Hive的面试题总结
Posted Maynor学长
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hive的面试题总结相关的知识,希望对你有一定的参考价值。
文章目录
总结下Hive的面试点
Hive可考察的内容有:基本概念、架构、数据类型、数据组织、DDL操作、函数、数据倾斜、SQL优化、数据仓库。面试数据分析工程师更多会考察DDL操作、函数、数据倾斜、Hive优化、数据仓库这些知识点。来看看具体问题吧。
下一篇👇
Spark基础面试题
1、基本概念
基本概念一般会以问答题的方式进行考察,比如在面试的时候直接问:说说你对Hive的理解?Hive的作用有哪些?这种类似的问题
1)说说你对Hive的理解
从概念上讲,Hive是一款开源的基于hadoop的用于统计海量结构化数据的一个数据仓库,它定义了简单的类似SQL的查询语言,称为HQL,允许熟悉SQL的用户查询数据。
从本质上讲:Hive是将HQL语句转换成MapReduce程序的一个工具。
2)什么是数据仓库
数据仓库的概念是在20世纪90年代被提出来,初衷是专门为业务分析建立一个数据中心,解决因为数据太多查询效率低下的问题。一个被广泛接受的定义是:数据仓库(Data Warehouse)是一个面向主题的(Subject Oriented)、集成的(Integrated)、相对稳定的(Non-Volatile)、反映历史变化(Time Variant)的数据集合,用于支持管理决策(Decision Making Support)。
3)简单说说MapReduce
MapReduce是一个软件框架,基于该框架能够容易地编写应用程序,这些应用程序能够运行在大规模集群上,并以一种可靠的,具有容错能力的方式并行地处理上TB级别的海量数据集。MapReduce的思想就是“分而治之”,Mapper负责“分”,即把复杂的任务分解为若干个“简单的任务”来处理;Reducer负责对map阶段的结果进行汇总。
4)Hive的作用有哪些
- 可以将结构化的数据文件映射成一张表,并提供类SQL查询功能,方便非java开发人员对hdfs上的数据做 MapReduce 操作;
- 可以对数据提取转化加载(ETL)
- 构建数据仓
5)Hive的使用场景
- 即席查询:利用CLI或者类似Hue之类的工具,可以对Hive中的数据做即席查询,如果底层的引擎使用的是MapReduce耗时会很久,可以替换成Tez或者Spark;
- 离线的数据分析:通过执行定时调度或者脚本去执行HQL语句,并将结果保存;
- 构建数仓时用于组织管理数据库和表。
2、架构
架构这一块主要考察Hive的基本组成,也可以针对具体的部分进行进一步考察。
1)Hive的构成包括哪些部分?
-
用户接口层:常用的三个分别是CLI,JDBC/ODBC 和 WUI。其中最常用的是CLI,CLI启动的时候,会同时启动一个Hive副本。JDBC/ODBC是Hive的客户端,用户通过客户端连接至Hive Server。在启动客户端模式的时候,需要指出Hive Server所在节点,并且在该节点启动Hive Server。WUI是通过浏览器访问Hive。
-
元数据存储:Hive将元数据存储在RDBMS中,有三种模式可以连接到数据库,分别是内嵌式元存储服务器、本地元存储服务器、远程元存储服务器。
-
Driver(Compiler/Optimizer/Executor)
Driver完成HQL查询语句的词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在HDFS上,并由MapReduce调用执行。

2)Hive有哪些方式保存元数据,各有什么特点?
Hive支持三种不同的元存储服务器,分别为:内嵌式元存储服务器、本地元存储服务器、远程元存储服务器,每种存储方式使用不同的配置参数。
内嵌式元存储主要用于单元测试,在该模式下每次只有一个进程可以连接到元存储,Derby是内嵌式元存储的默认数据库。
在本地模式下,每个Hive客户端都会打开到数据存储的连接并在该连接上请求SQL查询。
在远程模式下,所有的Hive客户端都将打开一个到元数据服务器的连接,该服务器依次查询元数据,元数据服务器和客户端之间使用Thrift协议通信。
3)Hive QL语句是怎么执行的?
整个过程的执行步骤如下:
(1) 解释器完成词法、语法和语义的分析以及中间代码生成,最终转换成抽象语法树;
(2) 编译器将语法树编译为逻辑执行计划;
(3) 逻辑层优化器对逻辑执行计划进行优化,由于Hive最终生成的MapReduce任务中,Map阶段和Reduce阶段均由OperatorTree组成,所以大部分逻辑层优化器通过变换OperatorTree,合并操作符,达到减少MapReduce Job和减少shuffle数据量的目的;
(4) 物理层优化器进行MapReduce任务的变换,生成最终的物理执行计划;
(5) 执行器调用底层的运行框架执行最终的物理执行计划。
3、数据组织
数据组织主要考察面试者对Hive的数据库、表、视图、分区和表数据的概念的考察,清楚的说出每个概念的含义就可以了。
1)HIve的存储结构包括哪些?可以具体说说每种结构吗?
包括数据库、表、分区、桶、视图和表数据。
database-数据库在 HDFS 中表现为指定的目录下的一个文件夹,通过$hive.metastore.warehouse.dir可以进行设置;
table-内部表在 HDFS 中表现为某个 database 目录下一个文件夹,默认创建的都是内部表;
external table-外部表与内部表类似,在 HDFS 中表现为指定目录下一个文件夹;
bucket-桶在 HDFS 中表现为同一个表目录或者分区目录下根据某个字段的值进行 hash 散列之后的多个文件;
view-视图与表类似,只读,基于基本表创建,不占存储空间,实际是一连串的查询语句;
表数据对应 HDFS 对应目录下的文件。
2)内部表和外部表的区别吗?
内部表数据由Hive自身管理,外部表数据由HDFS管理;删除内部表会直接删除元数据(metadata)及存储数据;删除外部表仅仅会删除元数据,HDFS上的文件并不会被删除。
3)说说分区表和分桶表的区别?
分区表,Hive 数据表可以根据某些字段进行分区操作,细化数据管理,让部分查询更快,不同分区对应不同的目录;
分桶表:表和分区也可以进一步被划分为桶,分桶是相对分区进行更细粒度的划分。分桶将整个数据内容按照某列属性值的hash值进行区分,不同的桶对应不同的文件。
4、DDL和DML操作
参考:https://blog.csdn.net/weixin_43823423/article/details/85060903
5、数据倾斜
数据倾斜不仅在Hive面试中会被问到,其他只要涉及到大规模程序开发的组件都会问到数据倾斜方面的问题,因为这是在实际工作中经常会出现的问题,如何去避免和解决出现的数据倾斜问题是衡量你代码水平高低的尺子。
1)什么是数据倾斜?
数据倾斜就是数据的分布不平衡,某些地方特别多,某些地方又特别少,导致在处理数据的时候,有些很快就处理完了,而有些又迟迟未能处理完,导致整体任务最终迟迟无法完成,这种现象就是数据倾斜。
2)你知道发生数据倾斜的原因吗?
发生数据倾斜的原因有很多,大致可以归为:
1)key分布不均匀;
2)数据本身的特性,原本按照日期进行分区,如果在特定日期数据量剧增,就有可能造成倾斜;
3)建表时考虑不周,分区设置不合理或者过少;
4)某些 HQL 语句本身就容易产生数据倾斜,如 join。
3)哪些HQL操作可能会发生数据倾斜?
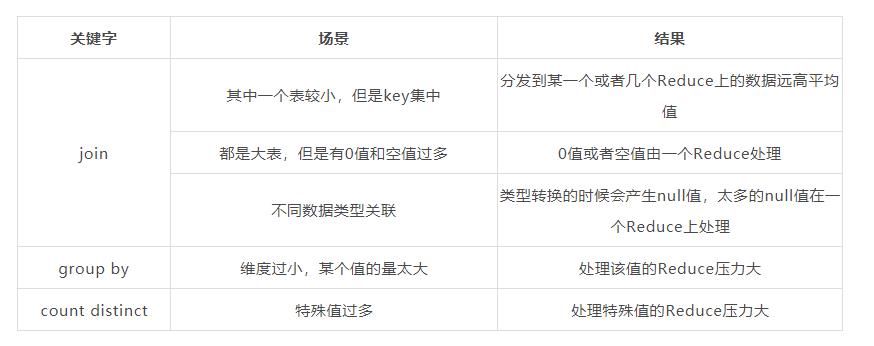
对照上面的表格,可以得出有三种情况可能会发生数据倾斜:
1)join
大小表join的时候,其中一个较小表的key集中,这样分发到某一个或者几个的Reduce上的数据就可能远高于平均值;
两张大表join的时候,如果有很多0值和空值,那么这些0值或者空值就会分到一个Reduce上进行处理;
join的时候,不同数据类型进行关联,发生类型转换的时候可能会产生null值,null值也会被分到一个Reduce上进行处理;
2)group by
进行分组的字段的值太少,造成Reduce的数量少,相应的每个Reduce的压力就大;
3)count distinct
count distinct的时候相同的值会分配到同一个Reduce上,如果存在特殊的值太多也会造成数据倾斜。
6、HIVE优化
1)谈谈如何对join操作进行优化?
join优化是个复杂的问题,可以从以下几点进行优化:
1)小表前置
大小表在join的时候,应该将小表放在前面,Hive在解析带join的SQL语句时,会默认将最后一个表作为大表,将前面的表作为小表并试图将它们读进内存。如果表顺序写反,大表在前面,可能会引发OOM。
2)key值相同
多表join的时候尽量使用相同的key来关联,这样会将会将多个join合并为一个MR job来处理。
3)利用map join特性
map join特别适合大小表join的情况。Hive会将大表和小表在map端直接完成join过程,消灭reduce,效率很高。Hive 0.8版本之前,需要加上map join的暗示,以显式启用map join特性,具体做法是在select语句后面增加/+mapjoin(需要广播的较小表)/。
map join的配置项是hive.auto.convert.join,默认值true;还可以控制map join启用的条件,hive.mapjoin.smalltable.filesize,当较小表大小小于该值就会启用map join,默认值25MB。
2)对于空值或者无意义的值引发的数据倾斜,该怎么处理呢?
这在写程序的时候要考虑清楚,这些异常值的过滤会不会影响计算结果,如果影响那就不能直接过滤掉,可以将这些异常的key用随机方式打散,例如将用户ID为null的记录随机改为负值。
3)如何调整mapper数?
mapper数量与输入文件的split数息息相关,可以通过设置相关参数来调整mapper数。
1)可以直接通过参数mapred.map.tasks(默认值2)来设定mapper数的期望值,但它不一定是最终mapper数;
2)输入文件的总大小为total_input_size。HDFS中,一个块的大小由参数dfs.block.size指定,默认值64MB或128MB。所以得出来的默认mapper数就是:
default_mapper_num = total_input_size / dfs.block.size,但是它也不一定是最终的mapper数;
3)设置参数mapred.min.split.size(默认值1B)和mapred.max.split.size(默认值64MB)分别用来指定split的最小和最大值。那么split大小和split数计算规则是:
split_size = MAX(mapred.min.split.size, MIN(mapred.max.split.size, dfs.block.size));
split_num = total_input_size / split_size。
4)最终得出mapper数:
mapper_num = MIN(split_num, MAX(default_mapper_num, mapred.map.tasks))。
其中可变的参数有:mapred.map.tasks、dfs.block.size(不会为了一个程序去修改,但是也算是一个可变参数)、mapred.min.split.size、mapred.max.split.size,通过调整他们来实现,mapper数的变化。
4)如何调整reducer数?
利用参数mapred.reduce.tasks可以直接设定reducer数量,不像mapper一样是期望值。如果不设这个参数的话,Hive就会自行推测,逻辑如下:
1)参数hive.exec.reducers.bytes.per.reducer用来设定每个reducer能够处理的最大数据量。
2)参数hive.exec.reducers.max用来设定每个job的最大reducer数量。
3)reducer数:
reducer_num = MIN(total_input_size / reducers.bytes.per.reducer, reducers.max)。
reducer数量决定了输出文件的数量。如果reducer数太多,会产生大量小文件,对HDFS造成压力。如果reducer数太少,每个reducer要处理很多数据,容易拖慢执行时间也有可能造成OOM。
5)什么时候又需要合并文件?如何合并小文件?
当有很多小文件的时候没需要合并小文件,可以在输入阶段合并,也可以在输出阶段合并。
1)输入阶段合并
要想文件自动合并,需要更改Hive的输入文件格式,通过参数hive.input.format来更改,默认值是org.apache.hadoop.hive.ql.io.HiveInputFormat,需要改成org.apache.hadoop.hive.ql.io.CombineHiveInputFormat。还需要设置mapred.min.split.size.per.node和mapred.min.split.size.per.rack这两个参数,他们的含义是单节点和单机架上的最小split大小。设置完后,如果发现有split大小小于这两个值(默认都是100MB),则会进行合并。
2)输出阶段合并
设置hive.merge.mapfiles为true可以将map-only任务的输出合并;
设置hive.merge.mapredfiles为true可以将map-reduce任务的输出合并。另外,设置hive.merge.size.smallfiles.avgsize可以指定所有输出文件大小的均值阈值,一旦低于这个阈值,就会启动一个任务来进行合并。
以上是关于Hive的面试题总结的主要内容,如果未能解决你的问题,请参考以下文章