拿下了一个美女图片网站
Posted xhmj12
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了拿下了一个美女图片网站相关的知识,希望对你有一定的参考价值。
来自:FreeBuf.COM,起于凡而非于凡
链接:https://www.freebuf.com/articles/web/250308.html
说明
本文只是介绍一些很简单的思路。而这些思路想要成功实现,基本就需要网站创建者犯一些低级的错误了。
这有些类似于初中、高中的一些数学题,数学没及格的人,也可以用用带入特殊值这个方法,比如带入0、1等等特殊值,虽然比较无脑,但偶尔还真能拿到分。
PS:本文仅用于技术研究与讨论,严禁用于非法用途,违者后果自负
过程
某天在无聊的浏览网页的过程中,偶然间,偶然的点进了某个美女图片网站。
想着也是无聊,就随便看看呗。
结果一个图集就放出3张图,剩余的就要VIP(充钱),太可恶了!
无聊的我就想看看能不能绕过限制,直接看到整个图集。

基本判断
这个网站看上去没有使用一些现成的网站框架,比如wordpress,所以有可能出现低级错误。
如果使用的是网站框架,那我基本就直接放弃了,低版本框架虽然会有通用的漏洞(我没能力利用),但低级错误基本没有的。
先创建了个账户,登录之后查看了下存储,发现没有使用cookie,反而使用了sessionStorage和localStorage:
cookie
sessionStorage
localStorage:略,没什么有价值的内容。
从这里以及文章最开始的图来判断,这个网站使用了不少前端的东西,很可能有些功能就是在前端实现的,或者使用了ajax技术。
登录、权限认定
登录账户后,先判断图集加载页面怎么认定用户的权限的,看看会不会用到sessionStorage的uid或者token。
这里就要介绍下怎么使用火狐浏览器分析前端的代码了。
按F12打开开发者工具,然后按照图中的说明,查看加载图集页面时所发起的ajax请求:

从上图得知,一共发起了4次ajajx请求,根据相应的内容,getContentInfo接口返回了图集的数据。
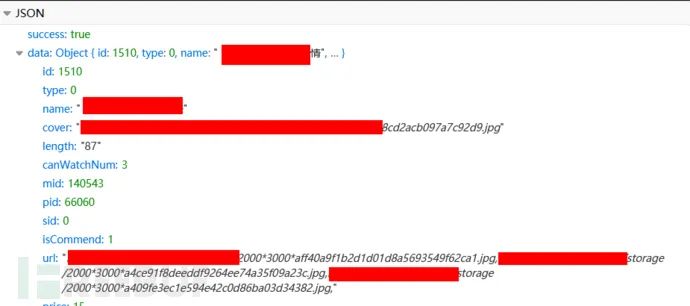
从url这个字段来看,也刚好返回了3个图片的url(用英文逗号分隔即可),也就是可以免费看的那3张图。
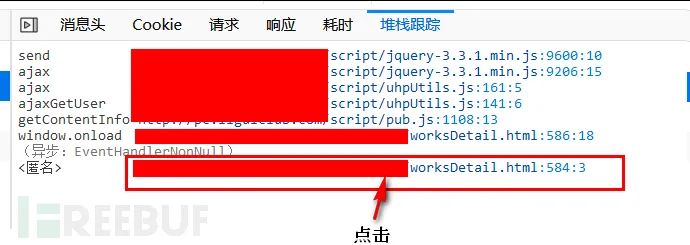
那看看发起请求的代码是怎么样的吧,选中堆栈跟踪,可以看到请求代码的调用过程,从下至上:
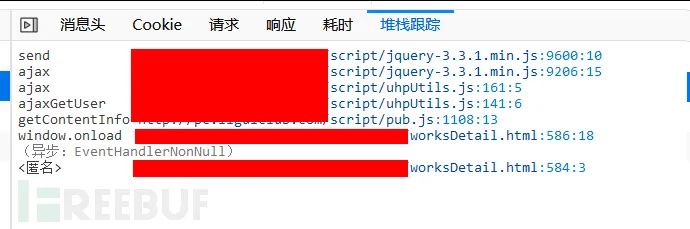
意思就是,在windows.onload中调用了getContentInfo函数,getContentInfo函数中又调用了ajaxGetUser函数……
具体的位置,我们通过点击堆栈跟踪函数名右侧的蓝色链接,就可以直接跳转过去:
window.onload
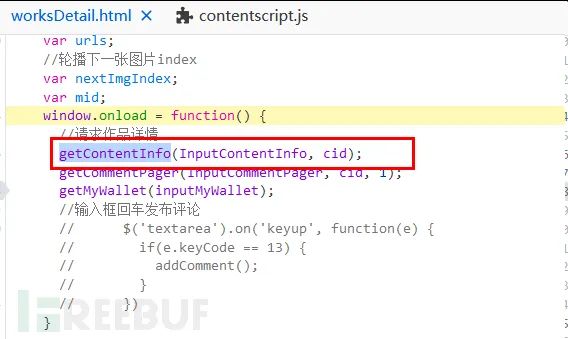
getContentinfo
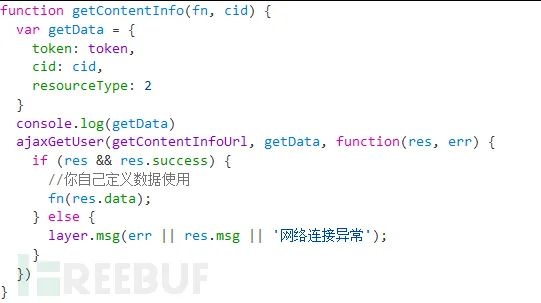
这里可以看到传入了一个object,就是getData,里面的token就是sessionStorage的token:

至于cid,就是图集的id,这里我懒得去找在哪赋值的了。
如果前端代码编写不规范(比如这里对前端代码都没有混淆),那么变量很可能暴露在全局环境中。
直接在开发者工具的控制台中输出cid就能看到值了:
那其实到这我又没法进行下去了,传入token是为了判断用户身份,传入cid是判断是哪一个图集。
而对于token我也没办法对它做什么事情,也没法冒充其他用户的身份。
如果他传入的是uid,也就是用户id,那倒还可以试一试。
最后跟着代码走下去的结果果然是这样,没有什么可以插手的地方。
碰运气
我的思路都是建立在对方犯低级错误的前提下的,那么这种不在后端实现全部的数据处理,而是在前端实现,限制对方观看的某些资源的,还有哪些低级错误呢?
想了下,有没有可能接口返回的数据是完整的,然后只是用js代码将其隐藏而已……
但是最开始查看的返回数据的时候,返回的图片的url就3个:

哦,另外,图片的加载虽然不需要任何权限,基本没有多少的防盗链措施(意思就是可以直接通过图片地址访问图片),但图片的地址是没有规则可言的,如果是按照数字顺序命名,那就可以直接获取到整个图集的图片了。
我不死心,把所有的字段都看了遍,还真有发现,在图集的下面,有一个推荐图片:

所以也返回了这部分的数据:
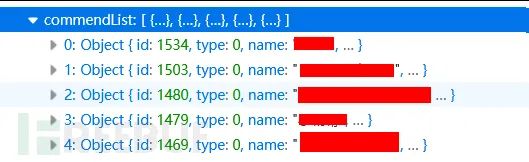
点开一看,终于发现低级错误了,url没做处理,返回了整个图集图片的url:

也就是说,虽然这页面的图集本身的其余图片我没法看到,但是它页面中推荐的图集的图片我全都可以看到:

注意:直接使用图片地址其实还是不能查看到图片,需要在地址后面加上一个参数:

但是这个参数每次登录后都是固定的,可以从localStorage中得到,也可以从免费可观看的图片地址中得到,意义不大。
弱口令
理论上有这招就可以把查看到大部分图集的所有图片了,不过我不是无聊吗,又闲着看了看有没有其他可以做的。
在图集的下面,有一个评论区,当然,也是接口返回的数据。
在这里还是没进行处理,把所有评论用户的用户名全暴露了(手机号码),当然这些客户的口令一般也不会出现很弱的口令,所以我没去尝试。
但是上传这些图集的账户的口令,那就不好说了,关注图集上传者后:

在个人主页的关注部分,接口返回的数据中依然没进行处理,可以直接看到被关注者的用户名:
我也就随便一试,居然还真使用了弱口令,下图是登录成功后”我的作品“页面:

点击一个作品进去,显示已购买:

对后台管理的渗透
这个就不截图详细说明了,思路和上面的差不多,也主要是发现对方在前端的低级错误。
仅仅知道登录页面A的地址,然后查看登录页面的Js文件。
发现登录成功后使用js进行跳转,跳转到主页面B,并且登录成功后的在sessionStorage中设置了一些字段。
先直接访问主页面B,发现会先将页面的框架加载完毕后,再跳转回页面A。
由此可以得出判断,B页面的跳转语句和A页面差不多,都是使用Js语句实现的。
查看B页面加载的Js文件,在跳转回A页面的代码前后找到了判断语句,使用sessionStorage中的字段进行判断。
于是设置sessionStorage中的相关字段,绕过了登录的过程,数据正常加载了,达到了渗透的目的。
感想
其实从开发的角度,如果要保证代码至少在逻辑方面没有明显的漏洞,还是有些繁琐的。
举个简单的例子,如网站的数据检验功能,不允许前端提交不符合当前要求规范的数据(比如年龄文本框部分不能提交字母)。
那么为了实现这个功能,首先开发者肯定要在前端实现该功能,直接在前端阻止用户提交不符规范的数据,否则用户体验会很差,且占用服务器端的资源。
但是没有安全意识或觉得麻烦的开发者就会仅仅在前端用Js进行校验,后端没有重复进行校验。
而我的思路都是很简单的,就是关注比较重要的几个节点,看看有没有可乘之机。
如登录、权限判定、数据加载等前后,对方是怎么做的,用了什么样的技术,有没有留下很明显的漏洞可以让我利用。
像这两个网站,加载的Js文件都没有进行混淆,注释也都留着,还写得很详细。比较凑巧的是,这两个网站都用到了比较多的前端的技术,也都用到了sessionStorage。
特别的,它们都把很多的业务功能放在前端实现,于是存在明显漏洞的可能性就比较大,就值得我去尝试。
-End-2、心态崩了!税前2万4,到手1万4,年终奖扣税方式1月1日起施行~
以上是关于拿下了一个美女图片网站的主要内容,如果未能解决你的问题,请参考以下文章