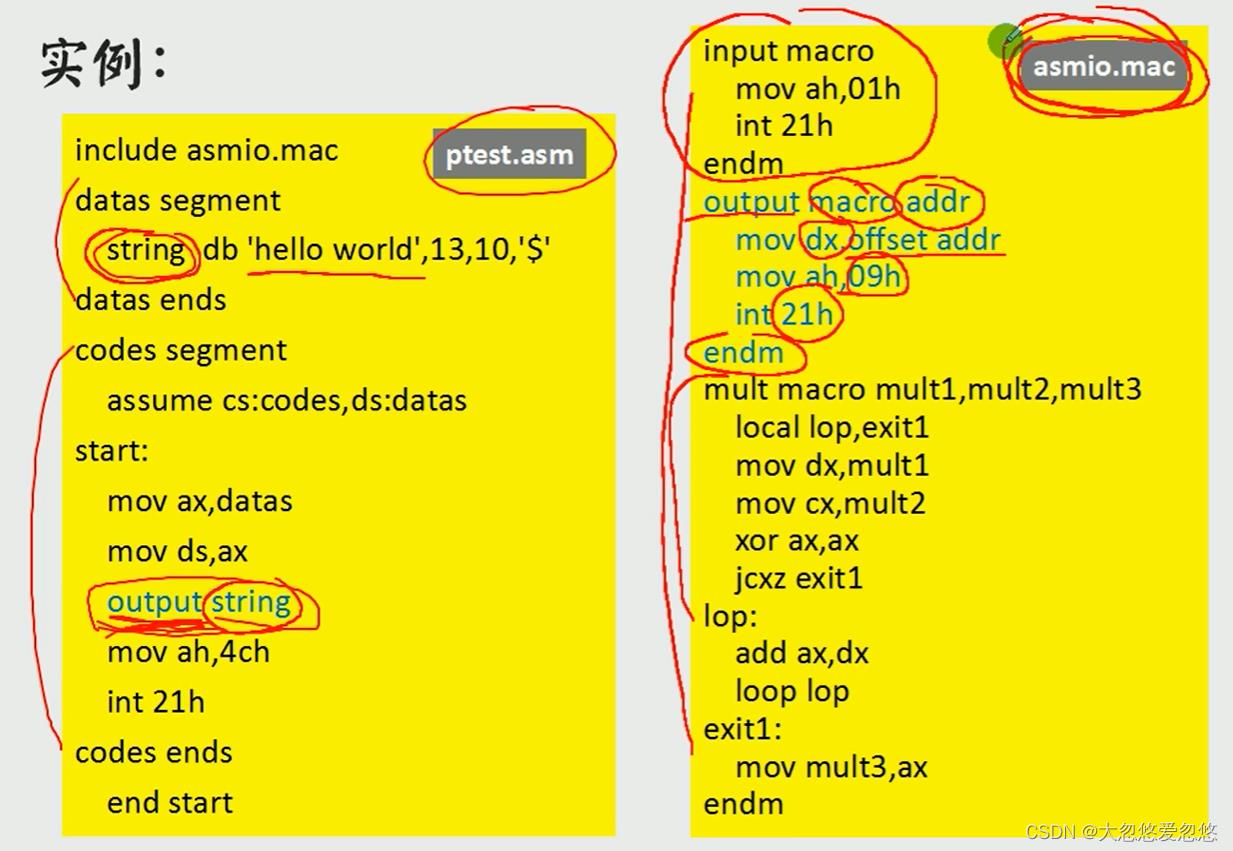
宏库
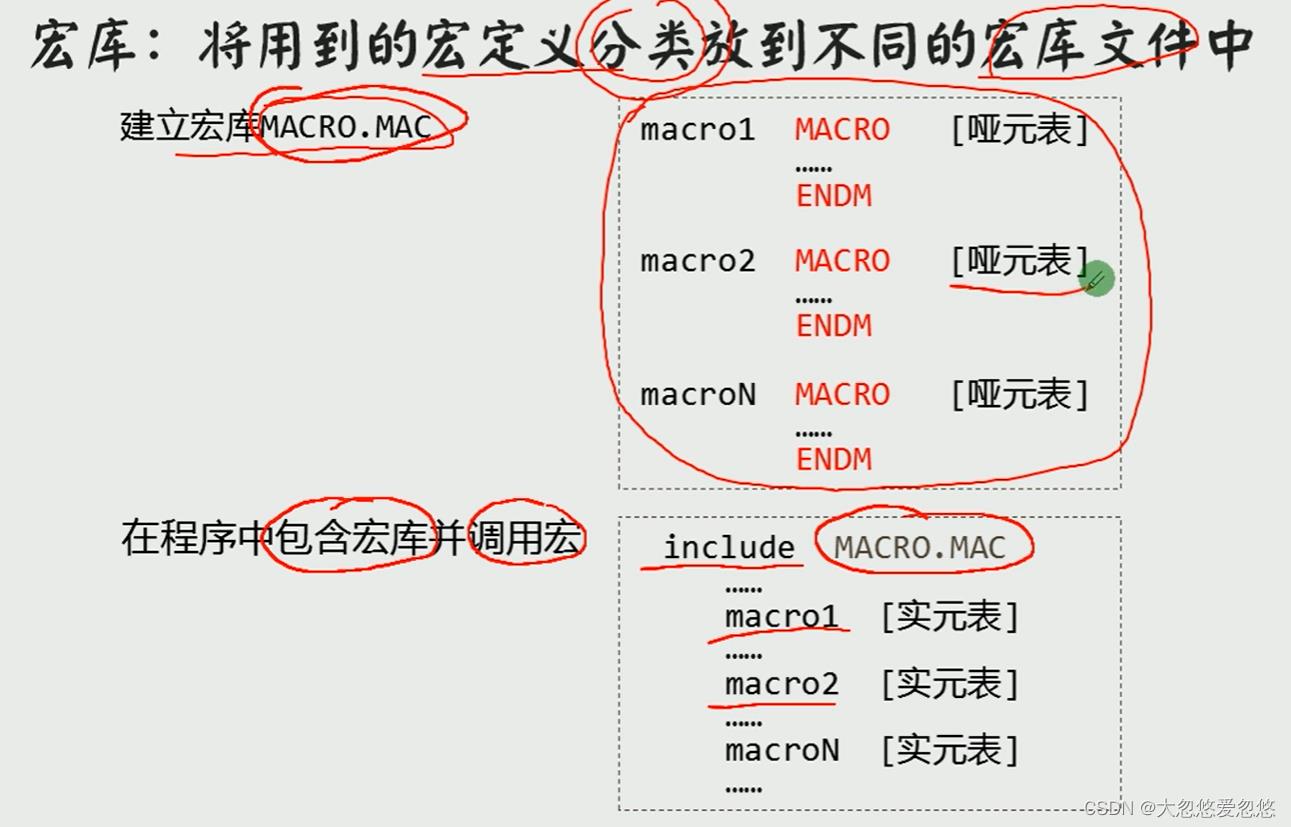
- 宏库的原理就是在编译时,将宏库中所有代码cpoy一份到inlucde该宏库的文件中来
条件汇编

举例

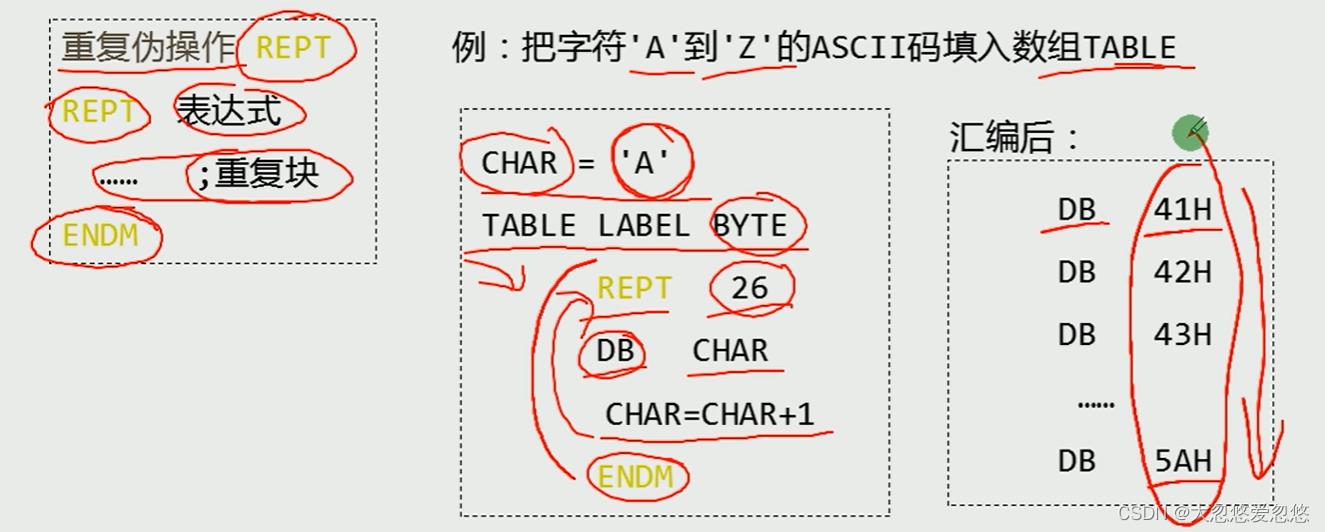
重复汇编: 用于连续产生完全相同或者基本相同的一组代码
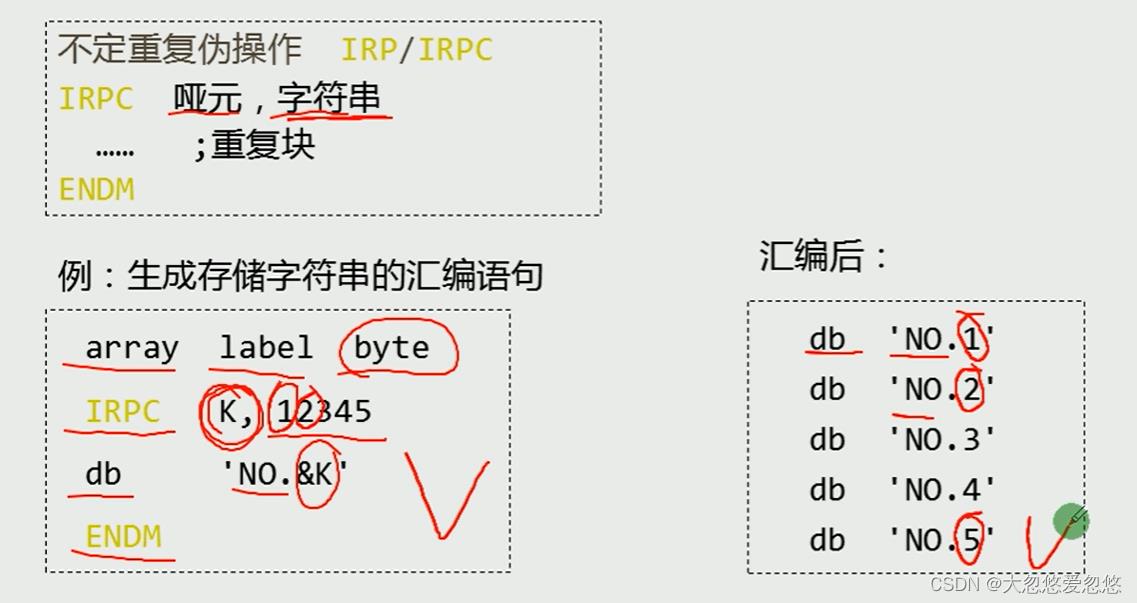
不定重复伪操作IRP

不定重复伪操作IRPC
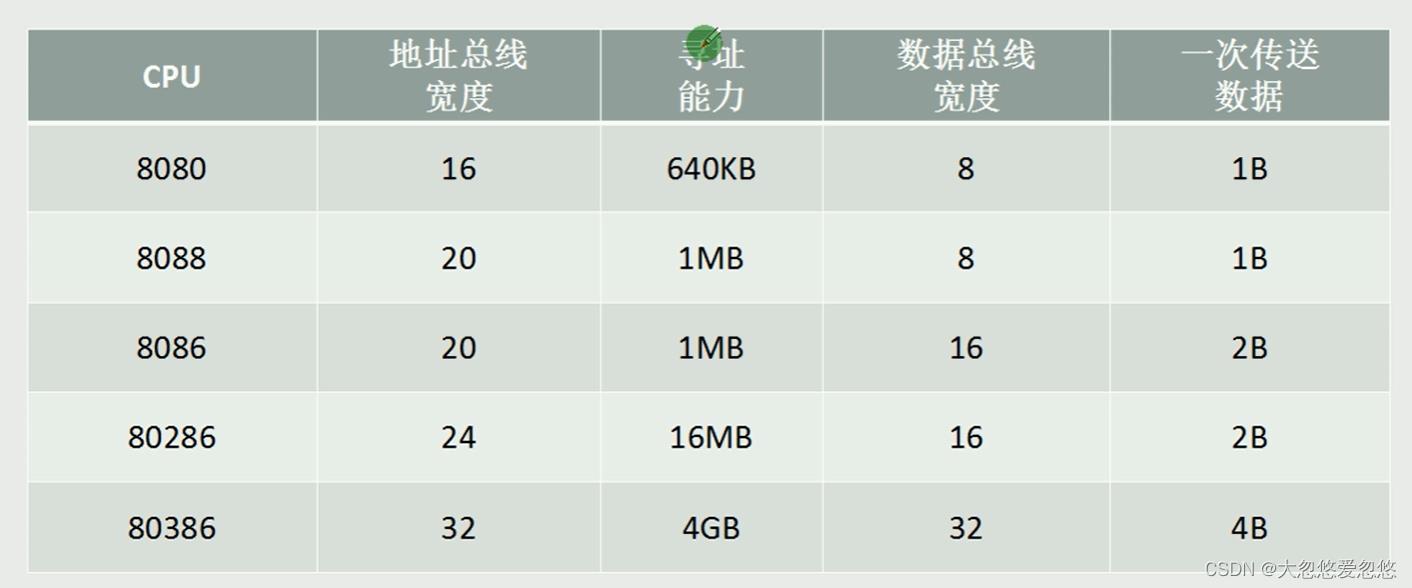
80X86汇编
80x86 cpu性能一览
80x86寄存器结构
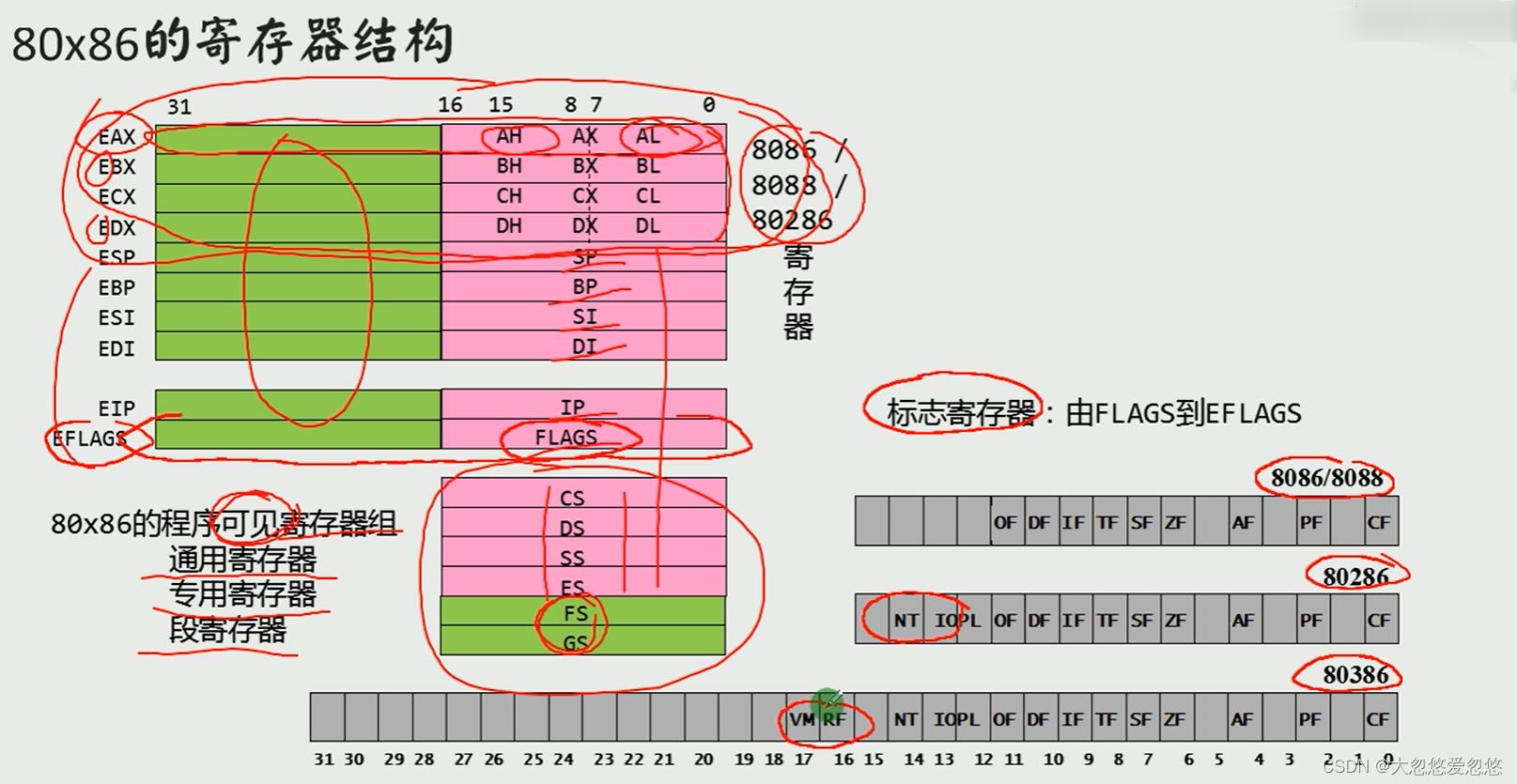
- 对于80x86来说,除了相关段寄存器没有扩展到32位,其他寄存器都扩展到了32位,而扩展到32位后的寄存器,如果要使用,只需要在原先寄存器名字前,加上一个E即可,E表示extend
80x86寻址方式

80x86的指令系统

80x86新增指令

条件设置指令
- 设置的是标志寄存器的值

Intel系列微处理器的3种工作模式


以上是关于汇编语言--高级汇编技术的主要内容,如果未能解决你的问题,请参考以下文章