分层强化学习:基于选项(option)的强化学习/论文笔记 The Option-Critic Architecture 2017 AAAI
Posted UQI-LIUWJ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分层强化学习:基于选项(option)的强化学习/论文笔记 The Option-Critic Architecture 2017 AAAI相关的知识,希望对你有一定的参考价值。
The Option-Critic Architecture 2017 AAAI
1 option
option 可以看作是一种对动作的抽象。
一般来说,option可以表示为一个三元组
,其中:
是这个option的策略(决定option内部的action)【inner-option policy】
表示终止条件,β(s)表示状态s有β(s)的概率终止并退出此option【退出后由上层策略重新选择新的option】
表示option的初始状态集合
option
当option开始执行时,agent 通过该option的 π 进行动作选择直到终止。
值得注意的是,一个单独的动作a也可以是一个option,通常被称作 one-step option,其中:
- 对任意的状态s,都有β(s)=1
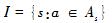
1.1 option和action的关系和区别
option是时序扩展的action,或把option看成是对action的一种时序抽象。
左图是一个格子世界,共有四个房间,每个房间之间通过一个过道连接,假设智能体当前处于左上方的房间内,其目标是到达G1处。
那么从宏观的层面看, 它有两种选择,分别是先进入右上方房间和先进入左下方房间,这两种宏观的选择就是所谓的option;
其次,当选择了某一种方案(option) 后,例如选择了先进入右上方房间,那么如何从当前的格子位置抵达当前房间与右上方房间相连的过道格子,在这个过程中所需采取的每一步 动作即是action,例如我们可以通过一些路径规划方法找到像右图一样的某种最短路径走法。
【option框架下的策略层次就是首先由顶层策略选择option,再由option选择action。】

个人觉得,这样的一个好处是减少状态空间:比如在顶层,我的状态空间是4维(处在哪个房间中);在底层,我的状态空间是25+2=27维(处在哪个格子中)。而如果不用分层的强化学习,那么状态空间是25*4+4=104维
整体的框架可以看成两个层次组成:
-
底层是一个选择action的次级策略(在这篇paper中,各个option共享相同的action策略):
-
进行环境观测
-
输出动作
-
运行到终止
-
-
顶层是用于选择 option 的高级策略(policy-over-option):
-
进行环境观测
-
输出子策略
-
运行到终止
-
2 半马尔可夫决策过程 semi-markov decision process SMDP
马尔可夫决策过程中,选择一个动作后,agent会立刻根据状态转移方程P跳转到下一个状态,而 在半马尔可夫决策过程中,当前状态到下一个状态的步数是一个随机变量 τ, 即在某个状态s下选择一个动作a后,经过 τ 步才会以一个概率转移到下一个状态s′(多次和环境发生交互之后,状态才会改变【这一系列action我们可以看成一个option】【换言之,决策点之间的时间间隔是不同的】)。
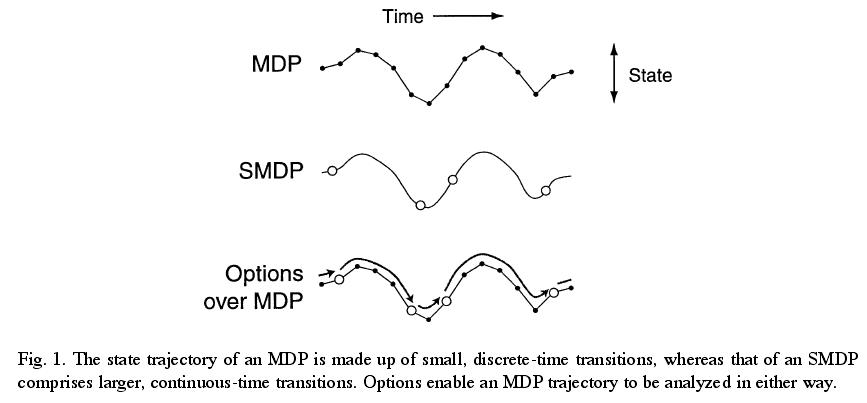
此时的状态转移概率是s和τ的联合概率
。根据 τ 的定义域不同,SMDP所定义的系统也有所不同。
- 当 τ 的取值为实数值,则SMDP构建了一个连续时间 - 离散事件系统
- 当 τ 的取值为正整数,则是一个离散时间SMDP
出于简单考虑,绝大部分分层强化学习都是在离散时间 SMDP上进行讨论。
基于option的分层方法兼具MDP和SMDP的特性。
- 相比于一般的MDP,option观点在action之上抽象出了一个option决策层,使整个过程具有像SMDP一样的离散事件特性;
- 同时相比于SMDP,option方法也关注每个option内部的过程变化,option内部的变化过程也具有马 尔可夫性。
3 基于option的Bellman 方程
3.1 value function
3.1.1 option-value function
是在某个状态下选择某个option所能产生的总收益
- Ω,θ,U分别是不同的参数集
- s是某一个状态
- ω是某一个option
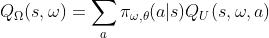
如果我们把(s,ω)看作是一个增广状态空间的话,option-value function 其实就是MDP中的value function
令s'=(s,ω)
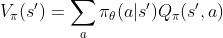
3.1.2 action-value function
描述的是在某状态,选择了某个option的前提下,采取某个action所能产生的总收益
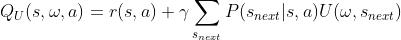
注:U也取决于θ(也是一个关于θ的函数)
同样地,如果我们把(s,ω)看作是一个增广状态空间的话,option-value function 其实就是MDP中的value function
令s'=(s,ω)
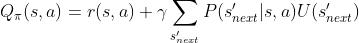
3.1.3 option-value function upone arrival in the state
这里是和MDP的区别所在。
由于有中断函数β的存在,到达下一状态之后,我们要考虑是否跳出当前option。因而下一个状态的值函数需要综合考虑中断了当前option的情况和继续当前option 的情况
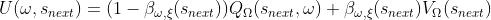
- Ω,
 分别是不同的参数集(
分别是不同的参数集(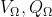 都会受到的影响)
都会受到的影响) - 如果继续执行当前option,即不中断,那么下一状态的价值自然由 option-value function描述
- 如果中断了当前option,此时新的option还没有选择出来
- 那么新状态下的价值就只能由更高层次的策略函数下新状态的value function描述,用以描述选择不同option的期望价值
3.2 转移方程
3.2.1 单步转移方程
论文里面是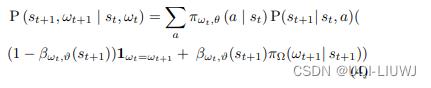
这里我把它展开,可能更好理解一些
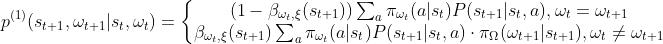
分别表示如果不退出option和退出option之后,概率分别是多少
注:在论文正文中给出的公式里面是
,但是在附录的证明里面是
【不太确定哪个是对的】
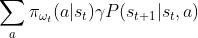

3.2.2 多步转移方程
得到一步转移概率后可以归纳出多步转移概率。
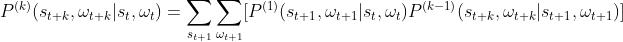
4 option内部策略梯度
4.1 policy gradient回顾

强化学习笔记:policy learning_UQI-LIUWJ的博客-CSDN博客
论文中的展现形式是(表达的意思是一样的)
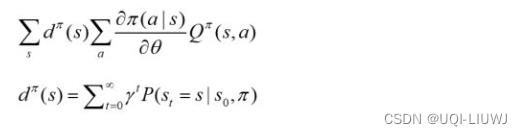
4.2 Intra-Option Policy Gradient Theorem
类比于梯度策略,我们这样理解:
令目标函数为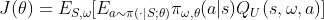
然后计算其策略梯度,论文中的展现形式是: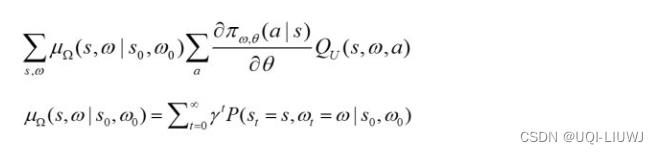
用类似强化学习笔记:policy learning_UQI-LIUWJ的博客-CSDN博客 的推理,我们可以得到
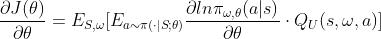
用它来进行梯度上升,更新参数
5 终止梯度策略
我们计算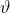 的梯度(我前面用了表示的内容)
的梯度(我前面用了表示的内容)
这里是梯度下降,梯度为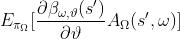
6 整体流程
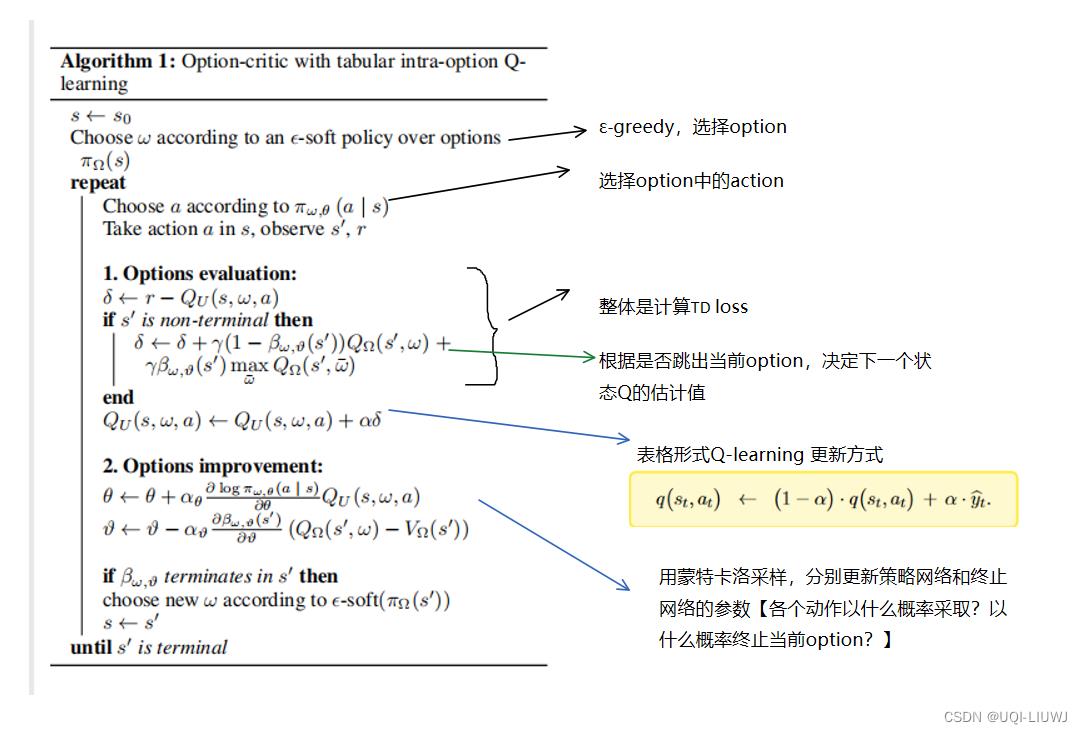
以上是关于分层强化学习:基于选项(option)的强化学习/论文笔记 The Option-Critic Architecture 2017 AAAI的主要内容,如果未能解决你的问题,请参考以下文章