ArrayList和LinkedList的区别
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ArrayList和LinkedList的区别相关的知识,希望对你有一定的参考价值。
HashMap和Hashtable的区别
ArrayList和LinkedList的大致区别如下:
1.ArrayList是实现了基于动态数组的数据结构,LinkedList基于链表的数据结构。
2.对于随机访问get和set,ArrayList觉得优于LinkedList,因为LinkedList要移动指针。
3.对于新增和删除操作add和remove,LinedList比较占优势,因为ArrayList要移动数据。
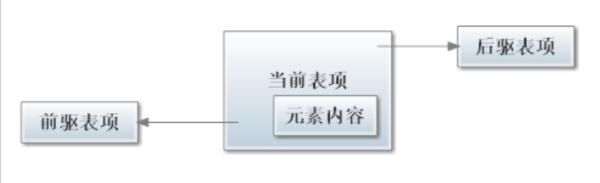
LinkedList链表由一系列表项连接而成。一个表项总是包含3个部分:元素内容,前驱表和后驱表,如图所示:
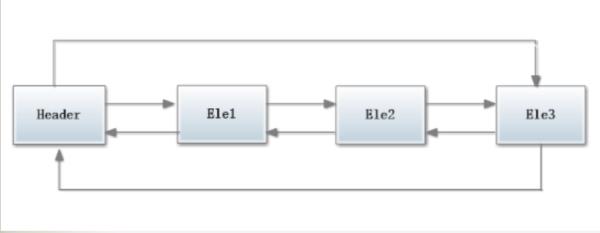
在下图展示了一个包含3个元素的LinkedList的各个表项间的连接关系。在JDK的实现中,无论LikedList是否为空,链表内部都有一个header表项,它既表示链表的开始,也表示链表的结尾。表项header的后驱表项便是链表中第一个元素,表项header的前驱表项便是链表中最后一个元素。
拓展资料
ArrayList就是动态数组,用MSDN中的说法,就是Array的复杂版本,它提供了动态的增加和减少元素,实现了ICollection和IList接口,灵活的设置数组的大小等好处。
List 接口的大小可变数组的实现,位于API文档的java.util.ArrayList<E>。实现了所有可选列表操作,并允许包括 null 在内的所有元素。除了实现 List 接口外,此类还提供一些方法来操作内部用来存储列表的数组的大小。
每个 ArrayList 实例都有一个容量。该容量是指用来存储列表元素的数组的大小。它总是至少等于列表的大小。随着向 ArrayList 中不断添加元素,其容量也自动增长。并未指定增长策略的细节,因为这不只是添加元素会带来分摊固定时间开销那样简单。
注意,迭代器的快速失败行为无法得到保证,因为一般来说,不可能对是否出现不同步并发修改做出任何硬性保证。快速失败迭代器会尽最大努力抛出 ConcurrentModificationException。
参考资料:百度百科-ArrayList词条
参考技术AArrayList和LinkedList
共性:ArrayList与LinkedList都是List接口的实现类,因此都实现了List的所有未实现的方法,只是实现的方式有所不同。
区别:List接口的实现方式不同
ArrayList实现了List接口,以数组的方式来实现的,因此对于快速的随机取得对象的需求,使用ArrayList实现执行效率上会比较好。
LinkedList是采用链表的方式来实现List接口的,因此在进行insert和remove动作时效率要比ArrayList高。适合用来实现Stack(堆栈)与Queue(队列)。
HashTable和HashMap
共性:都实现了Map接口。
区别:
(1)继承的父类不同
Hashtable继承自Dictionary类,而HashMap继承自AbstractMap类。
(2)线程安全性不同
Hashtable的方法是Synchronize的,而HashMap中的方法在缺省情况下是非Synchronize的。
(3)提供contains方法
HashMap把Hashtable的contains方法去掉了,改成containsValue和containsKey,因为contains方法容易让人引起误解。
Hashtable则保留了contains,containsValue和containsKey三个方法,其中contains和containsValue功能相同。
(4)key和value是否允许null值
Hashtable中,key和value都不允许出现null值。HashMap中,null可以作为键,这样的键只有一个;可以有一个或多个键所对应的值为null。
(5)两个遍历方式的内部实现上不同
HashMap使用了 Iterator;Hashtable使用 Iterator,Enumeration两种方式 。
(6)hash值不同
哈希值的使用不同,HashTable直接使用对象的hashCode。而HashMap重新计算hash值。
(7)内部实现使用的数组初始化和扩容方式不同
HashTable在不指定容量的情况下的默认容量为11,增加的方式是 old*2+1;而HashMap为16,Hashtable不要求底层数组的容量一定要为2的整数次幂,而HashMap则要求一定为2的整数次幂。
参考技术B ArrayList 采用的是数组形式来保存对象的,这种方式将对象放在连续的位置中,所以最大的缺点就是插入删除时非常麻烦LinkedList 采用的将对象存放在独立的空间中,而且在每个空间中还保存下一个链接的索引 但是缺点就是查找非常麻烦 要丛第一个索引开始
Hashtable和HashMap类有三个重要的不同之处。第一个不同主要是历史原因。Hashtable是基于陈旧的Dictionary类的,HashMap是Java 1.2引进的Map接口的一个实现。
也许最重要的不同是Hashtable的方法是同步的,而HashMap的方法不是。这就意味着,虽然你可以不用采取任何特殊的行为就可以在一个多线程的应用程序中用一个Hashtable,但你必须同样地为一个HashMap提供外同步。一个方便的方法就是利用Collections类的静态的synchronizedMap()方法,它创建一个线程安全的Map对象,并把它作为一个封装的对象来返回。这个对象的方法可以让你同步访问潜在的HashMap。这么做的结果就是当你不需要同步时,你不能切断Hashtable中的同步(比如在一个单线程的应用程序中),而且同步增加了很多处理费用。
第三点不同是,只有HashMap可以让你将空值作为一个表的条目的key或value。HashMap中只有一条记录可以是一个空的key,但任意数量的条目可以是空的value。这就是说,如果在表中没有发现搜索键,或者如果发现了搜索键,但它是一个空的值,那么get()将返回null。如果有必要,用containKey()方法来区别这两种情况。
一些资料建议,当需要同步时,用Hashtable,反之用HashMap。但是,因为在需要时,HashMap可以被同步,HashMap的功能比Hashtable的功能更多,而且它不是基于一个陈旧的类的,所以有人认为,在各种情况下,HashMap都优先于Hashtable。
关于Properties
有时侯,你可能想用一个hashtable来映射key的字符串到value的字符串。DOS、Windows和Unix中的环境字符串就有一些例子,如key的字符串PATH被映射到value的字符串C:\WINDOWS;C:\WINDOWS\SYSTEM。Hashtables是表示这些的一个简单的方法,但Java提供了另外一种方法。
Java.util.Properties类是Hashtable的一个子类,设计用于String keys和values。Properties对象的用法同Hashtable的用法相象,但是类增加了两个节省时间的方法,你应该知道。
Store()方法把一个Properties对象的内容以一种可读的形式保存到一个文件中。Load()方法正好相反,用来读取文件,并设定Properties对象来包含keys和values。
注意,因为Properties扩展了Hashtable,你可以用超类的put()方法来添加不是String对象的keys和values。这是不可取的。另外,如果你将store()用于一个不包含String对象的Properties对象,store()将失败。作为put()和get()的替代,你应该用setProperty()和getProperty(),它们用String参数。 参考技术C ArrayList 采用的是数组形式来保存对象的,这种方式将对象放在连续的位置中,所以最大的缺点就是插入删除时非常麻烦
LinkedList 采用的将对象存放在独立的空间中,而且在每个空间中还保存下一个链接的索引 但是缺点就是查找非常麻烦 要丛第一个索引开始
Hashtable和HashMap类有三个重要的不同之处。第一个不同主要是历史原因。Hashtable是基于陈旧的Dictionary类的,HashMap是Java 1.2引进的Map接口的一个实现。
也许最重要的不同是Hashtable的方法是同步的,而HashMap的方法不是。这就意味着,虽然你可以不用采取任何特殊的行为就可以在一个多线程的应用程序中用一个Hashtable,但你必须同样地为一个HashMap提供外同步。一个方便的方法就是利用Collections类的静态的synchronizedMap()方法,它创建一个线程安全的Map对象,并把它作为一个封装的对象来返回。这个对象的方法可以让你同步访问潜在的HashMap。这么做的结果就是当你不需要同步时,你不能切断Hashtable中的同步(比如在一个单线程的应用程序中),而且同步增加了很多处理费用。
第三点不同是,只有HashMap可以让你将空值作为一个表的条目的key或value。HashMap中只有一条记录可以是一个空的key,但任意数量的条目可以是空的value。这就是说,如果在表中没有发现搜索键,或者如果发现了搜索键,但它是一个空的值,那么get()将返回null。如果有必要,用containKey()方法来区别这两种情况。
一些资料建议,当需要同步时,用Hashtable,反之用HashMap。但是,因为在需要时,HashMap可以被同步,HashMap的功能比Hashtable的功能更多,而且它不是基于一个陈旧的类的,所以有人认为,在各种情况下,HashMap都优先于Hashtable。
关于Properties
有时侯,你可能想用一个hashtable来映射key的字符串到value的字符串。DOS、Windows和Unix中的环境字符串就有一些例子,如key的字符串PATH被映射到value的字符串C:\WINDOWS;C:\WINDOWS\SYSTEM。Hashtables是表示这些的一个简单的方法,但Java提供了另外一种方法。
Java.util.Properties类是Hashtable的一个子类,设计用于String keys和values。Properties对象的用法同Hashtable的用法相象,但是类增加了两个节省时间的方法,你应该知道。
Store()方法把一个Properties对象的内容以一种可读的形式保存到一个文件中。Load()方法正好相反,用来读取文件,并设定Properties对象来包含keys和values。
注意,因为Properties扩展了Hashtable,你可以用超类的put()方法来添加不是String对象的keys和values。这是不可取的。另外,如果你将store()用于一个不包含String对象的Properties对象,store()将失败。作为put()和get()的替代,你应该用setProperty()和getProperty(),它们用String参数。 参考技术D
ArrayList和LinkedList的区别
ArrayList是实现了基于动态数组的数据结构,LinkedList基于链表的数据结构。
对于随机访问get和set,ArrayList觉得优于LinkedList,因为LinkedList要移动指针。
对于新增和删除操作add和remove,LinedList比较占优势,因为ArrayList要移动数据。
HashMap和Hashtable的区别
HashMap几乎可以等价于Hashtable,除了HashMap是非synchronized的,并可以接受null(HashMap可以接受为null的键值(key)和值(value),而Hashtable则不行)。
HashMap是非synchronized,而Hashtable是synchronized,这意味着Hashtable是线程安全的,多个线程可以共享一个Hashtable;而如果没有正确的同步的话,多个线程是不能共享HashMap的。Java 5提供了ConcurrentHashMap,它是HashTable的替代,比HashTable的扩展性更好。
另一个区别是HashMap的迭代器(Iterator)是fail-fast迭代器,而Hashtable的enumerator迭代器不是fail-fast的。所以当有其它线程改变了HashMap的结构(增加或者移除元素),将会抛出ConcurrentModificationException,但迭代器本身的remove()方法移除元素则不会抛出ConcurrentModificationException异常。但这并不是一个一定发生的行为,要看JVM。这条同样也是Enumeration和Iterator的区别。
由于Hashtable是线程安全的也是synchronized,所以在单线程环境下它比HashMap要慢。如果你不需要同步,只需要单一线程,那么使用HashMap性能要好过Hashtable。
HashMap不能保证随着时间的推移Map中的元素次序是不变的。
Java中ArrayList和LinkedList区别
ArrayList和LinkedList的大致区别如下:
1.ArrayList是实现了基于动态数组的数据结构,LinkedList基于链表的数据结构。
2.对于随机访问get和set,ArrayList觉得优于LinkedList,因为LinkedList要移动指针。
3.对于新增和删除操作add和remove,LinedList比较占优势,因为ArrayList要移动数据。
上代码:
1 static final int N=50000; 2 static long timeList(List list){ 3 long start=System.currentTimeMillis(); 4 Object o = new Object(); 5 for(int i=0;i<N;i++) { 6 list.add(0, o); 7 } 8 return System.currentTimeMillis()-start; 9 } 10 static long readList(List list){ 11 long start=System.currentTimeMillis(); 12 for(int i=0,j=list.size();i<j;i++){ 13 14 } 15 return System.currentTimeMillis()-start; 16 } 17 18 static List addList(List list){ 19 Object o = new Object(); 20 for(int i=0;i<N;i++) { 21 list.add(0, o); 22 } 23 return list; 24 } 25 public static void main(String[] args) { 26 System.out.println("ArrayList添加"+N+"条耗时:"+timeList(new ArrayList())); 27 System.out.println("LinkedList添加"+N+"条耗时:"+timeList(new LinkedList())); 28 29 List list1=addList(new ArrayList<>()); 30 List list2=addList(new LinkedList<>()); 31 System.out.println("ArrayList查找"+N+"条耗时:"+readList(list1)); 32 System.out.println("LinkedList查找"+N+"条耗时:"+timeList(list2)); 33 }
当我们在集合中装5万条数据,测试运行结果如下:
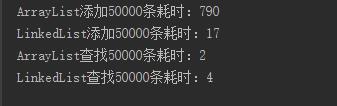
显然我们可以看出ArrayList更适合读取数据,linkedList更多的时候添加或删除数据。
ArrayList内部是使用可増长数组实现的,所以是用get和set方法是花费常数时间的,但是如果插入元素和删除元素,除非插入和删除的位置都在表末尾,否则代码开销会很大,因为里面需要数组的移动。
LinkedList是使用双链表实现的,所以get会非常消耗资源,除非位置离头部很近。但是插入和删除元素花费常数时间。
以上是关于ArrayList和LinkedList的区别的主要内容,如果未能解决你的问题,请参考以下文章