数据分析工具篇——Pyspark实现PCA主成分
Posted 数据python与算法
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据分析工具篇——Pyspark实现PCA主成分相关的知识,希望对你有一定的参考价值。
代码概览

Pyspark是近段时间笔者接触到的比较高效的大数据处理工具,他的亮点是整理出了数据分析过程中两个最高频应用的工具:pandas的DataFrame包和sklearn包,能够方便的完成数据处理及模型构建两块内容,上一篇笔者整理了Pyspark的常规用法,本篇以一个案例的形式串联一下pyspark的内容:
在小数据集中构建一个PCA模型是非常方便的,DataFrame构建完成后直接调用sklearn的PCA包即可,那么,在大数据集中是否也是这样方便呢?
回答是肯定的,这也是pyspark方便的地方~
原理依然如此,不过步骤上添加了几个环节,毕竟数据集获取就不能直接read_csv了,而是从hive库中提取需要的数据集,我们看完整的代码:
#!/usr/bin/env python# _*_ UTF-8 _*_# 个人公众号:livandatafrom pyspark.ml.feature import PCA as PCAmlfrom pyspark.ml.feature import VectorAssemblerfrom pyspark.sql import SparkSessionspark = SparkSession\.builder\.appName("PythonWordCount")\.master("local") \.getOrCreate()spark.conf.set("spark.executor.memory", "500M")sc = spark.sparkContext# 1)数据获取:# sqlDF = spark.sql("SELECT a, b, collect_list(c) FROM table GROUP BY a, b")data = spark.createDataFrame([[1,3,[2,3,5,6,7,6,4,6]],[4,6,[5,5,6,7,6,3,1,6]],[7,9,[8,5,3,5,6,7,6,8]]], ['a','c','b'])# 2)将list转化成向量:length = len(data.select('b').take(1)[0][0])assembler_exploded = VectorAssembler(inputCols=["b[{}]".format(i) for i in range(length)],outputCol="b_vector")df_exploded = data.select(data["a"], *[data["b"][i] for i in range(length)])converted_df = assembler_exploded.transform(df_exploded)final_df = converted_df.select("a", "b_vector")# 3)PCA计算:pca = PCAml(k=7, inputCol="b_vector", outputCol="pca")model = pca.fit(final_df)transformed = model.transform(final_df)print(transformed.show())# 4)将向量转化成list存储:def extract(row):return (row.a,) + (row.b_vector,) + (row.pca,) + tuple(row.pca.toArray().tolist())transformed_list = transformed.rdd.map(extract).toDF(["a", "b_vector", "pca"])transformed_list = transformed_list.selectExpr("a", "b_vector", "pca", "_4 as pca_1", "_5 as pca_2", "_6 as pca_3","_7 as pca_4", "_8 as pca_5", "_9 as pca_6", "_10 as pca_7")print(transformed_list.show())# 5)将数据存储到hive中:try:transformed_list.write.format("orc").mode("append").saveAsTable("tmp_db.table")except Exception as e:raise e
有没有被上面这长的代码吓到?
不用紧张,这只是一段看似复杂的简单逻辑,我们来逐一分解一下:
逻辑分解

第一部分SparkSession和sparkContext我们就不做描述了,每一pyspark代码总以这两个结构开始,主要是为pyspark定义运行环境。
1) 数据收集提取部分:
数据收集提取是我们将数据从数据库中提取到spark环境中进行运算。
我们假定表中的数据结构为:
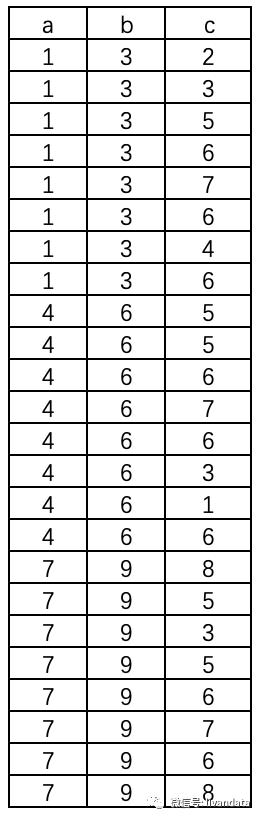
需要做PCA的列为C列,因此将C列行变向量,为简化代码,我们需要尽可能的将数据处理压缩在Hive阶段,俗话说的好:SQL写的好,python写的少,毕竟,python的运行效率并不乐观。
数据处理的SQL如下:
SELECT a, b, collect_list(c)FROM tableGROUP BY a, b
经过这一处理,数据结构变成了:
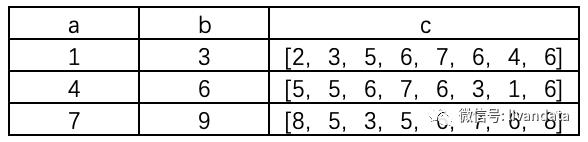
通过spark.SQL函数提取后,我们在spark环境中看到的数据结构即为上图数据。
由于笔者测试环境没有hive环境,因此采用了折中的方式,直接列出数据内容,如上代码:
[[1,3,[2,3,5,6,7,6,4,6]],[4,6,[5,5,6,7,6,3,1,6]],[7,9,[8,5,3,5,6,7,6,8]]]
2) 将list转化为向量:
数据提取到spark环境后就需要将数据中的list数据转化成vector结构,因为主成分分析需要输入的是vector数据结构,而不是list结构。
好在pyspark中提供了向量化的工具VectorAssembler,这一过程相对比较复杂,需要按照VectorAssembler的格式梳理好数据结构,然后再将数据输入其中进行transform操作:
length = len(data.select('b').take(1)[0][0])assembler_exploded = VectorAssembler(inputCols=["b[{}]".format(i) for i in range(length)],outputCol="b_vector")df_exploded = data.select(data["a"], *[data["b"][i] for i in range(length)])converted_df = assembler_exploded.transform(df_exploded)final_df = converted_df.select("a", "b_vector")
得到的final_df即为转化之后的向量。
3) PCA的计算:
向量转化完成后,PCA的训练呼之欲出了,pyspark继承了sklearn高度封装的特点,使用起来非常便利,对应的代码逻辑为:
pca = PCAml(k=7, inputCol="b_vector", outputCol="pca")model = pca.fit(final_df)transformed = model.transform(final_df)print(transformed.show())
定义PCA,训练,然后转化,整个过程简洁高效,运算完成的数据会呈现在数据表新的列中:

4) 将向量转化成list:
数据总是需要以较为简洁的数据结果存储,以方便后期特征的处理和应用,越是高级的数据特性对应的应用范围越小,因此,我们在进行数据存储时将vector结构转化成list结构并拆分到各个列中:
def extract(row):return (row.a,) + (row.b_vector,) + (row.pca,) + tuple(row.pca.toArray().tolist())transformed_list = transformed.rdd.map(extract).toDF(["a", "b_vector", "pca"])print(transformed_list.show())
经过上面的计算,我们得到的结果为:

由于hive表中列名很少用“_”作为列名首字母,所以需要将列名修改一下,使用的函数为selectExpr,操作完成后形成的最终结构为:
5) 将数据存储到hive表中:
形成的数据结构可以直接被存储到hive数据库中,而对应的存储过程为:
try:transformed_list.write.format("orc").mode("append").saveAsTable("tmp_db.table")except Exception as e:raise e
pyspark中的存储也是非常简单的,整个流程可以看出,pyspark在与hive的交互过程中优化的非常简单,操作起来也非常的高效。
经过上面的整个步骤,你有没有对pyspark有一个初步的认知呢?
或者有哪些常用的应用场景,欢迎大家来聊,一起探索高效的写法~
以上是关于数据分析工具篇——Pyspark实现PCA主成分的主要内容,如果未能解决你的问题,请参考以下文章