一个开发者自述:我是如何设计针对冷热读写场景的 RocketMQ 存储系统
Posted Hollis Chuang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一个开发者自述:我是如何设计针对冷热读写场景的 RocketMQ 存储系统相关的知识,希望对你有一定的参考价值。

01
悸动
Aliware
32 岁,码农的倒数第二个本命年,平淡无奇的生活总觉得缺少了点什么。
想要去创业,却害怕家庭承受不住再次失败的挫折,想要生二胎,带娃的压力让我想着还不如去创业;所以我只好在生活中寻找一些小感动,去看一些老掉牙的电影,然后把自己感动得稀里哗啦,去翻一些泛黄的书籍,在回忆里寻找一丝丝曾经的深情满满;去学习一些冷门的知识,最后把自己搞得晕头转向,去参加一些有意思的比赛,捡起那 10 年走来,早已被刻在基因里的悸动。
那是去年夏末的一个傍晚,我和同事正闲聊着西湖的美好,他们说看到了阿里云发布云原生编程挑战赛,问我要不要试试。我说我只有九成的把握,另外一成得找我媳妇儿要;那一天,我们绕着西湖走了好久,最后终于达成一致,Ninety Percent 战队应运而生,云原生 MQ 的赛道上,又多了一个艰难却坚强的选手。
人到中年,仍然会做出一些冲动的决定,那种屁股决定脑袋的做法,像极了领导们的睿智和 18 岁时我朝三暮四的日子;夏季的 ADB 比赛,已经让我和女儿有些疏远,让老婆对我有些成见;此次参赛,必然是要暗度陈仓,卧薪尝胆,不到关键时刻,不能让家里人知道我又在卖肝。
02
开工
Aliware
你还别说,或许是人类的本性使然,这种背着老婆偷偷干坏事情的感觉还真不错,从上路到上分,一路顺风顺水,极速狂奔;断断续续花了大概两天的时间,成功地在 A 榜拿下了 first blood;再一次把第一名和最后一名同时纳入囊中;快男总是不会让大家失望了,800 秒的成绩,成为了比赛的 base line。
第一个版本并没有做什么设计,基本上就是拍脑门的方案,目的就是把流程跑通,尽快出分,然后在保证正确性的前提下,逐步去优化方案,避免一开始就过度设计,导致迟迟不能出分,影响士气。
03
整体设计
Aliware
先回顾下赛题:Apache RocketMQ 作为一款分布式的消息中间件,历年双十一承载了万亿级的消息流转,其中,实时读取写入数据和读取历史数据都是业务常见的存储访问场景,针对这个混合读写场景进行优化,可以极大的提升存储系统的稳定性。

基本思路是:当 append 方法被调用时,会将传入的相关参数包装成一个 Request 对象,put 到请求队列中,然后当前线程进入等待状态。
聚合线程会循环从请求队列里面消费 Request 对象,放入一个列表中,当列表长度到达一定数量时,就将该列表放入到聚合队列中。这样在后续的刷盘线程中,列表中的多个请求,就能进行一次性刷盘了,增大刷盘的数据块的大小,提升刷盘速度;当刷盘线程处理完一个请求列表的持久化逻辑之后,会依次对列表中个各个请求进行唤醒操作,使等待的测评线程进行返回。
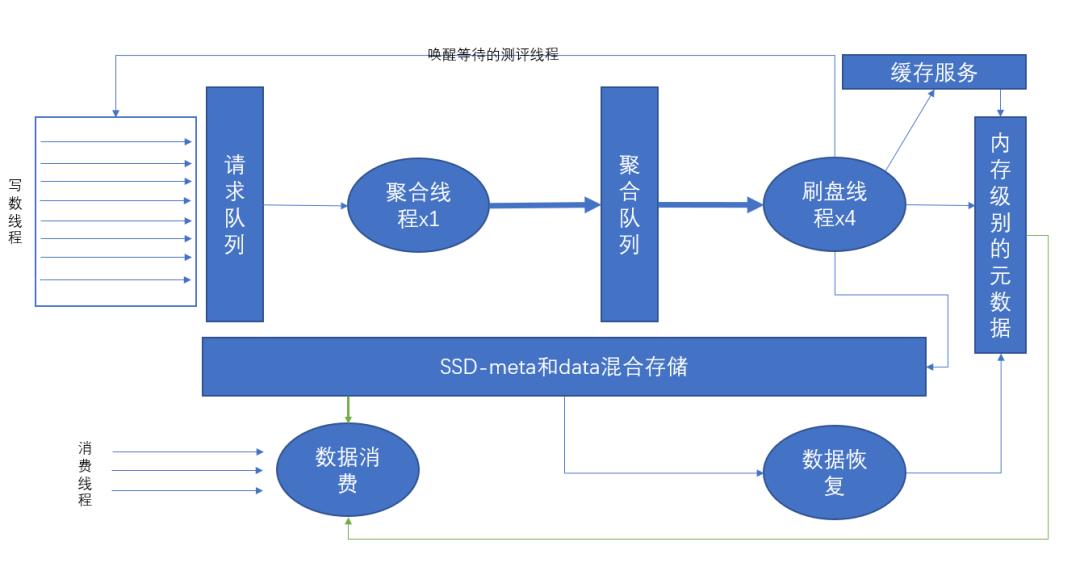
01
内存级别的元数据结构设计
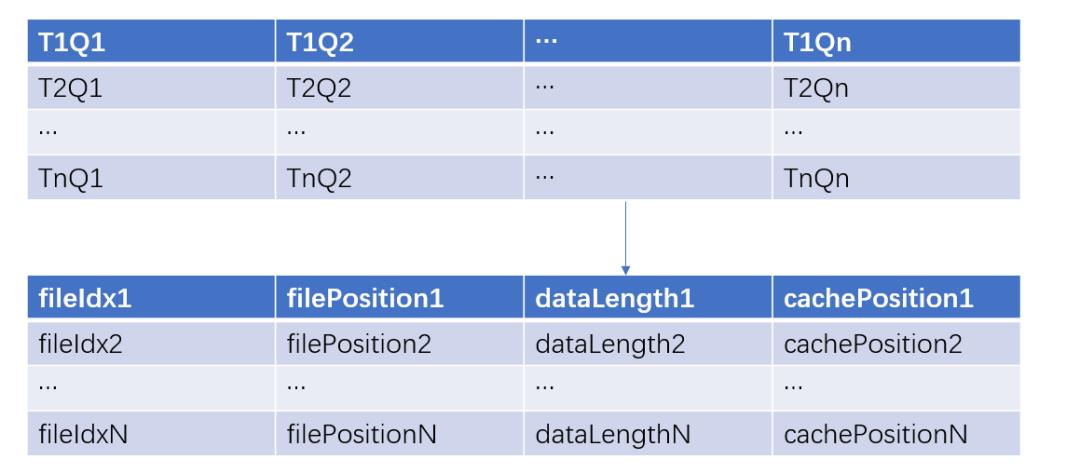
<![endif]–> 首先用一个二维数组来存储各个 topicId+queueId 对应的 DataMeta 对象,DataMeta 对象里面有一个 MetaItem 的列表,每一个 MetaItem 代表的一条消息,里面包含了消息所在的文件下标、文件位置、数据长度、以及缓存位置。
02
SSD 上数据的存储结构

总共使用了 15 个 byte 来存储消息的元数据,消息的实际数据和元数据放在一起,这种混合存储的方式虽然看起来不太优雅,但比起独立存储,可以减少一半的 force 操作。
03
数据恢复
依次遍历读取各个数据文件,按照上述的数据存储协议生成内存级别的元数据信息,供后续查询时使用。
04
数据消费
数据消费时,通过 topic+queueId 从二维数组中定位到对应的 DataMeta 对象,然后根据 offset 和 fetchNum,从 MetaItem 列表中找到对应的 MetaItem 对象,通过 MetaItem 中所记录的文件存储信息,进行文件加载。
总的来说,第一个版本在大方向上没有太大的问题,使用 queue 进行异步聚合和刷盘,让整个程序更加灵活,为后续的一些功能扩展打下了很好的基础。
04
缓存
Aliware
60 个 G的 AEP,我垂涎已久,国庆七天,没有出远门的计划,一定要好好卷一卷 llpl。下载了 llpl 的源码,一顿看,发现比我想象的要简单得多,本质上和用 unsafe 访问普通内存是一模一样的。卷完 llpl,缓存设计方案呼之欲出。
01
缓存分级
缓存的写入用了队列进行异步化,避免对主线程造成阻塞(到比赛后期才发现云 SSD 的奥秘,就算同步写也不会影响整体的速度,后面我会讲原因);程序可以用作缓存的存储介质有 AEP 和 Dram,两者在访问速度上有一定的差异,赛题所描述的场景中,会有大量的热读,因此我对缓存进行了分级,分为了 AEP 缓存和 Dram 缓存,Dram 缓存又分为了堆内缓存、堆外缓存、MMAP 缓存(后期加入),在申请缓存时,优先使用 Dram 缓存,提升高性能缓存的使用频度。
Dram 缓存最后申请了 7G,AEP 申请了 61G,Dram 的容量占比为 10%;本次比赛总共会读取(61+7)/2+50=84G 的数据,根据日志统计,整个测评过程中,有 30G 的数据使用了 Dram 缓存,占比 35%;因为前 75G 的数据不会有读取操作,没有缓存释放与复用动作,所以严格意义上来讲,在写入与查询混合操作阶段,总共使用了 50G 的缓存,其中滚动使用了 30-7/2=26.5G 的 Dram 缓存,占比 53%。10%的容量占比,却滚动提供了 53%的缓存服务,说明热读现象非常严重,说明缓存分级非常有必要。
但是,现实总是残酷的,这些看似无懈可击的优化点在测评中作用并不大,毕竟这种优化只能提升查询速度,在读写混合阶段,读缓存总耗时是 10 秒或者是 20 秒,对最后的成绩其实没有任何影响!很神奇吧,后面我会讲原因。
02
缓存结构
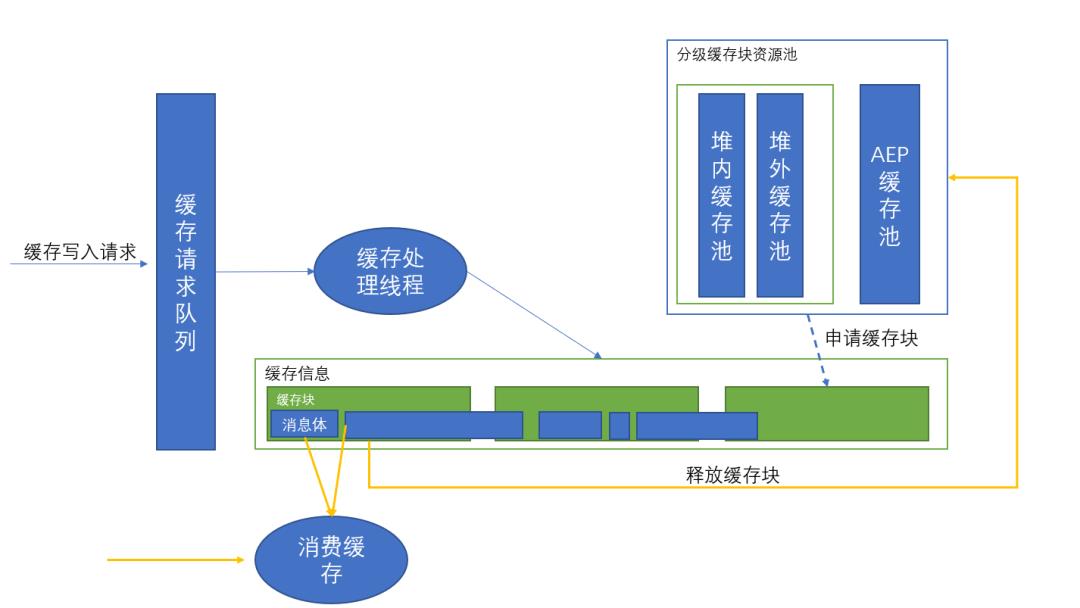
当获取到一个缓存请求后,会根据 topic+queueId 从二维数组中获取到对应的缓存上下文对象;该对象中维护了一个缓存块列表、以及最后一个缓存块的写入指针位置;如果最后一个缓存块的余量足够放下当前的数据,则直接将数据写入缓存块;如果放不下,则申请一个新的缓存块,放在缓存块列表的最后,同时将写不下的数据放到新缓存块中;若申请不到新的缓存块,则直接按缓存写入失败进行处理。
在写完缓存后,需要将缓存的位置信息回写到内存中的Meta中;比如本条数据是从第三个缓存块中的 123B 开始写入的,则回写的缓存位置为:(3-1)*每个缓存块的大小+123。在读取缓存数据时,按照 meta 数据中的缓存位置新,定位到对应的缓存块、以及块内位置,进行数据读取(需要考虑跨块的逻辑)。
由于缓存的写入是单线程完成的,对于一个 queueId,前面的缓存块的消息一定早于后面的缓存块,所以当读取完缓存数据后,就可以将当前缓存块之前的所有缓存都释放掉(放入缓存资源池),这样 75G 中被跳过的那 37.5G 的数据也能快速地被释放掉。
缓存功能加上去后,成绩来到了 520 秒左右,程序的主体结构也基本完成了,接下来就是精装了。
05
优化
Aliware
01
缓存准入策略
一个 32k 的缓存块,是放 2 个 16k 的数据合适,还是放 16 个 2k 的数据合适?毫无疑问是后者,将小数据块尽量都放到缓存中,可以使得最后只有较大的块才会查 ssd,减少查询时 ssd 的 io 次数。
那么阈值为多少时,可以保证小于该阈值的数据块放入缓存,能够使得缓存刚好被填满呢?(若不填满,缓存利用率就低了,若放不下,就会有小块的数据无法放缓存,读取时必须走 ssd,io 次数就上去了)。
一般来说,通过多次参数调整和测评尝试,就能找到这个阈值,但是这种方式不具备通用性,如果总的可用的缓存大小出现变化,就又需要进行尝试了,不具备生产价值。
这个时候,中学时代的数学知识就派上用途了,如下图: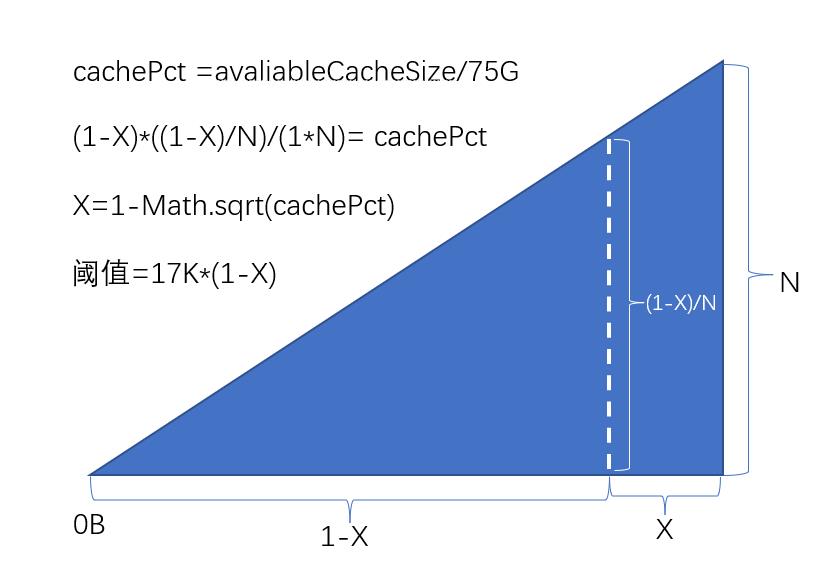
由于消息的大小实际是以 100B 开始的,为了简化,直接按照从 0B 进行了计算,这样会导致算出来的阈值偏大,也就是最后会出现缓存存不下从而小块走 ssd 查询的情况,所以我在算出来的阈值上减去了 100B*0.75(由于影响不大,基本是凭直觉拍脑门的)。如果要严格计算真正准确的阈值,需要将上图中的三角形面积问题,转换成梯形面积问题,但是感觉意义不大,因为 100B 本来就只有 17K 的 1/170,比例非常小,所以影响也非常的小。
梯形面积和三角形面积的比为:(17K+100)(17K-100)/(17k17K)=0.999965,完全在数据波动的范围之内。
在程序运行时,根据动态计算出来的阈值,大于该阈值的就直接跳过缓存的写入逻辑,最后不管缓存配置为多大,都能保证小于该阈值的数据块全部写入了缓存,且缓存最后的利用率达到 99.5%以上。
02
共享缓存
在刚开始的时候,按照算出来的阈值进行缓存规划,仍然会出现缓存容量不足的情况,实际用到的缓存的大小总是比总缓存块的大小小一些,通过各种排查,才恍然大悟,每个 queueId 所拥有的最后一个缓存块大概率是不会被写满的,宏观上来说,平均只会被写一半。一个缓存块是32k,queueId 的数量大概是 20w,那么就会有 20w*32k/2=3G 的缓存没有被用到;3G/2=1.5G(前 75G 之后随机读一半,所以要除以 2),就算是顺序读大块,1.5G 也会带来 5 秒左右的耗时,更别说随机读了,所以不管有多复杂,这部分缓存一定要用起来。
既然自己用不完,那就共享出来吧,整体方案如下:
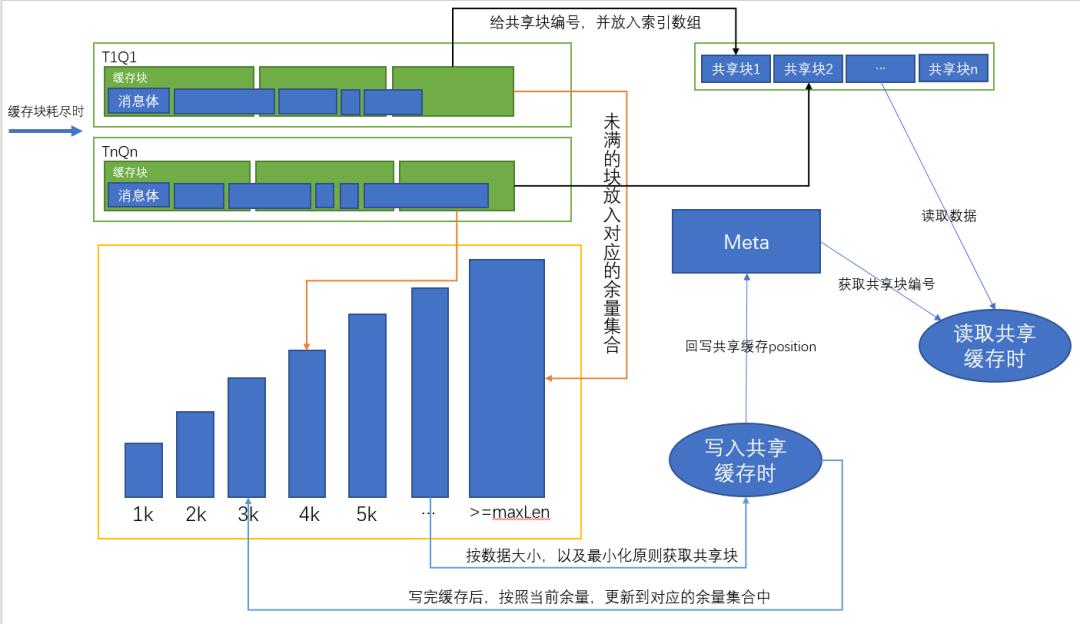
在缓存块用尽时,对所有的 queueId 的最后一个缓存块进行自增编号,然后放入到一个一维数组中,缓存块的编号,即为该块在以为数字中的下标;然后根据缓存块的余量大小,放到对应的余量集合中,余量大于等于 2k 小于 3k 的缓存块,放到 2k 的集合中,以此类推,余量大于最大消息体大小(赛题中为 17K)的块,统一放在 maxLen 的集合中。
当某一次缓存请求获取不到私有的缓存块时,将根据当前消息体的大小,从共享缓存集合中获取共享缓存进行写入。比如当前消息体大小为 3.5K,将会从 4K 的集合中获取缓存块,若获取不到,则继续从 5k 的集合中获取,依次类推,直到获取到共享缓存块,或者没有满足任何满足条件的缓存块为止。
往共享缓存块写入缓存数据后,该缓存块的余量将发生变化,需要将该缓存块从之前的集合中移除,然后放入新的余量集合中(若余量级别未发生变化,则不需要执行该动作)。
访问共享缓存时,会根据Meta中记录的共享缓存编号,从索引数组中获取到对应的共享块,进行数据的读取。
在缓存的释放逻辑里,会直接忽略共享缓存块(理论上可以通过一个计数器来控制何时该释放一个共享缓存块,但实现起来比较复杂,因为要考虑到有些消息不会被消费的情况,且收益也不会太大(因为二阶段缓存是完全够用的,所以就没做尝试)。
03
MMAP 缓存
测评程序的 jvm 参数不允许选手自己控制,这是拦在选手面前的一道障碍,由于老年代和年轻代之间的比例为 2 比 1,那意味着如果我使用 3G 来作为堆内缓存,加上内存中的 Meta 等对象,老年代基本要用 4G 左右,那就会有 2G 的新生代,这完全是浪费,因为该赛题对新生代要求并不高。
所以为了避免浪费,一定要减少老年代的大小,那也就意味着不能使用太多的堆内缓存;由于堆外内存也被限定在了 2G,如果减小堆内的使用量,那空余的缓存就只能给系统做 pageCache,但赛题的背景下,pageCache 的命中率并不高,所以这条路也是走不通的。
有没有什么内存既不是堆内,申请时又不受堆外参数的限制?自然而然想到了 unsafe,当然也想到官方导师说的那句:用 unsafe 申请内存直接取消成绩。。。这条路只好作罢。
花了一个下午的时间,通读了 nio 相关的代码,意外发现 MappedByteBuffer 是不受堆外参数的限制的,这就意味着可以使用 MappedByteBuffer 来替代堆内缓存;由于缓存都会频繁地被进行写与读,如果使用 Write_read 模式,会导致刷盘动作,就得不偿失了,自然而然就想到了 PRIVATE 模式(copy on write),在该模式下,会在某个 4k 区首次写入数据时,和 pageCache 解耦,生成一个独享的内存副本;所以只要在程序初始化的时候,将 mmap 写一遍,就能得到一块独享的,和磁盘无关的内存了。
所以我将堆内缓存的大小配置成了 32M(因为该功能已经开发好了,所以还是要意思一下,用起来),堆外申请了 1700M(算上测评代码的 300M,差不多 2G)、mmap 申请了 5G;总共有 7G 的 Dram 作为了缓存(不使用 mmap 的话,大概只能用到 5G),内存中的Meta大概有700M左右,所以堆内的内存差不多在 1G 左右,2G+5G+1G=8G,操作系统给 200M 左右基本就够了,所以还剩 800M 没用,这800M其实是可以用来作为 mmap 缓存的,主要是考虑到大家都只能用 8G,超过 8G 容易被挑战,所以最后最优成绩里面总的内存的使用量并没有超过 8G。
04
基于末尾填补的 4K 对齐
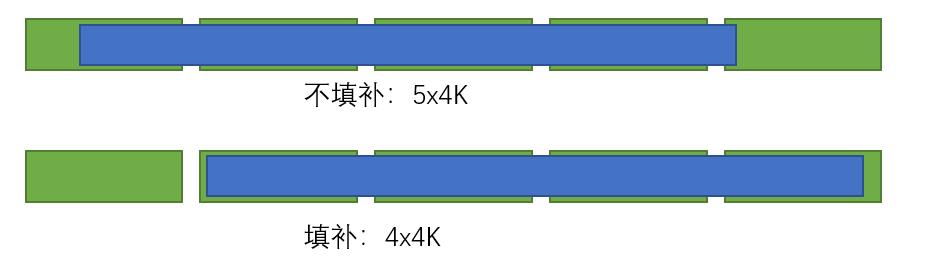
由于 ssd 的写入是以 4K 为最小单位的,但每次聚合的消息的总大小又不是 4k 的整数倍,所以这会导致每次写入都会有额外的开销。
比较常规的方案是进行 4k 填补,当某一批数据不是 4k 对齐时,在末尾进行填充,保证写入的数据的总大小是 4k 的整数倍。听起来有些不可思议,额外写入一些数据会导致整体效益更高?
是的,推导逻辑是这样的:“如果不填补,下次写入的时候,一定会写这未满的4k区,如果填补了,下次写入的时候,只有 50%的概率会往后多写一个 4k 区(因为前面填补,导致本次数据后移,尾部多垮了一个 4k 区)”,所以整体来说,填补后会赚 50%。或者换一个角度,填补对于当前的这次写入是没有副作用的(也就多 copy<4k 的数据),对于下一次写入也是没有副作用的,但是如果下一次写入是这种情况,就会因为填补而少写一个 4k。
05
基于末尾剪切的 4k 对齐
填补的方案确实能带来不错的提升,但是最后落盘的文件大概有 128G 左右,比实际的数据量多了 3 个 G,如果能把这 3 个 G 用起来,又是一个不小的提升。
自然而然就想到了末尾剪切的方案,将尾部未 4k 对齐的数据剪切下来,放到下一批数据里面,剪切下来的数据对应的请求,也在下一批数据刷盘的时候进行唤醒。
方案如下: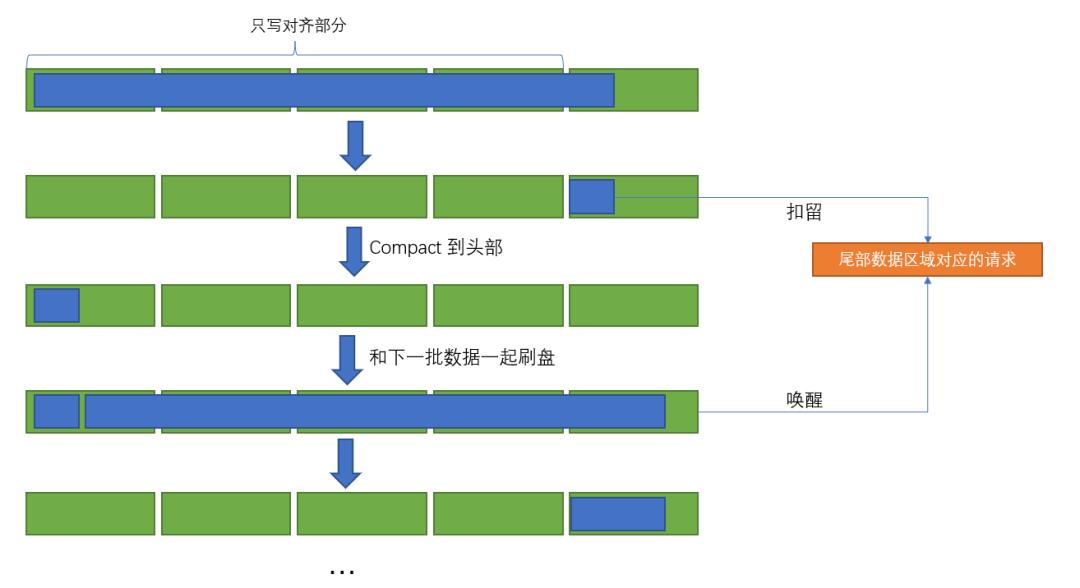
06
填补与剪切共存
剪切的方案固然优秀,但在一些极端的情况下,会存在一些消极的影响;比如聚合的一批数据整体大小没有操作 4k,那就需要扣留整批的请求了,在这一刻,这将变向导致刷盘线程大幅降低、请求线程大幅降低;对于这种情况,剪切对齐带来的优势,无法弥补扣留请求带来的劣势(基于直观感受),因此需要直接使用填补的方式来保证 4k 对齐。
严格意义上来讲,应该有一个扣留线程数代价、和填补代价的量化公式,以决定何种时候需要进行填补,何种时候需要进行剪切;但是其本质太过复杂,涉及到非同质因子的整合(要在磁盘吞吐、磁盘 io、测评线程耗时三个概念之间做转换);做了一些尝试,效果都不是很理想,没能跑出最高分。
当然中间还有一些边界处理,比如当 poll 上游数据超时的时候,需要将扣留的数据进行填充落盘,避免收尾阶段,最后一批扣留的数据得不到处理。
07
SSD 的预写
得此优化点者,得前 10,该优化点能大幅提升写入速度(280m/s 到 320m/s),这个优化点很多同学在一些技术贴上看到过,或者自己意外发现过,但是大部分人应该对本质的原因不甚了解;接下来我便循序渐进,按照自己的理解进行 yy 了。
假设某块磁盘上被写满了 1,然后文件都被删除了,这个时候磁盘上的物理状态肯定都还是 1(因为删除文件并不会对文件区域进行格式化)。然后你又新建了一个空白文件,将文件大小设置成了 1G(比如通过 RandomAccessFile.position(1G));这个时候这 1G 的区域对应的磁盘空间上仍然还是 1,因为在生产空白文件的时候也并不会对对应的区域进行格式化。
但是,当我们此时对这个文件进行访问的时候,读取到的会全是 0;这说明文件系统里面记载了,对于一个文件,哪些地方是被写过的,哪些地方是没有被写过的(以 4k 为单位),没被写过的地方会直接返回 0;这些信息被记载在一个叫做 inode 的东西上,inode 当然也是需要落盘进行持久化的。
所以如果我们不预写文件,inode 会在文件的某个 4k 区首次被写入时发生性变更,这将造成额外的逻辑开销以及磁盘开销。因此,在构造方法里面一顿 for 循环,按照预估的总文件大小,先写一遍数据,后续写入时就能起飞了。
08
大消息体的优化策略
由于磁盘的读写都是以 4k 为单位,这就意味着读取一个 16k+2B 的数据,极端情况下会产生 16k+2*4k=24k 的磁盘 io,会多加载将近 8k 的数据。
显然如果能够在读取的时候都按 4k 对齐进行读取,且加载出来的数据都是有意义的(后续能够被用到),就能解决而上述的问题;我依次做了以下优化(有些优化点在后面被废弃掉了,因为它和一些其他更好的优化点冲突了)。
1、大块置顶
<![endif]–> 由于每一批聚合的消息都是 4k 对齐的落盘的(剪切扣留方案之前),所以我将每批数据中最大的那条消息放在了头部(基于缓存规划策略,大消息大概率是不会进缓存的,消费时会从 ssd 读取),这样这条消息至少有一端是 4k 对齐的,读取的时候能缓解 50%的对齐问题,该种方式在剪切扣留方案之前确实带来了 3 秒左右的提升。
2、消息顺序重组
通过算法,让大块数据尽量少地出现两端不对齐的情况,减少读取时额外的数据加载量;比如针对下面的例子:
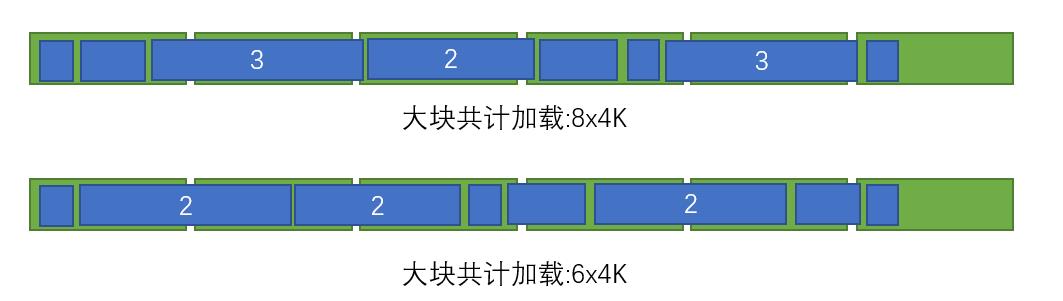
在整理之前,加载三个大块总共会涉及到 8 个 4k 区,整理之后,就变成了 6 个。
由于自己在算法这一块儿实在太弱了,加上这是一个 NP 问题,折腾了几个小时,效果总是差强人意,最后只好放弃。
3、基于内存的 pageCache
在数据读取阶段,每次加载数据时,若加载的数据两端不是 4k 对齐的,就主动向前后延伸打到 4k 对齐的地方;然后将首尾两个 4k 区放到内存里面,这样当后续要访问这些4k区的时候,就可以直接从内存里面获取了。
该方案最后的效果和预估的一样差,一点惊喜都没有。因为只会有少量的数据会走 ssd,首尾两个 4k 里面大概率都是那些不需要走ssd的消息,所以被复用的概率极小。
4、部分缓存
既然自己没能力对消息的存储顺序进行调整优化,那就把那些两端不对齐的数据剪下来放到缓存里面吧: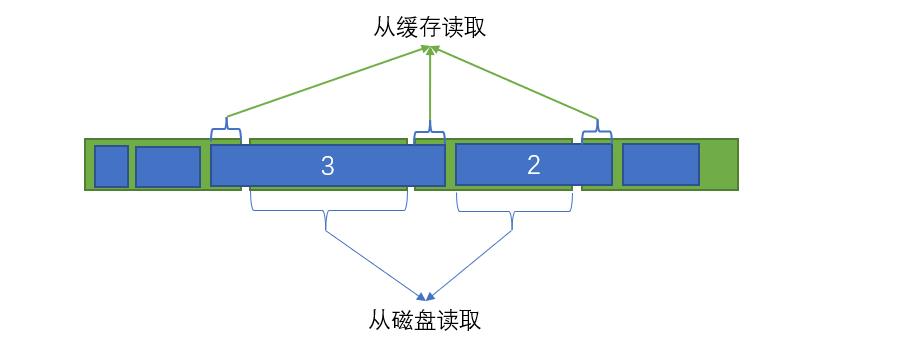
某条消息在落盘的时候,若某一端(也有可能是两端)没有 4k 对齐,且在未对齐的 4k 区的数据量很少,就将其剪切下来存放到缓存里,这样查询的时候,就不会因为这少量的数据,去读取一个额外的 4k 区了。
剪切的阈值设置成了 1k,由于数据大小是随机的,所以从宏观上来看,剪切下来的数据片的平均大小为 0.5k,这意味着只需要使用 0.5k 的缓存,就能减少 4k 的 io,是常规缓存效益的 8 倍,加上缓存部分的余量分级策略,会导致有很多碎片化的小内存用不到,该方案刚好可以把这些碎片内存利用起来。
09
测评线程的聚合策略
每次聚合多少条消息进行刷盘合适?是按消息条数进行聚合,还是按照消息的大小进行聚合?
刚开始的时候并没有想那么多,通过日志得知总共有 40 个线程,所以就写死了一次聚合 10 条,然后四个线程进行刷盘;但这会带来两个问题,一个是若线程数发生变化,性能会大幅下降;第二是在收尾阶段,会有一些跑得慢的线程还有不少数据未写入的情况,导致收尾时间较长,特别是加入了尾部剪切与扣留逻辑后,该现象尤为严重。
为了解决收尾耗时长的问题,我尝试了同步聚合的方案,在第一次写入之后的 500ms,对写入线程数进行统计,然后分组,后续就按组进行聚合;这种方式可以完美解决收尾的问题,因为同一个组里面的所有线程都是同时完成写入任务的,大概是因为每个线程的写入次数是固定的吧;但是使用这种方式,尾部剪切+扣留的逻辑就非常难融合进来了;加上在程序一开始就固定线程数,看起来也有那么一些不优雅;所以我就引入了“线程控制器”的概念。
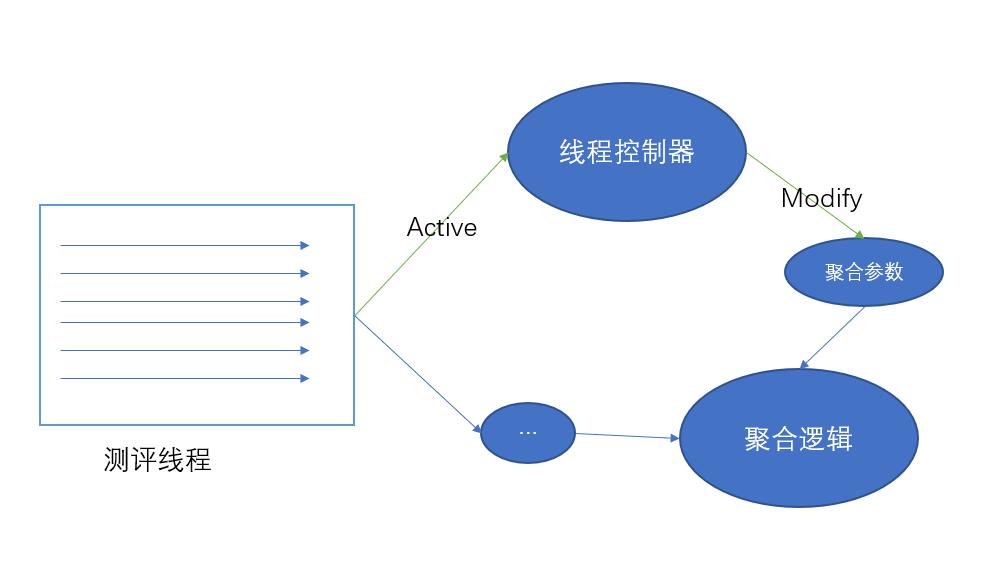
10
聚合策略迭代-针对剪切扣的留方案的定向优化
假设当前动态计算出来的聚合数量是 10,对于聚合出来的 10 条消息,如果本批次被扣留了 2 条,下次聚合时应该聚合多少条?
在之前的策略里面,还是会聚合 10 条,这就意味着一旦出现了消息扣留,聚合逻辑就会产生抖动,会出现某个线程聚合不到指定的消息数据量的情况(这种情况会有 poll 超时方式进行兜底,但是整体速度就慢了)。
所以聚合参数不能是一个单纯的、统一化的值,得针对不同的刷盘线程的扣留数,进行调整,假设聚合数为 n,某个刷盘线程的上批次扣留数量为 m,那针对这个刷盘线程的下批次的聚合数量就应该是 n-m。
那么问题就来了,聚合线程(生产者)只有一个,刷盘线程(消费者)有好几个,都是抢占式地进行消费,没办法将聚合到的特定数量的消息,给到指定的刷盘线程;所以聚合消息队列需要拆分,拆分成以刷盘线程为维度。
由于改动比较大,为了保留以前的逻辑,就引入了聚合数量的“严格模式”的概念,通过参数进行控制,如果是“严格模式”,就使用上述的逻辑,若不是,则使用之前的逻辑;
设计图如下:
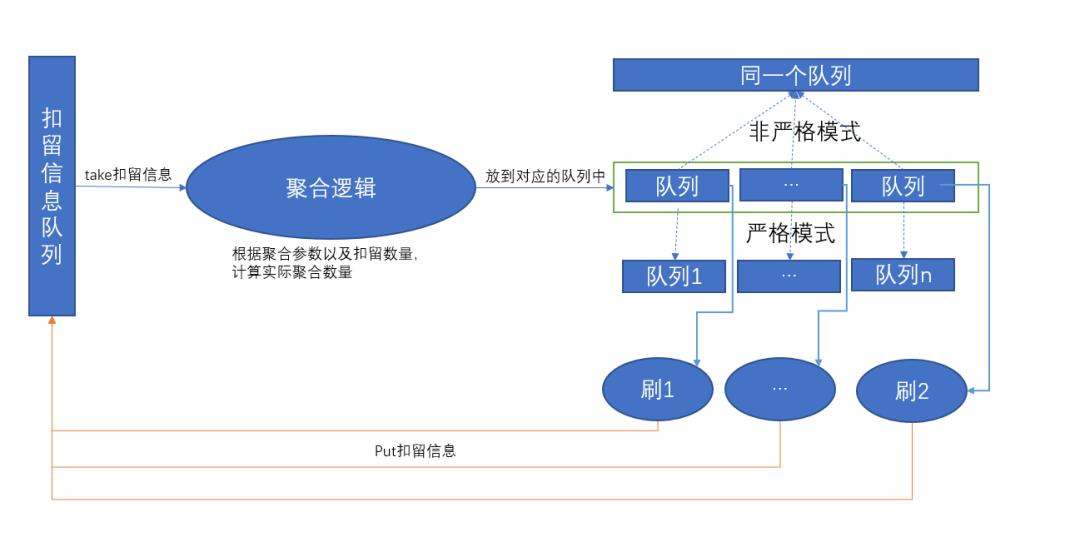
将聚合队列换成了聚合队列数组,在非严格模式下,数组里面的原始指向的是同一个队列对象,这样很多代码逻辑就能统一。
聚合线程需要先从扣留信息队列里面获取一个对象,然后根据扣留数和最新的聚合参数,决定要聚合多少条消息,聚合好消息后,放到扣留信息所描述的队列中。
06
完美的收尾策略,一行代码带来 5s 的提升
Aliware
引入了线程控制器后,收尾时间被降低到了 2 秒多,两次收尾,也就是 5 秒左右(这些信息来源于最后一个晚上对 A 榜时的日志的分析),在赛点位置上,这 5 秒的重要性不言而喻。
比赛结束前的最后一晚,分数徘徊在了 423 秒左右,前面的大佬在很多天前就从 430 一次性优化到了 420,然后分数就没有太大变化了;我当时抱着侥幸的态度,断定应该是 hack 了,直到那天晚上在钉钉群里和他聊了几句,直觉告诉我,420 的成绩是有效的。当时是有些慌的,毕竟比赛第二天早上 10 点就结束了。
我开始陷入深深的反思,我都卷到极致了,从 432 到 423 花费了大量的精力,为何大神能够一击致命?不对,一定是我忽略了什么。
我开始回看历史提交记录,然后对照分析每次提交后的测评得分(由于历史成绩都有一定的抖动,所以这个工作非常的上头);花费了大概两个小时,总算发现了一个异常点,在 432 秒附近的时候,我从同步聚合切换成了异步聚合,然后融合了剪切扣留+4k 填补的方案,按理说这个优化能减少 3G 多的落盘数据量,成绩应该是可以提升 10 秒左右的,但是当时成绩只提升了 5 秒多,由于当时还有不少没有落地的优化点,所以就没有太在意。
扣留策略会会将尾部的请求扣留下来,尾部的请求本来就是慢一拍(对应的测评线程慢)的请求(队列是顺序消费),这一扣留,进度就更慢了!!!
聚合到一批消息后,按照消息对应的线程被扣留的次数,从大到小排个序,让那些慢的、扣留多的线程,尽可能不被扣留,让那些快的、扣留少的请求,尽可能被扣留;最后所有的线程几乎都是同时完成(基于假想)。
赶紧提交代码、开始测评,抖了两把就破 420 了,最好成绩到达了 418,比优化前高出 5 秒左右,非常符合预期.
01
查询优化
多线程读 ssd
由于只有少量的数据会读 ssd,这使得在读写混合阶段,sdd 查询的并发量并不大,所以在加载数据时进行了判断,如果需要从 ssd 加载的数量大于一定量时,则进行多线程加载,充分利用 ssd 并发随机读的能力。
为什么要大于一定的量才多线程加载,如果只需要加载两条数据,用两个线程来加载会有提升吗?当存储介质够快、加载的数据量够小时,多线程加载数据带来的 io 时间的提升,还不足以弥补多线程执行本身带来的程序开销。
02
缓存的批量 copy
若某次查询时需要加载的数据,在缓存上是连续的,则不需要一条一条从缓存进行复制,可以以缓存块的大小为最小粒度,进行复制,提升缓存读取的效益。
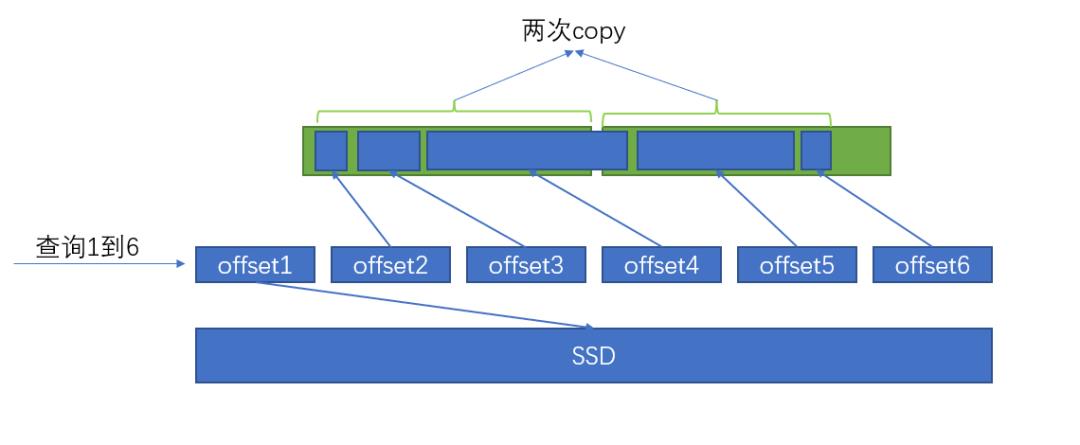
上面的例子中,使用批量 copy 的方式,可以将 copy 的次数从 5 次降到 2 次。
这样做的前提是:用于返回的各条消息对应的 byteBuffer,在内存上需要是连续的(通过反射实现,给每个 byteBuffer 都注入同一个 bytes 对象);批量复制完毕后,根据各条消息的大小,动态设置各自 byteBuffer 的 position 和 limit,以保证 retain 区域刚好指向自己所对应的内存区间。
该功能一直有偶现的 bug,本地又复现不了,A 榜的时候没太在意,B 榜的时候又不能看日志,一直没得到解决;怕因为代码质量影响最后的代码分,所以后来就注释掉了。
03
遗失的美好
在比赛开始的时候,看了金融通的赛题解析,里面提到了一个对数据进行迁移的点;10 月中旬的时候进行了尝试,在开始读取数据时,陆续把那些缓存中没有的数据读取到缓存中(因为一旦开始读取,就会有大量的缓存被释放出来,缓存容量完全够用),总共进行了两个方案的尝试:
1、基于顺序读的异步迁移方案
在第一阶段,当缓存用尽时,记录当前存储文件的位置,然后迁移的时候,从该位置开始进行顺序读取,将后续的所有数据都读取到缓存中;这样做的好处是大幅降低查询阶段的随机读次数;但是也有不足,因为前 75G 数据中有一般的数据是不会被消费的,这意味着迁移到缓存中的数据,有 50%都是没有意义的,当时测下来该方案基本没有提升(由于成绩有一定的抖动,具体是有一部分提升、没提升、还是负优化,也不得而知);后来引入了缓存准入策略后,该方案就彻底被废弃了,因为需要从 ssd 中读取的数据会完全散列在存储文件中。
2、基于懒加载的异步迁移方案
上面有讲到,由于一阶段的数据中有一半都不会被消费到,想要不做无用功,就必须要在保证迁移的数据都是会被消费的数据。
所以加了一个逻辑,当某个 queueId 第一次被消费的时候,就异步将该 queueId 中不存在缓存中的消息,从 ssd 中加载到缓存中;由于当时觉得就算是异步迁移,也是要随机读的,读的次数并不会减少,一段时间内磁盘的压力也并不会减少;所以对该方案就没怎么重视,完全是抱着写着玩的态度;并且在迁移的准入逻辑上加了一个判断:“当本次查询的消息中包含有从磁盘中加载的数据时,才异步对该 queueId 中剩下的 ssd 中的数据进行迁移”;至今我都没相透当时自己为什么要加上这个一个判断。也就是因为这个判断,导致迁移效果仍然不理想(会导致迁移不够集中、并且很多 queueId 在某次查询的时候读了 ssd,后续就没有需要从 ssd 上读取的数据了),对成绩没有明显的提升;在一次版本回退中,彻底将迁移的方案给抹掉了(相信打比赛的小伙伴对版本回退深有感触,特别是对于这种有较大成绩抖动的比赛)。
比赛结束后我在想,如果当时在迁移逻辑上没有加上那个神奇的逻辑判断,我的成绩能到多少?或许能到 410,或许突破不了 420;正式因为错过了那个大的优化点,才让我在其他点上做到了极致;那些错过的美好,会让大家在未来的日子里更加努力地奔跑。
接下来我们讲一下为什么异步迁移会快。
ssd 的多线程随机读是很快的,但是我上面有讲到,如果查询的数据量比较小,多线程分批查询效果并不一定就好,因为每一批的数据量实在太小了;所以想要在查询阶段开很多的线程来提升整体的查询速度并不能取的很好的效果。异步迁移能够完美地解决这个问题,并且在 io 次数一定的情况下,集中进行 ssd 的随机读,比散列进行随机读,pageCache 命中率更高,且对写入速度造成的整体影响更小(这个观点纯属个人感悟,只保证 Ninety Percent 的正确率)。
04
SSD 云盘的奥秘
我也是个小白,以下内容很多都是猜测,大家看一看就可以了。
1、云 ssd 的运作机制
SSD 云盘和传统的 ssd 盘拥有着相同的特性,但是却是不同的东西;可以理解成 SSD 云盘,是传统 ssd 盘的一个放大版
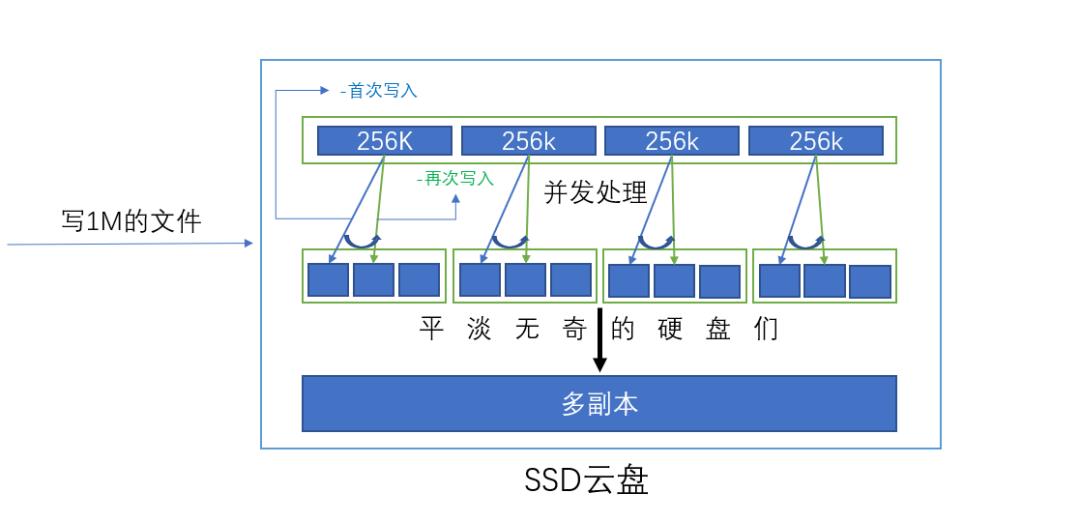
SSD 云盘的底层存储介质是多个普通的物理硬盘,这些物理硬盘就类似于传统 ssd 中的存储颗粒,在进行写入或读取的时候,会将任务分配到多个物理设备上并行进行处理。同时,在云 ssd 中,对数据的更新采用了 append 的方式,即在进行更新时,是顺序追加写一块数据,然后将位置的引用从原有的数据块指向新的数据块(我们访问的文件的position和硬盘的物理地址之间有一层映射,所以就算硬盘上有很多的碎片,我们也仍然能获取到一个“连续”的大文件)。
阿里云官网上有云 ssd 的 iops 和吞吐的计算公式:
iops = min1800+50 容量, 50000; 吞吐= min120+0.5 容量, 350
我们看到无论是 iops 和吞吐,都和容量呈正相关的关系,并且都有一个上限。这是因为,容量越大,底层的物理设备就会越多,并发处理的能力就越强,所以速度就越快;但是当物理设备多到一定的数量时,文件系统的“总控“就会成为瓶颈;这个总控肯定也是需要存储能力的(比如存储位置映射、历史数据的 compact 等等),所以当给总控配置不同性能的存储介质时,就得到了 PL0、PL1 等不同性能的云盘(当然,除此之外,网络带宽、运算能力也是云 ssd 速度的影响因子)。
2、云 ssd 的 buffer 现象
在过程中发现了一个有趣的现象,就算是 force 落盘,在刚开始写入时,速度也是远大于 320m/s 的(能达到 400+),几秒之后,会降下来,稳定在 320 左右(像极了不 force 时,pageCache 带来的 buffer 现象)。
针对这种奇怪的现象,我进行了进一步的探索,每写 2 秒的数据,就 sleep 2 秒,结果是:在写入的这两秒时间里,速度能达到 400+,整体平均速度也远超过了 160m/s;后来我又做了很多实验,包括在每次写完数据之后直接进行短暂的 sleep,但是这根本不会影响到 320m/s 的整体速度。测试代码中,虽然是 4 线程写入,但是总会有那么一些时刻,大部分甚至所有线程都处于 sleep 状态,这必然会使得在这个时间点上,应用程序到硬盘的写入速度是极低的;但是时间拉长了看,这个速度又是能恒定在 320m/s 的。这说明云 ssd 上有一层 buffer,类似操作系统的 pageCache,只是这个“pageCache”是可靠存储的,应用程序到这个 buffer 之间的速度是可以超过 320 的,320 的阈值,是下游所导致的(比如 buffer 到硬盘阵列)。
对于这个“pageCache”有几种猜测:
1、物理设备本身就有 buffer 效应,因为物理设备的存储状态本质上是通过电刺激,改变存储介质的化学状态或者物理状态的实现的,驱动这种变化的工业本质,产生了这种 buffer 现象‘;
2、云 ssd 里面有一块较小的高性能存介质作为缓冲区,以提供更好的突击写的性能;
3、逻辑限速,哈哈,这个纯属开玩笑了。
由于有了这个 buffer 效应,程序层面就可以为所欲为了,比如写缓存的动作,整体会花费几十秒,但是就算是在只有 4 个写入线程的情况下,不管是异步写还是同步写,都不会影响整体的落盘速度,因为在同步写缓存的时候,云 ssd 能够进行短暂的停歇,在接下来的写入时,速度会短暂地超过 320m/s;查询的时候也类似,非 io 以外的时间开销,无论长短,都不会影响整体的速度,这也就是我之前提到的,批量复制缓存,理论上有不小提升,但是实际上却没多大提升的原因。
当然,这个 buffer 现象其实是可以利用起来的,我们可以在写数据的时候多花一些时间来做一些其他的事情,反正这样的时间开销并不会影响整体的速度;比如我之前提到的 NP 问题,可以 for 循环暴力破解
07
参赛总结
Aliware
这次比赛的体验非常好,赛题有挑战、导师们也非常热情。比赛周期也适中,让我既有时间冲刺,也避免了频繁熬夜导致的家庭矛盾,媳妇儿是在最后一周看到了天池的页面,才发现我在打比赛。
2021 年参加了两次阿里云的比赛,都取得了不错的成绩,这再一次证明了我适合做技术,不适合做管理;今年工作的体验很不好,大概也是因为代码写少了吧。
很多问题或许不需要答案,一路向前,有人陪伴,上坡下坡,都有快乐。这就是我参加大赛之后感受很深刻的一点。
文章中的很多知识点,都是通过云原生编程挑战赛学到的,在一些问题在表述方式、甚至理解上都可能存在一些问题,甚至会有一些谬论;敢于尝试就会犯错,有犯错才会有成长,欢迎各位大佬不舍赐教,多多指正,让我们一起变得更强!
源码地址:https://code.aliyun.com/276059488/mqFinal.git
完
往期推荐

Lombok原理和同时使⽤@Data和@Builder 的坑
有道无术,术可成;有术无道,止于术
欢迎大家关注Java之道公众号

好文章,我在看❤️
以上是关于一个开发者自述:我是如何设计针对冷热读写场景的 RocketMQ 存储系统的主要内容,如果未能解决你的问题,请参考以下文章
赛道解析针对冷热读写场景的 RocketMQ 存储系统设计思路拆解