9.1强化学习全貌
Posted 炫云云
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了9.1强化学习全貌相关的知识,希望对你有一定的参考价值。
文章目录
1、任务描述
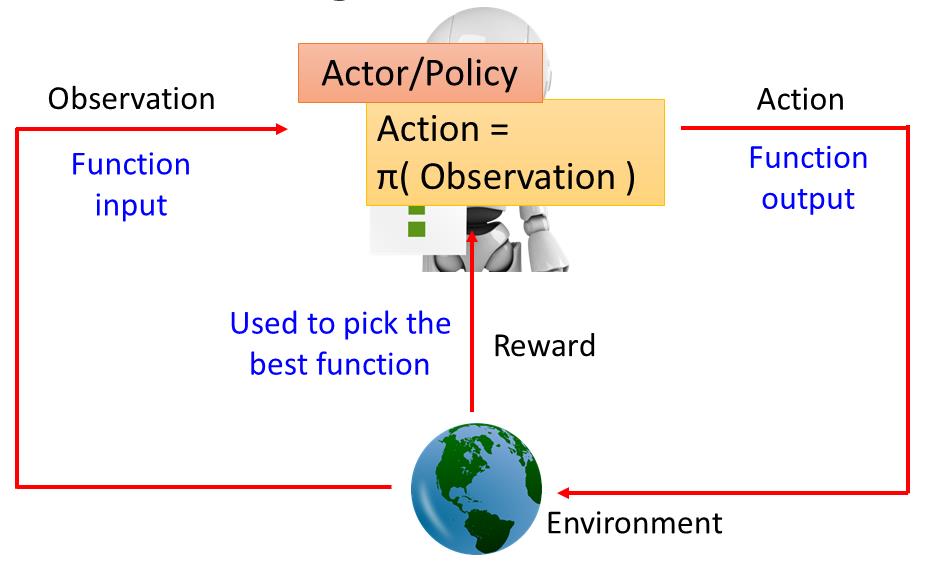
在强化学习里面会有一个Agent跟一个Environment。这个Agent会有Observation(观察)看到世界种种变化,根据观察的State调整自己,这个State指的是环境的状态,也就是你的机器所看到的东西。Agent的state能够观察到一部分的情况,机器没有办法看到环境所有的状态,所以才会有这个观察部分状态这个想法。machine会做一些事情,它做的事情叫做Action,Action会影响环境,会跟环境产生一些互动。因为它对环境造成的一些影响,它会得到Reward,这个Reward告诉它,它的Action是好的还是不好的。如下图
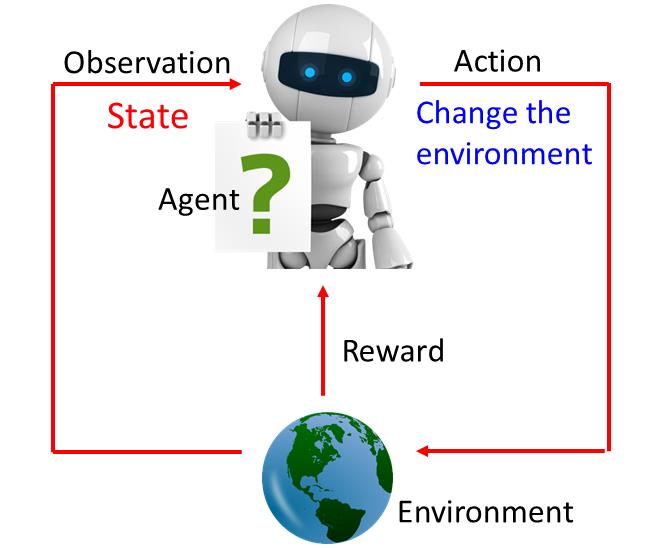
举个例子,比如机器看到一杯水,然后它就take一个action,这个action把水打翻了,Environment就会得到一个negative的reward,告诉它不要这样做,它就得到一个负向的reward。在强化学习这些动作都是连续的,因为水被打翻了,接下来它看到的就是水被打翻的状态,它会take另外一个action,决定把它擦干净,Environment觉得它做得很对,就给它一个正向的reward。机器生来的目标就是要去学习采取那些ation,可以让maximize reward。
接着,以alpha go为例子,一开始machine的Observation是棋盘,棋盘可以用一个19*19的矩阵来描述,接下来,它要take一个action,这个action就是落子的位置。落子在不同的位置就会引起对手的不同反应,对手下一个子,Agent的Observation就变了。Agent看到另外一个Observation后,就要决定它的action,再take一个action,落子在另外一个位置。用机器下围棋就是这么个回事。在围棋这个情况里面,还是一个蛮难的强化学习,在多数的时候,你得到的reward都是0,落子下去通常什么事情也没发生这样子。只有在你赢了,得到reward是1,如果输了,得到reward是-1。强化学习困难的地方就是有时候你的reward是稀疏的,只有倒数几步才有reward。即在只有少数的action 有reward的情况下去挖掘正确的action。
对于machine来说,它要怎么学习下围棋呢,就是找一某个对手一直下下,有时候输有时候赢,它就是调整Observation和action之间的关系,调整model让它得到的reward可以被maximize。
监督 v.s. 强化
我们可以比较下下围棋采用监督和强化有什么区别。如果是监督你就是告诉机器说看到什么样的态势就落在指定的位置。监督不足的地方就是具体态势下落在哪个地方是最好的,其实人也不知道,因此不太容易做监督。用监督就是机器从老师那学,老师说下哪就下哪。
如果是强化呢,就是让机器找一个对手不断下下,赢了就获得正的reward,没有人告诉它之前哪几步下法是好的,它要自己去试,去学习。强化是从过去的经验去学习,没有老师告诉它什么是好的,什么是不好的,machine要自己想办法,其实在做强化这个task里面,machine需要大量的training,可以两个machine互相下。alpha Go 是先做监督学习,做得不错再继续做强化学习。
学习一个chat-bot
强化学习也可以被用在学习一个 chat-bot。chat-bot 是seq2seq,input 就是一句话,output 就是机器的回答。
如果采用Supervised ,就是告诉机器有人跟你说“hello”,你就回答“hi”。如果有人跟你说“bye bye”,你就要说“good bye”。
如果是强化学习就是让机器胡乱去跟人讲话,讲讲,人就生气了,machine就知道一句话可能讲得不太好。不过没人告诉它哪一句话讲得不好,它要自己去发掘这件事情。
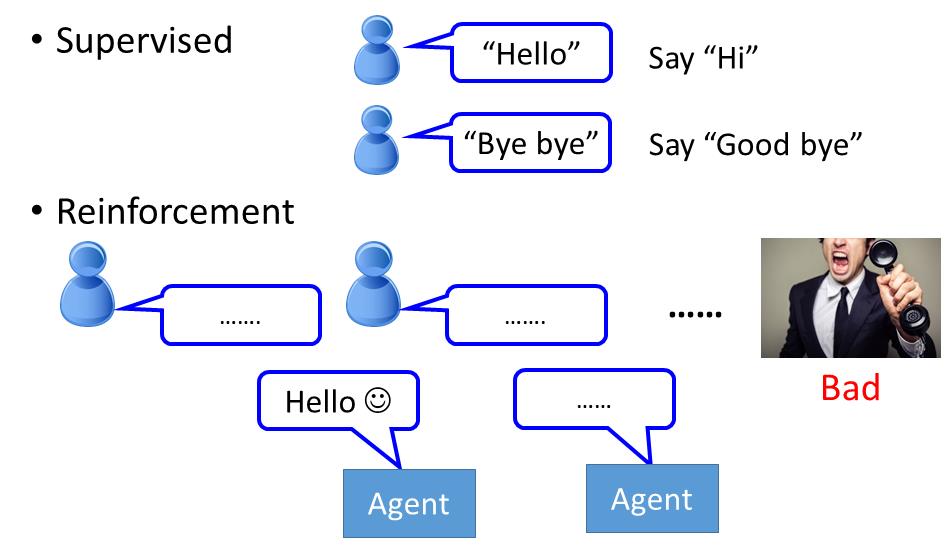
这个想法听起来很疯狂,但是真正有chat-bot是这样做的,这个怎么做呢?因为你要让machine不断跟人讲话,看到人生气后进行调整,去学怎么跟人对话,这个过程比较漫长,可能得好几百万人对话之后才能学会。这个不太现实,那么怎么办呢,就用Alpha Go的方式,Learning 两个agent,然后让它们互讲的方式。

两个chat-bot互相对话,对话之后有人要告诉它们它们讲得好还是不好。在围棋里比较简单,输赢是比较明确的,对话的话就比较麻烦,你可以让两个machine进行无数轮互相对话,问题是你不知道它们这聊天聊得好还是不好,这是一个待解决问题。现有的方式是制定几条规则,如果讲得好就给它positive reward ,讲得不好就给它negative reward,好不好由人主观决定,然后machine就从它的reward中去学说它要怎么讲才是好。后续可能会有人用GAN的方式去学chat-bot。通过discriminator判断是否像人对话,两个agent就会想骗过discriminator,即用discriminator自动认出给reward的方式。
强化学习有很多应用,尤其是人也不知道怎么做的场景非常适合。
交互搜索
让machine学会做交互式检索,意思就是说有一个搜寻系统,能够跟用户进行信息确认的方式,从而搜寻到user所需要的信息。直接返回user所需信息,它会得到一个positive reward,然后每问一个问题,都会得到一个negative reward。
强化学习的难点
那么强化学习的难点在哪里呢?它有两个难点
-
奖励延迟
第一个难点是,reward出现往往会存在延迟,比如在
太空入侵者里面只有开火才会得到reward,但是如果machine只知道开火以后就会得到reward,最后learn出来的结果就是它只会乱开火。对它来说,往左往右移没有任何reward。事实上,往左往右这些action,它对开火是否能够得到reward是有关键影响的。虽然这些往左往右的action,本身没有办法让你得到任何reward,但它帮助你在未来得到reward,就像规划未来一样,machine需要有这种远见,要有这种visual,才能把电玩玩好。在下围棋里面,有时候也是一样的,短期的牺牲可以换来最好的结果。 -
Agent’s actions 影响它后续接收到的数据
Agent采取行动后会影响之后它所看到的东西,所以Agent要学会去探索这个世界。比如说在这个
太空入侵者里面,Agent只知道往左往右移,它不知道开火会得到reward,也不会试着击杀最上面的外星人,就不会知道击杀这个东西可以得到很高的reward,所以要让machine去探索它没有做过的行为,这个行为可能会有好的结果也会有坏的结果。但是探索没有做过的行为在强化学习里面也是一种重要的行为。
2、 强化学刁的基础础知识
强仪学习与监督学刁的区别:
- 训练数据中没有标签,只有奖励函数(Reward Function) 。
- 训练数据不是现成给定,而是由行为(Action )获得。
- 现在的行为(Action)不仅影响后续训练数据的获得,也影响奖励函数(Reward Function )的取值。
- 训练的目的是构建一个“状态->行为”的函数。

概念的定义

我们假设状态数有限,行为数有限。
强化学习中,我们经常用以下3个假设:

强化学习的过程:


3、强化学习的方法
强化学习的方法分成两大块,一个是基于策略的方法,另一个是基于估值方法的方法。先有基于估值方法的方法,再有基于策略的方法。在基于策略的方法里面,会learn一个负责做事的Actor,在基于估值方法的方法会learn一个不做事的Critic,专门批评不做事的人。我们要把Actor和Critic加起来叫做Actor+Critic的方法。
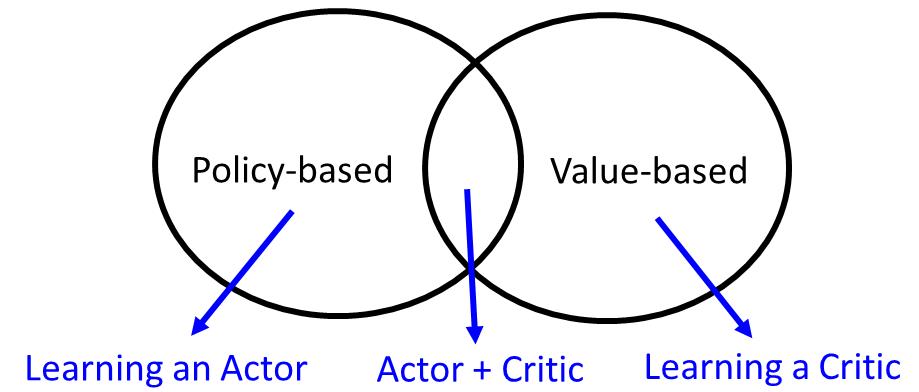
现在最强的方法就是Asynchronous Advantage Actor-Critic(A3C)。Alpha Go是各种方法大杂烩,有Policy-based的方法,有Valued-based的方法,有model-based的方法。
3.1基于策略 方法
先来看看怎么学一个Actor,所谓的Actor是什么呢?我们之前讲过,机器学习就是找一个函数,强化学习也是机器学习的一种,所以要做的事情也是找函数。这个函数就是实现某个功能,Actor就是一个函数。这个函数的input就是机器看到的observation,它的output就是机器要采取的Action。我们要透过reward来帮我们找这个最好的函数。
- 函数
找个这个函数有三个步骤:

-
- 神经网络作为Actor
第一个步骤就是决定你的函数长什么样子,假设你的函数是一个神经网络,就是一个deep learning。
如果神经网络作为一个Actor,这个神经网络的输入就是observation,可以通过一个vector或者一个matrix 来描述。output就是你现在可以采取的action。举个例子,神经网络作为一个Actor,inpiut是一张image,output就是你现在有几个可以采取的action,output就有几个维度。假设我们在玩
太空入侵者,output就是可能采取的action左移、右移和开火,这样output就有三个维度分别代表了左移、右移和开火。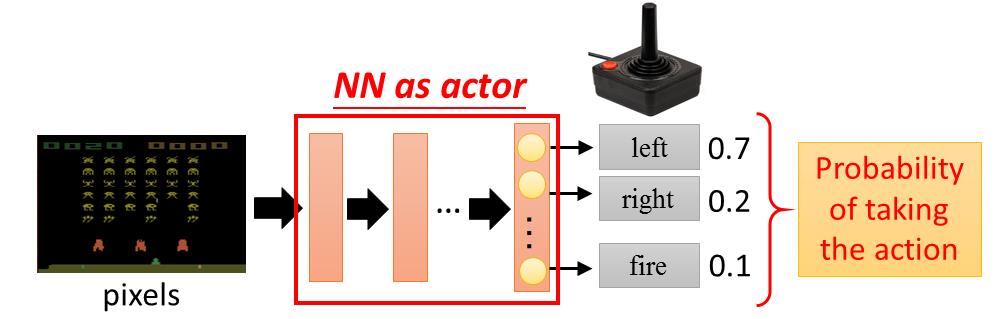
这个神经网络怎么决定这个Actor要采取哪个action呢?通常的做法是这样,你把这个image丢到神经网络里面去,它就会告诉你说每个output 维度所对应的分数,可以采取分数最高的action,比如说left。用这个神经网络来做Actor有什么好处,神经网络是可以举一反三的,可能有些画面model从来没有看过,但是神经网络的特性,你给它一个image,神经网络吐出一个output。所以就算是它没看过的东西,它output可以得到一个合理的结果。神经网络就是比较大概。
-
- 学习优的Actor
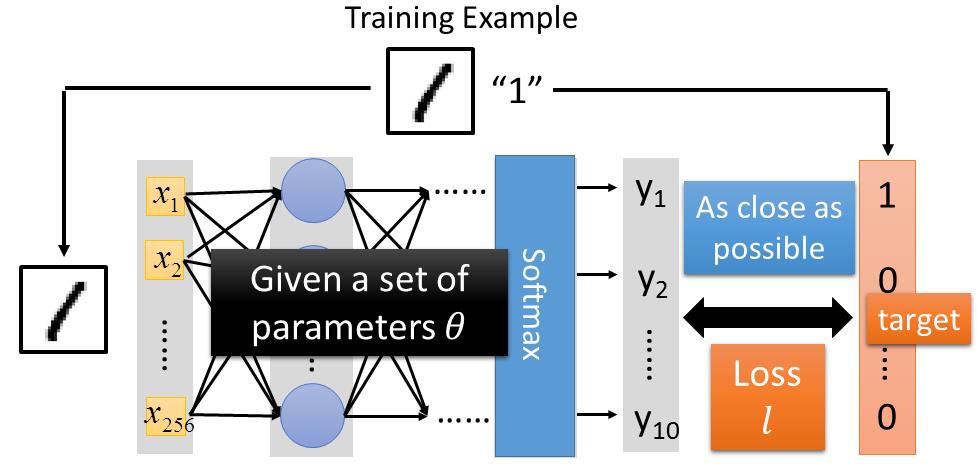
第二步骤就是,我们要决定一个Actor的好坏。在监督学习中,我们是怎样决定一个函数的好坏呢?举个数字识别例子来说,我们把图片扔进神经网络,看它的结果和target是否像,如果越像的话这个函数就会越好,我们会一个loss,然后计算每个图片的loss,我们要找一个参数去minimize这个参数。
在强化学习里面,一个Actor的好坏的定义是非常类似的。假设我们现在有一个Actor,这个Actor就是一个神经网络,神经网络的参数是 θ \\mathbf{\\theta} θ,即一个Actor可以表示为 π θ ( s ) \\pi_\\theta(s) πθ(s),它的input就是机器看到的observation。
那怎么知道一个Actor表现得好还是不好呢?我们让这个Actor实际的去玩一个游戏,玩完游戏得到的全部奖励为 R θ = ∑ t = 1 T r t R_\\theta=\\sum_{t=1}^Tr_t Rθ=∑t=1Trt,把每个时间step得到的奖励合起来,这是一段经历里面,你得到的全部奖励。这个全部奖励才是我们需要去maximize的对象。我们不需要去maximize 每个step的奖励,我们是要maximize 整个游戏玩完之后的全部奖励。假设我们拿同一个Actor,每次玩的时候, R θ R_\\theta Rθ其实都会不一样的。因为两个原因,首先你Actor本身如果是基于策略,看到同样的场景它也会采取不同的Action。所以就算是同一个Actor,同一组参数,每次玩的时候你得到的 R θ R_\\theta Rθ也会不一样的。再来游戏本身也有随机性,就算你采取同一个Action,你看到的observation每次也可能都不一样。所以 R θ R_\\theta Rθ是一个随机变量。我们做的事情,不是去maximize每次玩游戏时的 R θ R_\\theta Rθ,而是去maximize R θ R_\\theta Rθ的期望值。这个期望值就衡量了某一个Actor的好坏,好的Actor期望值就应该要比较大。
那么怎么计算呢,我们假设一场游戏就是一系列的决策机制 τ \\tau τ
τ = { s 1 , a 1 , r 1 , s 2 , a 2 , r 2 , . . . , s T , a T , r T } \\tau = \\left\\{ s_1,a_1,r_1, s_2,a_2,r_2,...,s_T,a_T,r_T \\right\\} τ={s1,a1,r1,s2,a2,r2,...,sT,aT,rT}
τ \\tau τ 包含了state,Actor的Action,得到的Reward,是一个序列。
R ( τ ) = ∑ n = 1 N r n R(\\tau) = \\sum_{n=1}^Nr_n R(τ)=n=1∑Nrn
R ( τ ) R(\\tau) R(τ)代表在这一段经历里面,最后得到的总reward。当我们用某一个Actor去玩这个游戏的时候,每个 τ \\tau τ都会有出现的几率, τ \\tau τ代表从游戏开始到结束过程,这个过程有千百万种,当你选择这个Actor的时候,你可能只会看到某一些过程,某些过程特别容易出现,某些过程比较不容易出现。每个游戏出现的过程,可以用一个几率 P ( τ ∣ θ ) P(\\tau|\\theta) P(τ∣θ)来表示它,就是说参数是 θ \\theta θ时 τ \\tau τ这个过程出现的几率。那么 R θ R_\\theta Rθ的期望值为
R ˉ θ = ∑ τ R ( τ ) P ( τ ∣ θ ) \\bar{R}_\\theta=\\sum_\\tau R(\\tau)P(\\tau|\\theta) Rˉθ=τ∑R(τ)P(τ∣θ)
实际上要穷举所有的 τ \\tau τ是不可能的,那么要怎么做?让Actor去玩N场这个游戏,获得N个过程 τ 1 , τ 2 , . . . , τ N {\\tau^1,\\tau^2,...,\\tau^N} τ1,τ2,...,τN ,玩N场就好像从 P ( τ ∣ θ ) P(\\tau|\\theta) P(τ∣θ)去采样 N N N个 τ \\tau τ。假设某个 τ \\tau τ它的几率特别大,就特别容易被采样出来。采样出来的 τ \\tau τ跟几率成正比。让Actor去玩 N N N场,相当于从 P ( τ ∣ θ ) P(\\tau|\\theta) P(τ∣θ)概率场抽取N个过程,可以通过 N N N个Reward的均值进行近似,如下表达
R ˉ θ = ∑ τ R ( τ ) P ( τ ∣ θ ) ≈ 1 N R ( τ n ) \\bar{R}_\\theta=\\sum_\\tau R(\\tau)P(\\tau|\\theta) \\approx \\frac{1}{N}R(\\tau^n) Rˉθ=τ∑R(τ)P(τ∣θ)≈N1R(τn) -
选择最佳函数
怎么选择最好的函数,其实就是用我们的梯度上升。我们已经找到目标了,就是最大化这个 R ˉ θ \\bar{R}_\\theta Rˉθ
θ ∗ = a r g max θ R ˉ θ \\theta^\\ast = arg \\max_\\theta \\bar{R}_\\theta θ∗=argθmax以上是关于9.1强化学习全貌的主要内容,如果未能解决你的问题,请参考以下文章