日常PySpark包DataFrame相关处理小结
Posted 囚生CY
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了日常PySpark包DataFrame相关处理小结相关的知识,希望对你有一定的参考价值。
序言
PySpark在DataFrame上的处理方式与Pandas的处理方法大致是类似的,笔者认为初学PySpark可以直接从用户文档中的pyspark.sql模块下的各个模块与方法开始看,一方面这块与Pandas的函数用法有很多相同的地方,另一方面这块有很多例子可以参考,相比于其他模块要形象得多,也可以辅助理解其他模块的用法。
如下图所示,pyspark.sql下的主要内容在Module Context与pyspark.sql.functions模块中,前者主要是如何创建数据表以及数据表相关操作,后者则是一些主要应用于数据列的函数(其实这部分只要搞清楚udf和pandas_udf就不用管其他的了,其他一大堆函数都是可以简单复现的,虽然在效率上可能不如内置的函数)👇
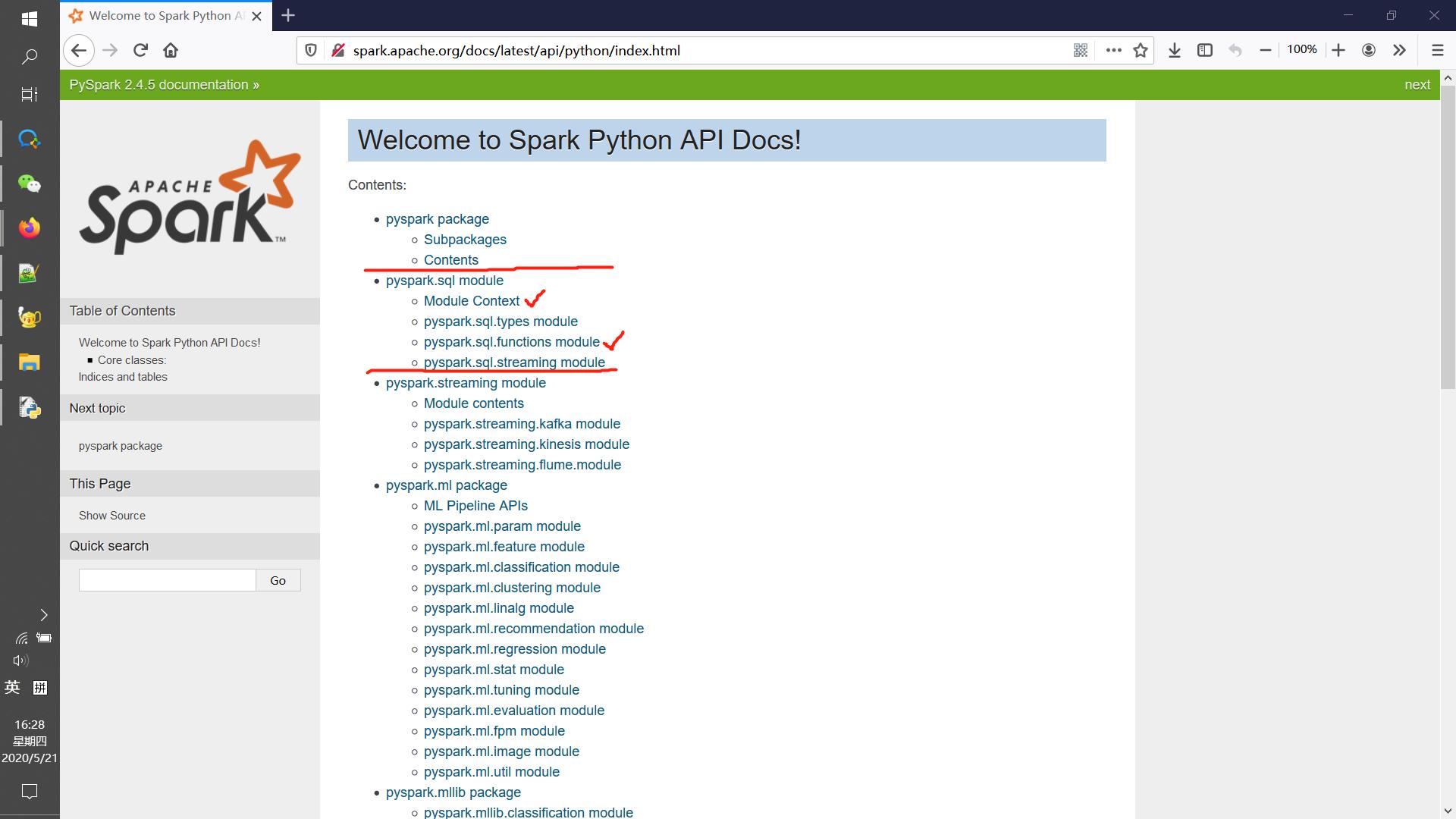
这几天窝在宿舍里把pyspark.sql模块的用户文档过了一遍,感觉是Python的既然已经有Pandas,为什么还要吃力不讨好的学个语法相近但是复杂不少的PySpark,大不了用Pandas做好再转成PySpark的数据格式不也完事了。目前笔者的认知是就pyspark.sql而言基本上与Pandas的功能相近,但是PySpark数据存储与处理上使用了分布式存储与并行式运算,相对于Pandas在数据处理效率与数据处理规模上是更加卓越的;此外PySpark可以处理更多类型的源数据文件(如Parquet格式的文件),更有利于与数据库对接,相对于Pandas的“小打小闹”肯定是现在有较大数据管理需求的企业更为青睐的方法。
笔者因为在看用户文档的过程中记录的点比较杂乱,在Notepad跟Notebook里都记了一些,为了方便记忆,本文将主要基于pyspark.sql模块中对DataFrame的处理,依据与Pandas中数据处理的区别为线索展开,提供一些常见报错的解决方案,大致做一个入门性质的整理工作。
DataFrame创建及常规处理方法
使用PySpark做数据处理前,总是需要设置两个作为入口性质数据处理器对象:spark与sqlContext 👇
from pyspark import SparkContext
from pyspark.sql import SparkSession, SQLContext
sc = SparkContext("local","$mytest")
spark = SparkSession.builder.master("local").appName("$mytest").getOrCreate()
sqlContext = SQLContext(sc)注意上面的变量spark与sc的创建顺序不可颠倒,否则会报错,原因是规定不允许通识运行两个SparkContext对象,在变量spark的创建使用的是getOrCreate方法,如果先创建变量spark就即默认Create,过程会创建SparkContext对象,再创建变量sc就会报错。反过来则后创建变量spark就即默认Get,即使用sc作为全局变量的配置,就不会报错了。
事实上如果同时创建两个sc变量,也会发生同样的错误,除非在两行之间插入sc1.stop()的语句来消除👇
sc1 = SparkContext("local","$mytest1")
sc2 = SparkContext("local","$mytest2")
# ValueError: Cannot run multiple SparkContexts at once; existing SparkContext(app=$mytest1, master=local)
以下为利用spark与sqlContext 生成DataFrame的一些例子,可能相对来说Example 6使用Pandas作为中介是相对容易的👇
# CreateDataFrame方法示例
# Example 1 从tuple列表中生成DataFrame
print("========= Example 1 ==========")
l = [('Alice', 1)]
print(spark.createDataFrame(l).collect())
print(spark.createDataFrame(l,['name','age']).collect())
# Example 2 从dict列表中生成DataFrame(最熟悉的)
print("========= Example 2 ==========")
d = ['name': 'Alice', 'age': 1]
print(spark.createDataFrame(d).collect())
# Example 3 从rdd生成DataFrame
print("========= Example 3 ==========")
rdd = sc.parallelize(l) # 利用包含多个tuple列表
print(spark.createDataFrame(rdd).collect())
df = spark.createDataFrame(rdd,['name', 'age'])
print(df.collect())
# Example 4 利用Row对象确定字段名
print("========= Example 4 ==========")
from pyspark.sql import Row
Person = Row('name', 'age')
person = rdd.map(lambda r: Person(*r))
df2 = sqlContext.createDataFrame(person)
print(df2.collect())
# Example 5 结构体/SQL字典式生成dataFrame
print("========= Example 5 ==========")
from pyspark.sql.types import *
schema = StructType([
StructField("name", StringType(), True),
StructField("age", IntegerType(), True)])
df3 = sqlContext.createDataFrame(rdd, schema)
print(df3.collect())
# Example 6 利用pandas的结果导入
print("========= Example 6 ==========")
print(sqlContext.createDataFrame(df.toPandas()).collect())
print(sqlContext.createDataFrame(pandas.DataFrame([[1, 2]])).collect())
# Example 7
print("========= Example 7 ==========")
print(sqlContext.createDataFrame(rdd, "a: string, b: int").collect()) # 确定
rdd = rdd.map(lambda row: row[1])
print(sqlContext.createDataFrame(rdd, "int").collect()) # 取int的结果输出
#print(sqlContext.createDataFrame(rdd, "boolean").collect()) # 会报错: 因为没有布尔型的结果
输出结果如下所示👇
========= Example 1 ==========
[Row(_1='Alice', _2=1)]
[Row(name='Alice', age=1)]
========= Example 2 ==========
E:\\Python\\lib\\site-packages\\pyspark-2.4.5-py3.6.egg\\pyspark\\sql\\session.py:346: UserWarning: inferring schema from dict is deprecated,please use pyspark.sql.Row instead
warnings.warn("inferring schema from dict is deprecated,"
[Row(age=1, name='Alice')]
========= Example 3 ==========
[Row(_1='Alice', _2=1)]
[Row(name='Alice', age=1)]
========= Example 4 ==========
[Row(name='Alice', age=1)]
========= Example 5 ==========
[Row(name='Alice', age=1)]
========= Example 6 ==========
[Row(name='Alice', age=1)]
[Row(0=1, 1=2)]
========= Example 7 ==========
[Row(a='Alice', b=1)]
[Row(value=1)]特别地,PySpark与Pandas在DataFrame数据格式上的转换如下所示,如果觉得PySpark麻烦,那就在Pandas中处理好再转过来就是了,虽然有点蠢[汗]👇
df_pandas = df_spark.toPandas()
df_spark = sqlContext.createDataFrame(df_pandas)得到了用于数据处理的表,以下将DataFrame中的常见方法做一个汇总👇
1. dataframe常规操作
- people = spark.read.parquet("...") # 读入一张表
- ageCol = people.age # 取列
- 经典的多表查询
+ people = spark.read.parquet("...")
+ department = spark.read.parquet("...")
+ people.filter(people.age > 30).\\
join(department, people.deptId == department.id).\\ # 表的连接
groupBy(department.name, "gender").\\ # group方法
agg("salary": "avg", "age": "max") # agg方法
- 求mean max min 等
+ df.agg("age": "max").collect() # [Row(max(age)=5)]
+ from pyspark.sql import functions as F
df.agg(F.min(df.age)).collect() # [Row(min(age)=2)]
- alias(alias)方法: 表重命名(表内连接)
+ from pyspark.sql.functions import *
+ df_as1 = df.alias("df_as1")
+ df_as2 = df.alias("df_as2")
+ joined_df = df_as1.join(df_as2, col("df_as1.name") == col("df_as2.name"), 'inner') # 表的连接(内连接)
+ joined_df.select("df_as1.name", "df_as2.name", "df_as2.age").collect()
- df.collect()方法是返回df中每个ROW的列表
- df.columns属性 同df.columns
- df.count() 行数
- df.corr(列名1,列名2,method="pearson") 计算相关系数
- df.cov(列名1,列名2) 计算协方差
- df.createGlobalTempView("people") # 创建全局视图people
- df.createOrReplaceGlobalTempView("people") # 创建/修正视图
- df.createTempView(name)[source] # 创建临时视图
- df.createOrReplaceTempView("people") # 同上
- df.filter(df.id=="3") 筛选 完全可以写成df[df.id==3]
- df.join()
- df.select(*cols) # 筛选出多列
- df.crossJoin(df2) # 全连接(一般用不到)
- df.describe(*cols)
- df.distinct.count() 不重复计数
- df.drop("age")或df.drop(df.age) 删除一列
- df.dropDuplicates()或df.dropDuplicates(["col1","col2"])
- df.drop_duplicates 同上
- df.dropna(how='any', thresh=None, subset=None)[source]
- df.dtypes 类型
- df.exceptAll(df1) 保留在df中但不在df2中的字段(保留重复)
- df.explain(extended=False)
- df.fillna(value,subset=None)
+ df4.na.fill('age': 50, 'name': 'unknown').show()
- df.first()第一行
- df.foreach(f) 同df.rdd.foreach() 将f应用到每一行(如f=lambda x: x.name)
- df.foreachPartition(f) # def f(people): for p in people: print(person.name)
- df.freqItems(["col1","col2"]) 频繁项集
- df.groupBy(*cols) # 这个结果跟pandas的用法有点区别, 可以看下面GroupedData类的情况
- df.groupby(*cols)
- df.head(10)
- df.intersect(df1) # 去df与df2的交集 SQL的INTERSECT
- df.intersectAll(other) # 同上保留重复
- df.limit(1) 类似head
- df.orderBy(*cols,**kwargs)
+ df.sort(df.age.desc())
+ df.sort("age", ascending=False)
+ df.orderBy(df.age.desc())
+ df.sort(asc("age"))
+ df.orderBy(desc("age"), "name")
+ df.orderBy(["age", "name"], ascending=[0, 1]) # 常用类似pandas
- df.rdd 转为pyspark.RDD of Row
- df.registerTempTable(name) 同上view
- df.replace(to_replace,value=<no value>,subset=None)
- df.rollup(*cols)
- df = spark.range(10)
df.sample(withReplacement=True, fraction=0.5, seed=3)
- df.sampleBy("key", fractions=0: 0.1, 1: 0.2, seed=0)
- df.schema
- df.selectExpr(*expr)
+ df.selectExpr("age * 2", "abs(age)")
- df.show(n=20,truncate=True,vertical=False)
- df.sort() 参数用法同orderBy
- df.subtract(df1) df - df1 集合减法
- df.union(df1) / df.unionAll(df1) / df.unionByName(df1) 集合并
- df.summary()
- df.take() 同head limit
- df.toDF(*cols) 转为新的df
- df.toJSON(use_unicode=True) 转为新的JSON
- df.toLocalIterator() 转为新的生成器
- df.toPandas() 转pandas的df
- df.where() 等价于filter
- df.withColumn(colName,col)
+ 如df.withColumn('age2', df.age + 2) 生成新的列age2
- df.withColumnRenamed("age","age2") 重命名列
- df.withWatermark(eventTime, delayThreshold)这里主要可以发现筛选,去重、分类汇总等大部分方法跟Pandas的用法都是完全相同的,笔者就几个与Pandas中有显著区别的点做些注释:
- 向DataFrame中增加新的列时,Pandas直接 df["new_col"] = 0 或者在等号右边赋值一个list或numpy.darray都是可行的,但是在PySpark中必须使用df.withColumn("new_col",new_column)的方法,其中new_column必须是pyspark.sql.Column类的对象(如df.old_col或df["old_col"]就属于这类对象),不能是list或者scalar,如果想要全部赋予一个标量的话,可以通过pyspark.sql.functions中的lit函数生成一个单一值的Column,至于如何通过list创建一个pyspark.sql.Column对象,用户文档里也没有写(用户文档里只是说了df.old_col是一个pyspark.sql.Column类的对象),笔者也没深究,感觉可能需要使用createDataFrame方法来做。
- 同样的在选取列时,Pandas直接df[["col1","col2","col3"]]即可,PySpark一般使用df.select("col1","col2","col3")
- df.groupby或df.groupBy的返回值与Pandas的groupby方法返回值用法有很大区别,至少PySpark的返回结果是不Iterable的,可能是PySpark开发的初衷就不允许用循环一个个处理分组结果这种效率低下的手段,取而代之的groupby后的apply函数(反而在df中没有apply函数),是笔者没有弄得特别明白,建议可以详细看一些pandas.sql.GroupedData中的相关说明,以下是一个apply函数在GroupedData中的使用示例👇
from pyspark.sql.functions import udf, PandasUDFType df = spark.createDataFrame([(1, 1.0), (1, 2.0), (2, 3.0), (2, 5.0), (2, 10.0)],("id", "v")) @udf("id long, v double", PandasUDFType.GROUPED_MAP) def normalize(pdf): v = pdf.v return pdf.assign(v=(v - v.mean()) / v.std()) df.groupby("id").apply(normalize).show() # 输出结果: 对于每个id对应的一些数据行,将它们的v字段进行归一标准化(均0方1) - 正如第2点中提到的df中没有apply函数,但是有类似的foreach函数,将作为参数的函数应用到每个数据行Row中。但是笔者在这里更加推荐pyspark.sql.functions中的pandas_udf与udf方法(即user-defined function用户自定义函数),但是注意这种方法的使用需要预先安装pyarrow(version >= 0.8.0),截至本文发布pyarrow最新版为0.17.0,pyspark最新版本为2.4.5。
from pyspark.sql.functions import col, pandas_udf, udf from pyspark.sql.types import LongType, StringType @udf('string') # 这里的udf可以改写成pandas_udf, 同样可以出结果, 但是会发现之后res无法collect,show, 报错为Py4J Error: collectToPython 之类的, 初步查明是jdk python pyspark之间版本不兼容的问题, 但是改写成udf相对可行 def multiply_func(a,b): return "test ".format(a,b) res = df2.select(multiply_func(col("TRANSLEADTIME"),col("TRANSLEADTIME")))这里举了一个比较蠢的例子,假设DataFrame类型的变量df2中只有字段TRANSLEADTIME,我们进行一个简单的多列运算(若TRANSLEADTIME为0,则生成新的一列为字符串类型的数据:"test 0 0")如上所示👆,当然你可以写得更复杂,更有意义一些,重要的是因为需要使用JDK编译,与Java函数一样,需要用修饰符@来标注映射函数的返回值的数据类型;特别地,如上面代码中的注释部分所述因为笔者的Python, PySpark, JDK版本分别为3.6.1,2.4.5,9.0.4,似乎是在版本上有所不兼容,如果使用pandas_udf则会报错,但是udf仍然是可行的,根据用户文档所述,udf在简单的算术运算符构造的映射函数下是具有较高的效率,但如果映射函数复杂,pandas_udf更加适用。
-
特别地,无论是DataFrame还是自定义函数UDF,都可以在数据库中注册成数据表和函数,通过SQL语句进行调用(使用sqlContext.sql("SELECT * FROM DF")或spark.sql("SELECT * FROM DF"),前提是DF已经被注册为表,返回结果仍为DataFrame)。以注册函数为例👇
# udf.register方法示例 # Example 1 当f为python函数 print("========= Example 1 ==========") # 1.1 strlen = spark.udf.register("stringLengthString", lambda x: len(x)) print(spark.sql("SELECT stringLengthString('test')").collect()) print(spark.sql("SELECT 'foo' AS text").select(strlen("text")).collect()) # 1.2 _ = spark.udf.register("stringLengthInt", lambda x: len(x), IntegerType()) print(spark.sql("SELECT stringLengthInt('test')").collect()) # 1.3 _ = spark.udf.register("stringLengthInt", lambda x: len(x), IntegerType()) print(spark.sql("SELECT stringLengthInt('test')").collect()) # Example 2 当f为自定义函数 print("========= Example 2 ==========") ## 2.1 slen = udf(lambda s: len(s), IntegerType()) _ = spark.udf.register("slen", slen) print(spark.sql("SELECT slen('test')").collect()) ## 2.2 random_udf = udf(lambda: random.randint(0, 100), IntegerType()).asNondeterministic() new_random_udf = spark.udf.register("random_udf", random_udf) print(spark.sql("SELECT random_udf()").collect()) ## 2.3 pandas_udf示例 pandas_udf("integer", PandasUDFType.SCALAR) def add_one(x): return x + 1 _ = spark.udf.register("add_one", add_one) print(spark.sql("SELECT add_one(id) FROM range(3)").collect()) ## 2.4 pandas_udf("integer", PandasUDFType.GROUPED_AGG) def sum_udf(v): return v.sum() _ = spark.udf.register("sum_udf", sum_udf) q = "SELECT sum_udf(v1) FROM VALUES (3, 0), (2, 0), (1, 1) tbl(v1, v2) GROUP BY v2" #print(spark.sql(q).collect()) # 会报错: 应该会输出[Row(sum_udf(v1)=1), Row(sum_udf(v1)=5)]输出结果如下所示👇
========= Example 1 ========== [Row(stringLengthString(test)='4')] [Row(stringLengthString(text)='3')] [Row(stringLengthInt(test)=4)] [Row(stringLengthInt(test)=4)] ========= Example 2 ========== [Row(slen(test)=4)] [Row(random_udf()=44)] [Row(add_one(id)='1'), Row(add_one(id)='2'), Row(add_one(id)='3')] -
最后在DataFrame遍历上也与PySpark与Pandas也存在很大区别,具体如下所示👇
# pandas遍历dataframe for i in range(df_pandas.shape[0]): print(df_pandas.loc[i,"colName"]) # pyspark遍历dataframe for row in df_spark.collect(): print(row.colName)其中df_spark.collect()返回值类型为list,当中每个元素为pyspark.sql.Row类的对象。不过似乎也可以用df.toLocalIterator()得到一个生成器来遍历。
作为这部分的结束,笔者将列数据pyspark.sql.Column下的一些方法做一个汇总,基本与Pandas较为类似;
5. 数据列pyspark.sql.Column用法
- df.colName 或者 df["colName"]
- df.colName + 1 或者 1/df.colName
- 下面用col代表df.colName:
- col.asc() 升序 用于排序
+ df.orderBy(df.name.asc())
+ 派生: asc_nulls_first() asc_nulls_last() desc() desc_nulls_first() desc_nulls_last()
- col.astype(dataType) 等价于cast(可以是StringType(), 也可以写成"string")
- col.between(lowerBound, upperBound) 用于筛选
- col.bitwiseAND(col1) 做AND运算
- col.bitwiseOR(col1)
- col.bitwiseXOR(col1)
- col.contains(other) 字符串型的列包含某个子串的的
+ 派生: endswith(other)
- isNotNull() isNull() 是否为空值 可用于filter
- isin(列表) 用法完全与
- df.name.substr(1,3) 字符串切片
- 条件语句when/otherwise df.select(df.name, F.when(df.age > 4, 1).when(df.age < 3, -1).otherwise(0)).show()
非常重要的pyspark.sql.functions模块
6. pyspark.sql.functions 模块下的诸多方法: 虽然用udf基本上可以解决大部分的问题, 但一些内置函数总归可以有好处的
- 这些函数都有一个通用的方法!!!!!!!!!!!!!!!!!
+ df.select(FUNCTION(...).alias("result")).collect()
- abs(col)
- approx_count_distinct(col) <==> 这个貌似跟理解的也不太一样
+ df.agg(approx_count_distinct(df.age).alias('distinct_ages')).collect()
- array(*cols) 返回列表(跟collect()的效果差不多)
- array_contains(col,value) 返回包含某个value的列单元(String)
- array_distinct(col) 好像跟我理解的不太一样
- array_except(col1,col2)
- array_intersect(col1,col2)
- lit(value)
+ df.withColumn('new_col', lit(1)) 创建新的一列默认值全是1的数据
- asc asc_null_first 同上面的df.col的方法
- ascii(col)
- atan(col)
- atan2(col1,col2)
- concat(*cols) # 非列名
- col(colName) 选定一个列(见apply的用法)
- collect_list(colName)
- collect_set(colName)
+ df2 = spark.createDataFrame([(2,), (5,), (5,)], ('age',))
+ df2.agg(collect_list('age')).collect() # [Row(collect_list(age)=[2, 5, 5])]
+ df2.agg(collect_set('age')).collect() # [Row(collect_set(age)=[5, 2])]
- avg(col)
- base64(col)
- bin(col) 转为二进制
- count(col)
- date_sub(df.date,1) 前一天 date_add(df.date,1) 后一天
- date_format('date','MM/dd/yyy') 将日期格式的转为字符串
- date_diff(df.d1,df.d2) # 两个日期的差距
- dayofmonth(col)
- dayofweek(col)
- dayofyear(col)
- weekofyear(col)
- decode(col)
- expr(str) # 很重要的一个函数
+ df.select(expr("length(name)")).collect()
- factorial(col)
- flatten(col) 如果col中每个元素是一个多维列表, 化为一维的列表
- format_string('%d %s', df.a, df.b))
- least/greatest(df.a,df.b,df.c) # 取每行abc字段最小/大的那个
- year month hour minute second等时间的函数
- isnan(col) 与 isnull(col) 缺失与空值
- instr(df.s,substring="ly")
- length(col) 字符串型的
- levenshtein(df.a,df.b)
- locate(substr="b",df.s,pos=1) # 确定子串的位置
- log(col)
- lower(col)
- max min mean m
- df.groupby("id").agg(mean_udf(df['v'])).show()
- df.groupby("id").apply(normalize).show() 分组后分别标准归一化
- round(col,scale=0) 默认保留0位小数4
- substring(col,pos,len) 取子串
- to_date(col,format) 完全与pandas.to_date相同
- trim(col) 去除空格
- udf(f=None,returnType=StringType)
+ random_udf = udf(lambda: int(random.random() * 100), IntegerType()).asNondeterministic()这个部分有很多有意义的函数,主要是对pyspark.sql.Column对象进行的函数操作,虽然只要能熟练运用pandas_udf与udf就可以了,但是这些自定义函数的编译是相当耗时间的(因为要转为Java的编译文件),能用一些现成的函数总归是方便的,很多方法依然与Pandas类似,比较常用的是lit函数用于生成一个单一值的Column,可以用于向DataFrame添加新的默认值的列,此外collect_set与collect_list基本上对应了Pandas中的df.col.unique()与df.col.tolist(),总之PySpark的数据由于存储结构的问题在处理上不如Pandas便捷(也可能是因为使用经验少,不够熟练),总之还是熟能生巧吧。
另外PySpark在ml与mllib模块中提供了大量的统计分析与机器学习的接口,不过笔者可能认为会scipy,sklearn差不多也够了,这里举一个SVM的简单使用示例,现在感觉sklearn很长时间不用也不知道怎么用了。
# -*- coding: UTF-8 -*-
import pandas
from pyspark import SparkContext
from pyspark.sql import SparkSession, SQLContext
from pyspark.sql import Row
from pyspark.ml.classification import LinearSVC, LinearSVCModel
from pyspark.ml.linalg import Vectors
sc = SparkContext("local","$mytest")
spark = SparkSession.builder.master("local").appName("$mytest").getOrCreate()
sqlContext = SQLContext(sc)
df = sc.parallelize([
Row(label=1.0, features=Vectors.dense(1.0, 1.0, 1.0)),
Row(label=0.0, features=Vectors.dense(1.0, 2.0, 3.0))]).toDF()
svm = LinearSVC(maxIter=5,regParam=0.01)
model = svm.fit(df)
print(model.coefficients) # DenseVector([0.0, -0.2792, -0.1833])
print(model.intercept) # 1.0206118982229047
print(model.numClasses) # 2
print(model.numFeatures) # 3
test0 = sc.parallelize([Row(features=Vectors.dense(-1.0, -1.0, -1.0))]).toDF()
result = model.transform(test0).head()
print(result.prediction) # 1.0
print(result.rawPrediction) # DenseVector([-1.4831, 1.4831])
svm_path = "svm"
svm.save(svm_path)
svm2 = LinearSVC.load(svm_path)
print(svm2.getMaxIter()) # 5
model_path = "svm_model"
model.save(model_path)
model2 = LinearSVCModel.load(model_path)
print(model.coefficients[0] == model2.coefficients[0]) # True
print(model.intercept == model2.intercept) # True
溜了,感觉PySpark还是需要在实践中才能学好的,大致入个门也就差不多,近期准备做个有趣点的爬虫,如果能做好的话感觉可以快乐一阵子。
分享学习,共同进步!
以上是关于日常PySpark包DataFrame相关处理小结的主要内容,如果未能解决你的问题,请参考以下文章