一文了解基于深度学习的自然语言处理研究
Posted python遇见NLP
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一文了解基于深度学习的自然语言处理研究相关的知识,希望对你有一定的参考价值。
目前,人工智能领域中最热的研究方向当属深度学习。深度学习的迅速发展受到了学术界和工业界的广泛关注,由于其拥有优秀的特征选择和提取能力,对包括机器翻译、目标识别、图像分割等在内的诸多任务中产生了越来越重要的影响。同时在自然语言处理( Natural Language Processing,NLP) 、计算机视觉( Computer Vision,CV) 、语音识别( Speech Recognition,SR) 领域得到广泛应用。
自然语言处理被称为人工智能皇冠上的明珠,因此如何使用深度学习技术推动 NLP 中各个任务的发展是当前研究热点和难点。语言是人类所特有的一种能力,而如何用自然语言与计算机进行通信,是人们长期以来追求的。自然语言处理就是实现人机间通过自然语言交流。但自然语言是高度抽象的符号化系统,文本间存在数据离散、稀疏,同时还存在多义词、一词多义等问题。而深度学习方法具有强大的特征提取和学习能力,可以更好地处理高维度稀疏数据,在 NLP 领域诸多任务中都取得了长足发展。本文主要从基于深度学习的NLP应用研究进展和预训练语言模型两方面进行介绍,最后是基于深度学习的自然语言处理遇到的一些问题及展望。
基于深度学习的自然语言处理应用研究进展
词性标注(Part-Of-Speech tagging,POS)是指确定句子中每个词的词性,如形容词、动词、名词等,又称词类标注或者简称标注。
2017年,Kadari等提出了一种解决CCG超级标签任务的方法。该方法通过结合双向长期短期记忆和条件随机场(BLSTM-CRF)模型,提取输入的特征并完成标注,取得了优异的成果。同年,Feng等提出一种跨语言知识作为关注纳入神经架构的方法。该方法联合应用词层面的跨语言相互影响和实体类层面的单语分布来加强低资源名称标注。实验证明,相比于所有传统对名称标记的方法,该方法取得了重大改进 。
句法分析(Syntactic analysis)的主要任务是自动识别句子中包含的句法单位(如动词、名词、名词短语等)以及这些句法单位相互之间的关系,并通过构造语法树来转化句子。
2017年,Kim等提出了一种采用集合对自然语句进行依赖分析的神经网络框架。该集合方法将滑动输入位置分配给包含要预测的标签位置的分量分类器。如果关键输入特征具有灵活性且相对距离较长等特质,则该方法与具有加权投票的简单集合相比提高了标签准确性。最后,通过对其下限精度的理论估计以及通过对问题进行实证分析来显示集合的影响,从而改变关键输入特征的可移动性的强度。实验结果表明,该方法相对于最先进的依赖解析器,在未标记的与标记的数据上准确性分别提高了0.28%和0.14%。
情感分析(Sentiment analysis)又称为倾向性分析、意见抽取(Opinion extraction)、意见挖掘(Opinion mining)、情感挖掘(Sentiment mining)、主观分析(Subjectivity analysis)等,它是对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程,同样属于文本分类的一种。
2017年,Xiao等提出了基于卷积控制块(CCB)概念的中文情感分类模型。该方法以句子为单位,基于CCB的模型考虑短期和长期的上下文依赖性进行情感分类,将句子中的分词连接到5层CCB中,并取得了对积极情绪的预测准确率达到92.58%的好成绩。同时,Dragoni等提出了一种利用域之间语言重叠的方法来构建支持属于每个域的文档的极性推断的情感模型。该方法将Word嵌入和深度学习架构一起实施到NeuroSent工具,以构建多领域情感模型。同年,Paredes-Valverde等提出了一种基于深度学习的方法。这种方法基于卷积神经网络(CNN)和word2vec,通过实验得到了精确度为88.7%的好成绩。Chen提出将条件随机场(Conditional Random Field,CRF)引入情感分析中,利用BiLSTM和CRF组合模型捕获句子中不同目标,然后利用一维 CNN 进行分类。2018年,Wu等提出了一种混合无监督的方法,以解决情感分析中的长期提取(ATE)和意见目标提取(OTE)这两个重要的任务。该方法通过将被提取名词短语进行过滤得到符合域相关性的意见目标与方面项;最后将所得数据用于训练方面项提取和意见目标提取的深门控循环单元(GRU)网络。这种方法用了很少的标注量,提高了GRU的有效性。与此同时,Hassan等提出了一种CNN和RNN联合框架的方法。该方法通过CNN和RNN联合训练,得到通过长期短期记忆学习的长期依赖关系的卷积层,在情绪分析问题上取得了93.3%的准确性 。同年,黄改娟等人提出一种双重注意力模型,在模型训练过程中使用微博数据集,数据中不仅包含文本信息还包括情感符号。通过注意力机制和情感符号的结合,模型增加了对微博数据中情感知识的获取能力,进而将分类的准确率进行了提升。金志刚等人通过对 BiLSTM 和 Bagging 算法的改进,提出一种新的情感分析Bi-LSTMM-B模型,该模型的优点在于结合了深度学习模型可提取抽象特征的优势和集成学习多分类器共同决策的思想,相比于其它模型,该模型提高了情感分析的准确率。
机器翻译(Machine translation)是利用计算机把一种自然源语言转变为另一种自然目标语言的过程,也称为自动翻译。
2016年,He等提出了将统计机器翻译(SMT)特征(如翻译模型和ngram语言模型)与对数线性框架下的NMT模型结合的方法。实验表明,该方法在NIST开放测试集上获得高达2.33BIEU分数的增益。2017年,LIU提出了一种面向SMT系统组合的大规模特征的深度神经网络组合(DCNN)。该模型采用改进的递归神经网络生成适合短语生成过程的短语对语义向量,并使用自动编码器提高词组生成过程的性能。采用改进的递归神经网络来指导SMT任务中的解码过程,并从另一个解码器中考虑相互影响信息。结果表明,DCNN分别在非均勻系统和语料库组合中分别高于基线1.0~1.9BLEU和1.0~1.58BLEU。2018年,Choi 等人提出一种细粒度注意力用于机器翻译任务中,其中上下文向量的每个维度都将收到单独的注意力分数。2019年,Wu 等人提出一种轻量级的机器翻译模型,将动态卷积与自注意力机制相结合,在英语—德语翻译任务中取得了优异的效果。
文本分类是利用计算机将文本集按照一定的分类体系或标准,进行自动分类标记的过程。
2016年,Ji提出了一个基于递归神经网络和卷积神经网络的模型。该模型在3个不同的数据集上实现了在文本分类领域最先进的结果。2017年,Yu等提出了一种用于自动故事分割的混合神经网络隐马尔可夫模型方法。该方法通过深度神经网络(DNN)把单词出现的频率与相应的主题词后验概率相结合。结果表明,该方法显著优于传统的HMM方法。2018年,他们又提出通过使用深度神经网络(DNN)来直接预测输人句子的主题类别来学习句子表示。该方法将文本聚类为一个个类,并将类ID用作DNN训练文本的主题标签。结果表明,该方法提出的主题句子表示优于BOW基线和最近提出的基于神经网络的表示 。
预训练语言模型
当前影响最大的预训练语言模型是基于Transformer的双向深度语言模型—BERT。其网络结构如图1所示。
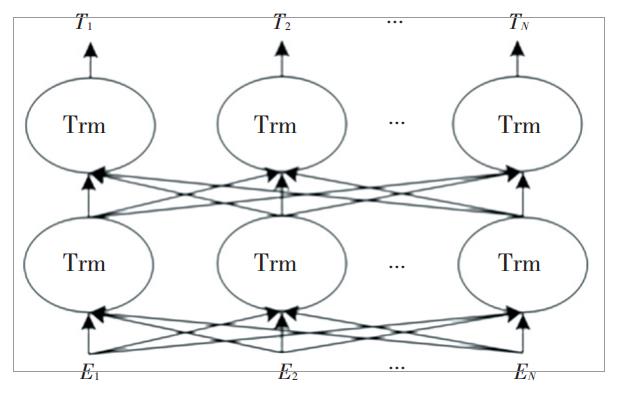
图1 BERT模型
BERT 是由多层双向 Transformer 解码器构成,主要包括 2 个不同大小的版本: 基础版本有 12 层 Transformer,每个 Transformer 中的多头注意力层是12 个,隐 藏 层 大 小 为 768; 加 强 版 有 24 层 Transformer,每个Transformer 中的多头注意力层是24 个,隐藏层大小为 1024。由此可见深而窄的模型效果要优于浅而宽的模型。目前 BERT 在机器翻译、文本分类、文本相似性、阅读理解等多个任务中都有优异的表现。BERT 模型的训练方式包括 2 种:
( 1) 采用遮盖单词的方式。将训练语料中的80%的单词用[MASK]替换,如 my dog is hairy—> my dog is [MASK]。还有 10%的单词进行随机替换,如 my dog is hairy—> my dog is banana。剩下10%则保持句子内容不变。
( 2) 采用预测句子下一句的方式。将语料中的语句分为 A 和 B,B 中的 50%的句子是 A 中的下一句,另外的 50%则是随机的句子。通过上述 2 种方式训练得到通用语言模型,然后利用微调的方法进行下游任务,如文本分类、机器翻译等任务。较比以前的预训练模型,BERT 可以捕获真正意义上的双向上下文语义。但 BERT 也有一定的缺点,既在训练模型时,使用大量的[MASK]会影响模型效果,而且每个批次只有 15%的标记被预测,因此 BERT 在训练时的收敛速度较慢。此外由于在预训练过程和生成过程不一致,导致在自然语言生成任务表现不佳,而且 BERT 无法完成文档级别的 NLP 任务,只适合于句子和段落级别的任务。
XLNet是一种广义自回归的语言模型,是基于 Transformer-XL而构建的。Transformer 的缺点:
(1)字符之间的最大依赖距离受输入长度的限制。
(2)对于输入文本长度超过 512 个字符时,每个段都是从头开始单独训练,因此使训练效率下降,影响模型性能。针对以上 2 个缺点,Transformer-XL引入 了 2 个 解 决 方 法: 分 割 循 环 机 制 ( Division Recurrence Mechanism) 和 相 对 位 置 编 码 ( Relative Positional Encoding) 。Transformer -XL 的测试速度更快,可以捕获更长的上下文长度。
无监督表征学习在 NLP 领域取得了巨大成功,在这种理念下,很多研究者探索了不同的无监督预训练目标,而自回归语言建模和自编码语言是 2 个最成功的预训练目标。而 XLNet 是一种集合了自回归和自编码 2 种方式的泛化自回归方法。XLNet不使用传统自回归模型中的固定前向或后向因式分解顺序,而使用一种随机排列自然语言预测某个位置可能出现的词,这种方式不仅可以使句子中的每个位置都能学习来自所有位置的语境信息,而且还可以构建双向语义,更好地获取上下文语义。由于XLNet 采用的是 Transformer -XL,因此模型性能更优,尤其在包含长文本序列的任务中。通过 XLNet训练得到语言模型后,可以用于下游相关任务,如阅读理解,基于 XLNet 得到的结果已经远超人类水平,在文本分类、机器翻译等任务中取得了优异的效果。
无论是 BERT 还是 XLNet 语言模型,在英文语料中表现都很优异,但在中文语料中效果一般, ERNIE则是以中文语料训练得出一种语言模型。ERNIE 是一种知识增强语义表示模型,其在语言推断、语义相似度、命名实体识别、文本分类等多个NLP 中文任务上都有优异表现。ERNIE 在处理中文语料时,通过对预测汉字进行建模,可以学习到更大语义单元的完整语义表示。ERNIE 模型内部核心是由 Transformer 所构成,其模型结构如图 2 所 示。模型结构主要包括 2 个模块,下层模块的文本编码器( T-Encoder) 主要负责捕获来自输入标记的基本词汇和句法信息,上层模块的知识编码器( K- Encoder) 负责从下层获取的知识信息集成到文本信息中,以便能够将标记和实体的异构信息表示成一个统一的特征空间中。
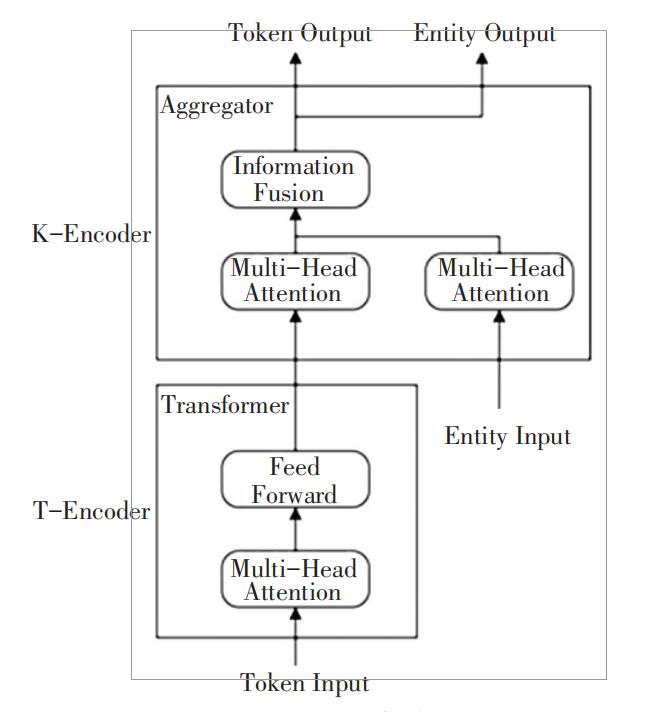
图2 ERNIE模型
ERNIE 模型通过建立海量数据中的实体概念等先验语义知识,学习完整概念的语义表示,即在训练模型时采用遮盖单词的方式通过对词和实体概念等语义单词进行遮盖,使得模型对语义知识单元的表示更贴近真实世界。此外,ERNIE 模型引入多源语料训练,其中包括百科类、新闻资讯类、论坛对话等数据。总体来说,ERNIE 模型通过对实体概念知识的学习来学习真实世界的完整概念语义表示,使得模型对实体概念的学习和推理能力更胜一筹,其次通过对训练语料的扩充,尤其是引入了对话语料使得模型的语义表示能力更强。
问题与展望
当今,该方面的研究的难点是在模型构建过程中优化调整参数。最大的问题还是在解决训练数据的需求上。深度学习算法,不管是对训练数据量的要求,还是对运算时间的要求,都远远高于其他算法。深度学习算法结果的准确性十分依赖于训练数据的数量。因此,在不同的领域优化相关的深度学习算法,使之可以拥有更高的学习效率,成为了下一步发展的方向。
在面对这种问题时,可以引用混合传统机器学习方法与深度学习方法相结合的方式来解决。深度学习是一种模仿人脑学习的过程,这就意味着当我们用它去解决一个任务时,要拋弃现有的知识,从头开始学习。因此,将已有的知识(即传统的机器学习方法)与深度学习方法相结合,从而加快深度学习的学习效率,成为了下一步研究的方向。
在深度学习过程中都需要大量的数据进行支撑。然而,在自然语言处理中一部分任务无法使用海量无标注语料进行学习,因此相关领域的海量有监督数据就显得十分有必要。
对于这个问题,希望各个领域有能力的政府部门、企业和研究院可以提供相关的数据,给予从事相关研究人员使用数据的权力。但这种解决方法依然有待于数据质量、数据安全等问题的解决。在深度学习过程中都需要大量的数据进行支撑。然而,在自然语言处理中一部分任务无法使用海量无标注语料进行学习,因此相关领域的海量有监督数据就显得十分有必要。对于这个问题,希望各个领域有能力的政府部门、企业和研究院可以提供相关的数据,给予从事相关研究人员使用数据的权力。但这种解决方法依然有待于数据质量、数据安全等问题的解决。
往期推荐
完
长按二维码识别关注
以上是关于一文了解基于深度学习的自然语言处理研究的主要内容,如果未能解决你的问题,请参考以下文章