一文讲解深度学习语言自然语言处理(NLP)第一篇
Posted 苏州程序大白
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一文讲解深度学习语言自然语言处理(NLP)第一篇相关的知识,希望对你有一定的参考价值。
【一文讲解深度学习】语言自然语言处理(NLP)
博主介绍
🌊 作者主页:苏州程序大白
🌊 作者简介:🏆CSDN人工智能域优质创作者🥇,苏州市凯捷智能科技有限公司创始之一,目前合作公司富士康、歌尔等几家新能源公司
💬如果文章对你有帮助,欢迎关注、点赞、收藏(一键三连)和C#、Halcon、python+opencv、VUE、各大公司面试等一些订阅专栏哦
💅 有任何问题欢迎私信,看到会及时回复
💅关注苏州程序大白,分享粉丝福利
自然语言处理概述
NLP 的定义
NLP(Nature Language Processing,自然语言处理)是计算机及人工智能领域的一个重要的子项目,它研究计算机如何处理、理解及应用人类语言。是人类在漫长的进化过程中形成的计算机语言复杂的符号等系统(类似C/Java的符号等系统)。以下是关于自然处理的常见定义:
-
语言处理是科学与自然语言中关于计算机与人类语言转换的领域。
-
语言处理是人工智能领域中一个重要的方向。它研究实现人与计算机之间用自然语言进行有效运作的各种理论和方法。
-
语言处理研究这些方法在交际条件和交际条件下与人交际的一门中及人与计算机网络中的语言问题的语言问题。不断完善这些语言模型,并根据系统的实用性,以及对系统的实用性评测技术。
自然语言处理还有其他一些名称,例如:自然语言(Natural Language Understanding)、计算机语言学(Computational Linguistics)、人类语言技术(Human Language Technology)等等。
NLP的主要任务
NLP 可以分成两类,是生成主要基于新文本或语料的分析,另一种文本或语料。

分词
该任务将文本或语言对日料分隔成更多语言特征单元(单词)。对于拉丁系,词之间有重要的空格等文字,对于中文语言,分词就是例如的,分词直接影响文本的理解。
文本:苏州市姑苏区超市
分词1:苏州市/姑苏区/超市
分词2:苏州/市长/零食/店
词义消歧
例如,在“The dog barked at the mailman”(狗对邮递递员吠叫)和正确的树皮“用作药物”(树皮有时用作药物)中,对于不同的含义。词义消歧类诸如此类的任务。
识别物体识别(NER)
NER尝试从给定的文本或文本语料库中提取实体(例如,人物、位置和组织)。例如,句子:
周一,约翰在学校给了玛丽两个苹果
将转换为:

词性标注(PoS)
PoS 常用的两种称呼分别是名词、动词、形容词、词、词、词等、也可以是词性的词、词、词、动词、动词等。
文本分类
例如文本分类有许多应用场景,垃圾邮件检测、新闻文章分类(例如,政治、科技和运动)和产品评论评分(即正向或负向)。我们可以使用数据标记(即人工对评论标上正面)或者是负面的标签)训练一个分类模型来实现这个任务。
语言生成
可以利用 NLP 来生成新的文本或材料,编写机器天气预报(天气预报、新闻、例如唐诗等),生成文本是一段机器合成的“下面的诗”:
向塞向芶芶临扇,猛牒来惊。向面炎交好
,若隚。
何人改,松仙绕绮霞。偶笑寒栖咽,长闻暖顶时。
失个亦垂谏,守身丈韦鸿。忆及他年事,应愁一故名。
坐忆山高道,为随夏郭间。到乱唯无己,千方得命赊。
问答(QA)系统
QA 技术具有广泛的商业价值,这些技术是聊天机器人和 VA(例如,Google Assistant 和 Apple Siri)的支持。许多公司已经采用对话机器人来提供客户。以下是一段与聊天机器人的:
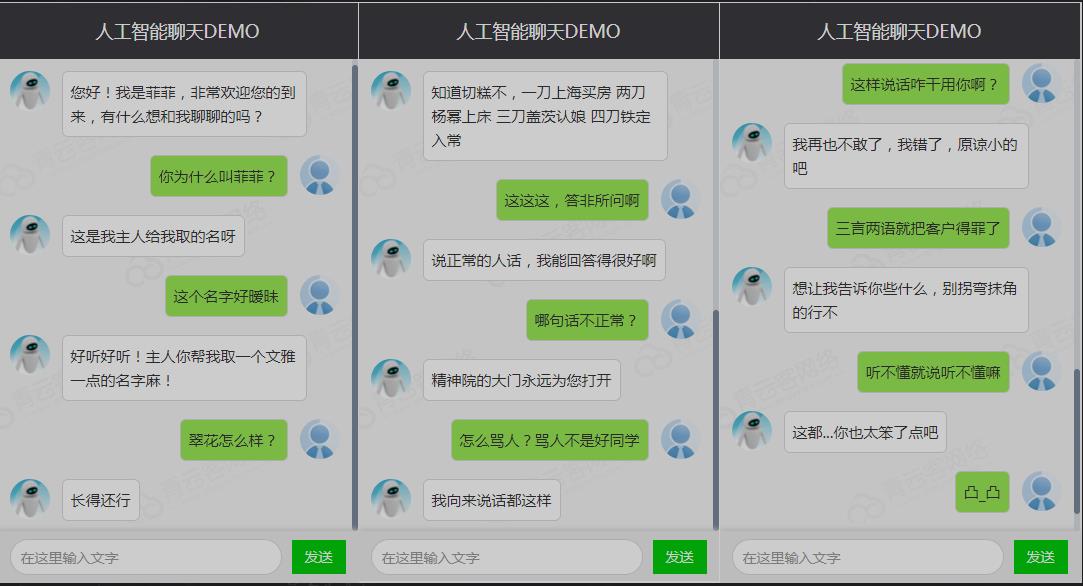
机器翻译(MT)
机器翻译,MT)指将文本由一种语言翻译成另一种语言,是根据一个序列(机器翻译最接近的另一种语言生成)。

NLP的发展历程
NLP的发展发展为:基于规则→其基于统计→基于深入学习,发展大致经历了4个阶段:1956年的萌芽期;1957年1970年的快速期;1971年1993年的低速期;1994年现在的复苏融合期。
- 萌芽期(
1956年前) 1946年:第一台电子计算机诞生148 年香农 把 离散 商业 年: 描述 于 马尔 可 的 机 器 。156 年:Chomsky 又提出了当时的自然语言,并将其运用到处理中。
快速发展期(1957~1970)
一个时期是在不同的处理领域中存在的自然规律和基于两种不同的处理方式。基于这种方法的符号(象征性的)另一派(每个派别)。期间,方法派的研究取得了从60年代开始到长足的发展。乔姆斯基为代表的象征派学者开始了语言理论和生成句法的研究,60年代进行了叶逻辑形式的研究。也取得了很大的进步。
1997 年 TDAP 期重要的美国语言研究成果,美国的语言系统的建立与等。知联系起来了。
低速发展期(1971~1993)
语言研究的结果由于人们看到基于自然语言处理的应用并不能在地段中不断涌现解决,而一连的新问题又出现了,于是,很多人对随着语言处理的研究失去了自然的信心。 70 年代开始,自然语言处理在自然低谷时期。
尽管如此,一些研究人员仍然继续进入了他们的研究。由于他们的出色工作,自然语言处理这一低谷时期同样取得了一些成果。70当年,基于隐马尔可夫模型,HMM的马尔可夫模型(Hidden Markov Model,HMM的马尔可夫模型)统计了最初在语音领域取得重大进展,话语分析(话语分析)也取得了。过去的研究方法进行了反思,有限状态模型和经验主义研究也开始复苏。
复苏融合期(1994年至今)
90年代以后,有两台计算机从根本上发展到促进语言的自然复苏与研究。一件事是90年代以来,计算机的速度和测量量自然增加,为语言处理改善了物质基础,处理事件的事件; 19 可能化是互联网化和网络化 2000 年的另一种商业活动 4 年基于语言的信息和语言的信息和成为自然语言的 00 话题的热门话题。之后 NLP 领域的里程碑事件:
-
2001年:神经语言模型
-
2008年:多任务学习
-
2013年:词嵌入
-
2013年:NLP的神经网络
-
2014年:序列到序列模型
-
2015年:纪律机制
-
2015年:根据记忆的神经网络
-
2018年:预训练语言模型
NLP的困难与挑战
语言歧义
- 不同分词导致的歧义:
例:自动化研究所取得的成就
一:自动化/研究/所/取得/的/成就
成就二:自动化/研究所/取得/的/成就
- 词性歧义:
动物保护警察
“保护” 理解成动词、名词,不一样。
- 结构异义:
喜欢乡下的孩子
关于鲁迅的文章
- 声笑义:
节假日期间,所有博物馆全部(不)开放
- 不同语言结构差异:

- 未知语言不可预测性:
语言不断出现,每年都有大量的新词、出现材料,给一些 NLP 任务造成了困难。以下是 2022 年网络上的新词:
双减
元 宇宙
绝绝子
平躺
- 语言表达的复杂性:
甲:你这人真正的英文?甲:没有英文,英文
?那我就不好意思了。
- 机器语言处理 广泛的背景与常识
中国队最有悬念的是全世界有一个女人也有她和她,他们一个谁也有谁干过球,不过,另一个人打
如果希拉里干过球,只是因为美国总统和美国总统的努力,克林顿也将成为全世界唯一一个干过美国总统和干过美国总统的男人
NLP相关知识构成
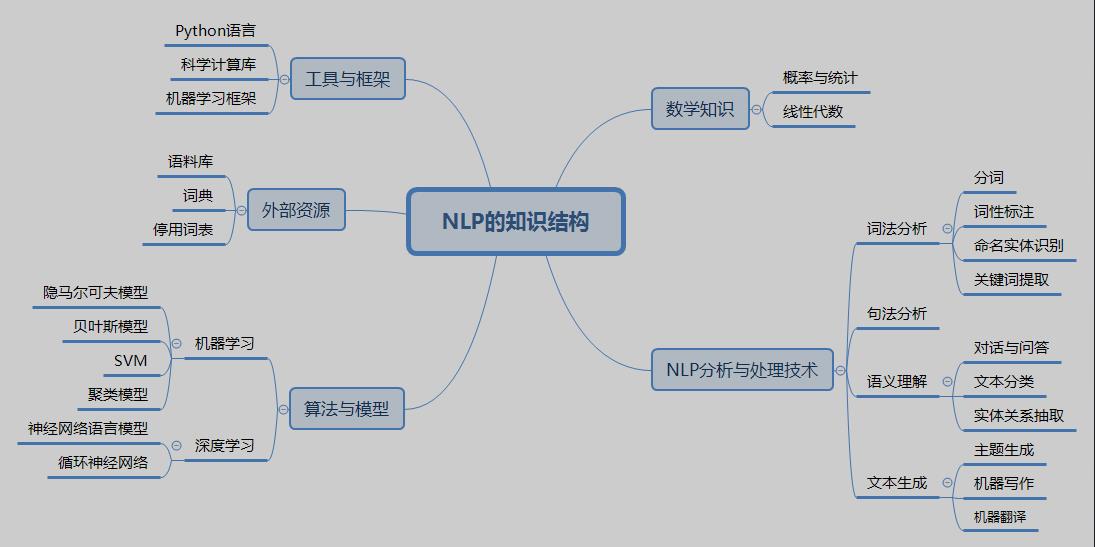
语料库
什么是语料库
语料库是指语言材料(材料库的我们)。现代的语料是指放在以原始语料库里的语料或文字标注的文字文本。 ,语言反应单位的使用和意义,基本以知识的表现形态——语言的原貌。
语料库的特征
-
语料库中存放的是真实中出现过的材料。
-
语料库是计算机为承重语言知识的资源,但语言知识的资源。
-
真实语料需要经过分析、处理和加工,才能成为有用的资源。
语料库的作用
-
支持语言学研究和语言教学研究。
-
支持 NLP 系统的开发。
常用语料库介绍
北京大学计算机语言所语料库(中文),地址: https://opendata.pku.edu.cn/dataverse/icl
London-Lund 英语口语语料库,地址:http 😕/www.helsinki.fi/varieng/CoRD/copora.LLC/
腾讯中文语每包含800个万个单词。其中每一个词都满足2200个维的库,包括最新的一期新词。采用了一个更先进的工具预测的数据和更好的。
维基百科是编辑和最常用的开放网络数据集之一,作为最常用的材料、内容、格式的文本语言,各种语言的维基百科在 NLP 中广泛应用。
传统NLP处理技术
中文分词
中文分词是具有重要意义的基本任务,对文本分词统计有重要的直接影响,有分词规则的理解。分词主要是基于的分词和分词。基于分词主要是通过维护语句,在切切时,将语句的每个子字符串与表中的词进行匹配则切分,缺少则不切分;根据统计找到的分词,是根据统计规则和语言模型,输出一个特色的最大分词(由于需要的知识尚未讲解,暂且不讨论);混合分词就是各种分词方式混合使用,从而提高分词准确率。下面根据介绍规则的分词顺序。
正向最大匹配法
正向最大匹配法(Forward Maximum Matching,FMM)是按照从前到后的顺序对语句进行切分,其步骤为:
-
从左向右取字待分汉语句的m个作为匹配字段,m为词典中词的最长长度;
-
查找进行词典匹配;
-
若成功,则作为匹配词切分出去;
-
若不成功,则将派出一个字,进行剩余的字作为新的匹配;
-
重复上述过程,直到切分所有词为止。
逆向最大匹配法
逆向最大匹配法(Reverse Maximum Matching,RMM)基本原理与FMM基本相同,不同分的方向开始与是相反。RMM是从待分词的右开始,也就是从向左匹配扫描句子,这时句子取m个字作为匹配的地方,找不到匹配的地方,则把前面的一个字,继续匹配。
最大匹配法
进行最大的法匹配,Bi-MM(Bi-MM)的方向正向匹配最大匹配法向结果的逆向匹配最匹配的规则是:
-
如果正,相反则取分词结果数不同的词数少的那个;
-
分词结果结果没有异义任意任意一个;分词中,返回一个不同的字,返回一个不同的主题,
正向最大匹配分词法
# 正向最大匹配分词示例
class MM ( object ): def __init__ ( self ): self.window_size = 3
def cut ( self, text ):
result [文本分词结果
= 0 # 文本长度 = 文本位置
( text_len =) # 长度
dic = [ "苏州" , "苏州市" , "姑苏" , "苏锦" , "零食" , "超市" ]
while text_len start: for size in range (self.window_size + start, start, - 1 )
#取最大长度,逐步比较
piece = text[start:size]
#ifpiece in dic:
#在字典中
result.append(piece)
# 添加到列表
start += len (piece) break else :
#没在字典中,什么都不做
if len (piece) == 1 :
result.append(piece)
# 结果字成词 开始
+= len(片)
break
result.reverse()
返回结果
if __name__ == "__main__":
text = "苏州市苏锦超市"
tk = MM() # 实例化对象
result = tk.cut(text)
print(result)
执行结果:
[ '苏州市', '苏锦', '超市']
逆向最大匹配分词法
# 逆向最大匹配分词示例
class RMM(object):
def __init__(self):
self.window_size = 3
def cut(self, text):
result = [] # 分词结果
start = len(text) # 起始位置
text_len = len(text) # 文本长度
dic = ["苏州", "苏州市", "姑苏", "苏锦", "零食", "超市"]
while start > 0:
for size in range(self.window_size, 0, -1):
piece = text[start-size:start] # 切片
if piece in dic: # 在字典中
result.append(piece) # 添加到列表
start -= len(piece)
break
else: # 没在字典中
if len(piece) == 1:
result.append(piece) # 单个字成词
start -= len(piece)
break
result.reverse()
return result
if __name__ == "__main__":
text = "苏州市姑苏超市"
tk = RMM() # 实例化对象
result = tk.cut(text)
print(result)
执行结果:
[ '苏州', '苏锦', '超市']
Jieba库分词
Jieba 是一款很简单的功能、功能、使用的中文分词工具库,它提供了分词模式:
-
句子合理文本模式:将词最合理,适合分析地。
-
全文:把但中词的所有词组划分出来,速度快,有重复词模式和歧义。
-
搜索引擎模式:在合理模式基础上,对长词再次切分,提高成绩,适合用于搜索引擎分词。
使用 Jieba 库之前,需要进行安装:
pip install jieba== 0.42 . 1
分词代码如下:
# jieba分词示例
import jieba
text = "吉林市长春药店"
# 全模式
seg_list = jieba.cut(text, cut_all=True)
for word in seg_list:
print(word, end="/")
print()
# 精确模式
seg_list = jieba.cut(text, cut_all=False)
for word in seg_list:
print(word, end="/")
print()
# 搜索引擎模式
seg_list = jieba.cut_for_search(text)
for word in seg_list:
print(word, end="/")
print()
执行结果:
苏州/苏州市/姑苏/苏锦/零食/超市/
苏州市/姑苏/超市/
苏州/苏州市/姑苏/超市/
文本高频支出
# 通过tf-idf提取高频词汇
import glob
import random
import jieba
# 读取文件内容
def get_content(path):
with open(path, "r", encoding="gbk", errors="ignore") as f:
content = ""
for line in f.readlines():
line = line.strip()
content += line
return content
# 统计词频,返回最高前10位词频列表
def get_tf(words, topk=10):
tf_dict =
for w in words:
if w not in tf_dict.items():
tf_dict[w] = tf_dict.get(w, 0) + 1 # 获取词频并加1
# 倒序排列
new_list = sorted(tf_dict.items(), key=lambda x: x[1], reverse=True)
return new_list[:topk]
# 去除停用词
def get_stop_words(path):
with open(path, encoding="utf8") as f:
return [line.strip() for line in f.readlines()]
if __name__ == "__main__":
# 样本文件
fname = "d:\\\\NLP_DATA\\\\chap_3\\\\news\\\\C000008\\\\11.txt"
# 读取文件内容
corpus = get_content(fname)
# 分词
tmp_list = list(jieba.cut(corpus))
# 去除停用词
stop_words = get_stop_words("d:\\\\NLP_DATA\\\\chap_3\\\\stop_words.utf8")
split_words = []
for tmp in tmp_list:
if tmp not in stop_words:
split_words.append(tmp)
# print("样本:\\n", corpus)
print("\\n 分词结果: \\n" + "/".join(split_words))
# 统计高频词
tf_list = get_tf(split_words)
print("\\n top10词 \\n:", str(tf_list))
执行结果:
分词结果:
焦点/个股/苏宁/电器/002024/该股/早市/涨停/开盘/其后/获利盘/抛/压下/略有/回落/强大/买盘/推动/下该/股/已经/再次/封于/涨停/主力/资金/积极/拉升/意愿/相当/强烈/盘面/解析/技术/层面/早市/指数/小幅/探低/迅速/回升/中石化/强势/上扬/带动/指数/已经/成功/翻红/多头/实力/之强/令人/瞠目结舌/市场/高度/繁荣/情形/投资者/需谨慎/操作/必竟/持续/上攻/已经/消耗/大量/多头/动能/盘中/热点/来看/相比/周二/略有/退温/依然/看到/目前/热点/效应/外扩散/迹象/相当/明显/高度/活跌/板块/已经/前期/有色金属/金融/地产股/向外/扩大/军工/概念/航天航空/操作/思路/短线/依然/需/规避/一下/技术性/回调/风险/盘中/切记/不可/追高
top10词:
[('已经', 4), ('早市', 2), ('涨停', 2), ('略有', 2), ('相当', 2), ('指数', 2), ('多头', 2), ('高度', 2), ('操作', 2), ('盘中', 2)]
top10词:
[( '已经' , 4 ), ( '指数' , 2 ), ( '涨停' , 2 ) , ('突然' , 2 ), ( '相当' , 2 ), ( '指数' , 2 ), ( '多头' , 2 ), ( '高度' , 2 ), ( '操作' , 2 ), ( '盘中' , 2 )]
词性标注
什么是词性标注
词性是词性的语法,通常也被称为词类。词性标注是识别给定文本中各种词性的性质。在词性中不同环境中不同的词性,也就是词性的基本特征,也就是词性标注的基本词性。来性很大的困难。
词性标注的原理
词性标注生成方式,将其输入的相同分词序列作为一个序列生成来处理。
词性标注
有一定的标注规范,如将名词、标注、动词表示为“n”、“adj”、“v”等词性。以下是北大词性标注部分词性表示:
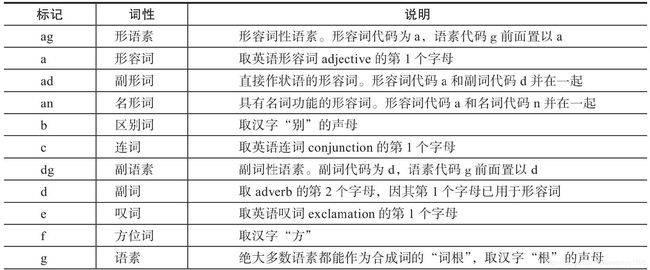

jieba 库词性标注
Jieba 库提供了词性标注功能,采用结合规则和统计的方式,具体为在词性标注的过程中,词典匹配和 HMM 共同作用。词性标注流程如下:
第一步:根据正则表达式判断文本是否为汉字;
第二步:如果判断为汉字,构建 HMM 模型计算最大概率,在词典中查找分出的词性,若在词典中未找到,则标记为 “未知”;
第三步:若不如何上面的正则表达式,则继续通过正则表达式进行判断,分别赋予 “未知”、” 数词 “或 “英文”。
Jieba 库实现词性标注代码实现
import jieba.posseg as psg
def pos(text):
results = psg.cut(text)
for w, t in results:
print("%s/%s" % (w, t), end=" ")
print("")
text = "呼伦贝尔大草原"
pos(text)
text = "梅兰芳大剧院里星期六晚上有演出"
pos(text)
运行结果:
呼伦贝尔/nr 大/a 草原/n
梅兰芳/nr 大/a 剧院/n 里/f 星期六/t 晚上/t 有/v 演出/v
命名实体识别(NER)
命名实体识别(Named Entities Recognition,NER)也是自然语言处理的一个基础任务,是信息抽取、信息检索、机器翻译、问答系统等多种自然语言处理技术必不可少的组成部分。其目的是识别语料中人名、地名、组织机构名等命名实体,实体类型包括 3 大类(实体类、时间类和数字类)和 7 小类(人名、地名、组织机构名、时间、日期、货币和百分比)。中文命名实体识别主要有以下难点:
1、各类命名实体的数量众多。
2、命名实体的构成规律复杂。
3、嵌套情况复杂。
4、长度不确定。
命名实体识别方法有:
1、基于规则的命名实体识别。规则加词典是早期命名实体识别中最行之有效的方式。其依赖手工规则的系统,结合命名实体库,对每条规则进行权重赋值,然后通过实体与规则的相符情况来进行类型判断。这种方式可移植性差、更新维护困难等问题。
2、基于统计的命名实体识别。基于统计的命名实体识别方法有:隐马尔可夫模型、最大熵模型、条件随机场等。其主要思想是基于人工标注的语料,将命名实体识别任务作为序列标注问题来解决。基于统计的方法对语料库的依赖比较大,而可以用来建设和评估命名实体识别系统的大规模通用语料库又比较少,这是该方法的一大制约。
3、基于深度学习的方法。利用深度学习模型,预测词(或字)是否为命名实体,并预测出起始、结束位置。
4、混合方法。将前面介绍的方法混合使用。
命名实体识别在深度学习部分有专门案例进行探讨和演示。
关键词提取
关键词提取是提取出代表文章重要内容的一组词,对文本聚类、分类、自动摘要起到重要作用。此外,关键词提取还能使人们便捷地浏览和获取信息。现实中大量文本不包含关键词,自动提取关检测技术具有重要意义和价值。关键词提取包括有监督学习、无监督学习方法两类。
有监督关键词提取。该方法主要通过分类方式进行,通过构建一个较为丰富完整的词表,然后通过判断每个文档与词表中每个词的匹配程度,以类似打标签的方式,达到关键词提取的效果。该方法能获取较高的精度,但需要对大量样本进行标注,人工成本过高。另外,现在每天都有大量新的信息出现,固定词表很难将新信息内容表达出来,但人工实时维护词表成本过高。所以,有监督学习关键词提取方法有较明显的缺陷。
无监督关键词提取。相对于有监督关键词提取,无监督方法对数据要求低得多,既不需要人工维护词表,也不需要人工标注语料辅助训练。因此,在实际应用中更受青睐。这里主要介绍无监督关键词提取算法,包括 TF-IDF 算法,TextRank 算法和主题模型算法。
TF-IDF 算法
TF-IDF(Term Frequency-Inverse Document Frequency,词频 - 逆文档频率)是一种基于传统的统计计算方法,常用于评估一个文档集中一个词对某份文档的重要程度。其基本思想是:一个词语在文档中出现的次数越多、出现的文档越少,语义贡献度越大(对文档区分能力越强)。TF-IDF 表达式由两部分构成,词频、逆文档频率。词频定义为:
T F i j = n j i ∑ k n k j TF_ij = \\fracn_ji\\sum_k n_kj TFij=∑knkjnji
其中, n i j n_ij nij表示词语 i 在文档 j 中出现的次数,分母 ∑ k n k j \\sum_k n_kj ∑knkj表示所有文档总次数。逆文档频率定义为:
I
D
F
i
=
l
o
g
(
∣
D
∣
以上是关于一文讲解深度学习语言自然语言处理(NLP)第一篇的主要内容,如果未能解决你的问题,请参考以下文章