java map key可以重复吗 Posted 2023-04-11
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了java map key可以重复吗相关的知识,希望对你有一定的参考价值。
在Java中,有一种key值可以重复的map,就是IdentityHashMap。在IdentityHashMap中,判断两个键值k1和 k2相等的条件是 k1 == k2 。在正常的Map 实现(如 HashMap)中,当且仅当满足下列条件时才认为两个键 k1 和 k2 相等:(k1==null ? k2==null : e1.equals(e2))。html
参考技术A
不可以,map是无序的,它的查询需要通过key的值来查找,如果你定义两个同样的key,那么一个key就对应了多个值,这样就违背了java对map的定义,键和值是一一对应的。所以key不可以重复本回答被提问者采纳
参考技术B
key唯一但是值却可以重复
参考技术C
key肯定不能重复啊,如果重复了怎么找到对应的value
redis可以多key对应一个value吗
redis可以多key对应一个value,设置方法为:
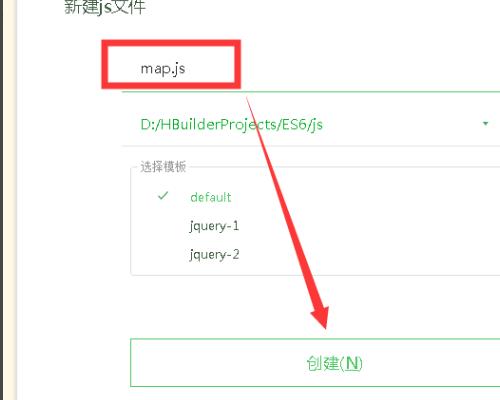
1、打开HBuilderX工具,新建web项目并在js文件夹中,创建一个js文件map.js。
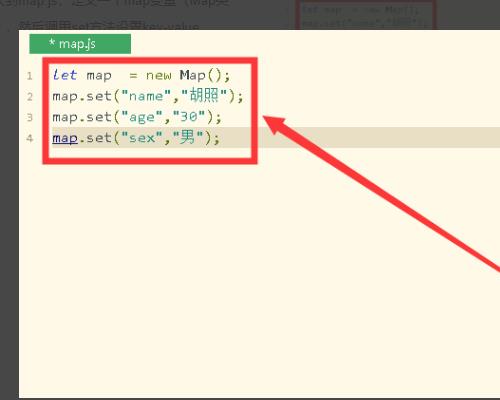
2、进入到map.js,定义一个map变量(Map类型),然后调用set方法设置key-value。
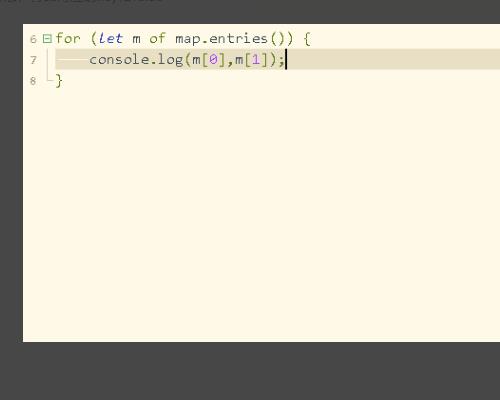
3、调用for...of语句,遍历map变量的值,使用entries()方法,打印对应的key和value。
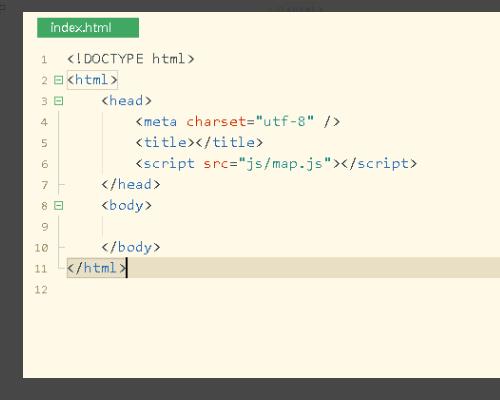
4、接着新建一个HTML5页面,并将map.js引入到页面中。
5、修改map.js,调用window.onload,并定义showKeys方法。
参考技术A
先说redisredis是一个类似memcached的key/value存储系统,它支持存储的value类型相对较多,包括string(字符串)、 list(链表)、set(集合)和zset(有序集合)。在此基础上,redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件(这点儿个人觉得redis比memcache 在数据保存上要安全一些),并且在此基础上实现了master- slave(主从)同步。redis的存取性能很高,SET操作每秒钟 110000 次,GET操作每秒钟 81000 次(速度很爽!)。Redis针对不同的存储类型对象提供了不同的命令。redis目前提供四种数据类型:string,list,set及zset(sorted set)。string是最简单的类型,你可以理解成与Memcached一模一个的类型,一个key对应一个value,其上支持的操作与Memcached的操 作类似。但它的功能更丰富。list是一个链表结构,主要功能是push、pop、获取一个范围的所有值等等。操作中key理解为链表的名字。set是集合,和我们数学中的集合概念相似,对集合的操作有添加删除元素,有对多个集合求交并差等操作。操作中key理解为集合的名字。zset是set的一个升级版本,他在set的基础上增加了一个顺序属性,这一属性在添加修改元素的时候可以指定,每次指定后,zset会自动重新按新的 值调整顺序。可以理解了有两列的mysql表,一列存value,一列存顺序。操作中key理解为zset的名字。 下面提供redis命令:适合全体类型的命令EXISTS key 判断一个键是否存在;存在返回 1;否则返回0;DEL key 删除某个key,或是一系列key;DEL key1 key2 key3 key4TYPE key 返回某个key元素的数据类型 ( none:不存在,string:字符,list,set,zset,hash)KEYS pattern 返回匹配的key列表 (KEYS foo*:查找foo开头的keys)RANDOMKEY 随机获得一个已经存在的key,如果当前数据库为空,则返回空字符串RENAME oldname newname更改key的名字,新键如果存在将被覆盖RENAMENX oldname newname 更改key的名字,如果名字存在则更改失败DBSIZE返回当前数据库的key的总数EXPIRE设置某个key的过期时间(秒),(EXPIRE bruce 1000:设置bruce这个key1000秒后系统自动删除)注意:如果在还没有过期的时候,对值进行了改变,那么那个值会被清除。TTL查找某个key还有多长时间过期,返回时间秒SELECT index 选择数据库MOVE key dbindex 将指定键从当前数据库移到目标数据库 dbindex。成功返回 1;否则返回0(源数据库不存在key或目标数据库已存在同名key);FLUSHDB 清空当前数据库中的所有键FLUSHALL 清空所有数据库中的所有键 处理字符串的命令SET key value 给一个键设置字符串值。SET keyname datalength data (SET bruce 10 paitoubing:保存key为burce,字符串长度为10的一个字符串paitoubing到数据库),data最大不可超过1G。GET key获取某个key 的value值。如key不存在,则返回字符串“nil”;如key的值不为字符串类型,则返回一个错误。GETSET key value可以理解成获得的key的值然后SET这个值,更加方便的操作 (SET bruce 10 paitoubing,这个时候需要修改bruce变成1234567890并获取这个以前的数据paitoubing,GETSET bruce 10 1234567890)MGET key1 key2 … keyN 一次性返回多个键的值SETNX key value SETNX与SET的区别是SET可以创建与更新key的value,而SETNX是如果key不存在,则创建key与value数据MSET key1 value1 key2 value2 … keyN valueN 在一次原子操作下一次性设置多个键和值MSETNX key1 value1 key2 value2 … keyN valueN 在一次原子操作下一次性设置多个键和值(目标键不存在情况下,如果有一个以上的key已存在,则失败)INCR key 自增键值INCRBY key integer 令键值自增指定数值DECR key 自减键值DECRBY key integer 令键值自减指定数值 处理 lists 的命令RPUSH key value 从 List 尾部添加一个元素(如序列不存在,则先创建,如已存在同名Key而非序列,则返回错误)LPUSH key value 从 List 头部添加一个元素LLEN key 返回一个 List 的长度LRANGE key start end从自定的范围内返回序列的元素 (LRANGE testlist 0 2;返回序列testlist前0 1 2元素)LTRIM key start end修剪某个范围之外的数据 (LTRIM testlist 0 2;保留0 1 2元素,其余的删除)LINDEX key index返回某个位置的序列值(LINDEX testlist 0;返回序列testlist位置为0的元素)LSET key index value更新某个位置元素的值LREM key count value 从 List 的头部(count正数)或尾部(count负数)删除一定数量(count)匹配value的元素,返回删除的元素数量。LPOP key 弹出 List 的第一个元素RPOP key 弹出 List 的最后一个元素RPOPLPUSH srckey dstkey 弹出 _srckey_ 中最后一个元素并将其压入 _dstkey_头部,key不存在或序列为空则返回“nil” 处理集合(sets)的命令(有索引无序序列)SADD key member增加元素到SETS序列,如果元素(membe)不存在则添加成功 1,否则失败 0;(SADD testlist 3 /n one)SREM key member 删除SETS序列的某个元素,如果元素不存在则失败0,否则成功 1(SREM testlist 3 /N one)SPOP key 从集合中随机弹出一个成员SMOVE srckey dstkey member 把一个SETS序列的某个元素 移动到 另外一个SETS序列 (SMOVE testlist test 3/n two;从序列testlist移动元素two到 test中,testlist中将不存在two元素)SCARD key 统计某个SETS的序列的元素数量SISMEMBER key member 获知指定成员是否存在于集合中SINTER key1 key2 … keyN 返回 key1, key2, …, keyN 中的交集SINTERSTORE dstkey key1 key2 … keyN 将 key1, key2, …, keyN 中的交集存入 dstkeySUNION key1 key2 … keyN 返回 key1, key2, …, keyN 的并集SUNIONSTORE dstkey key1 key2 … keyN 将 key1, key2, …, keyN 的并集存入 dstkeySDIFF key1 key2 … keyN 依据 key2, …, keyN 求 key1 的差集。官方例子:key1 = x,a,b,ckey2 = ckey3 = a,dSDIFF key1,key2,key3 => x,bSDIFFSTORE dstkey key1 key2 … keyN 依据 key2, …, keyN 求 key1 的差集并存入 dstkeySMEMBERS key 返回某个序列的所有元素SRANDMEMBER key 随机返回某个序列的元素 处理有序集合(sorted sets)的命令 (zsets)ZADD key score member 添加指定成员到有序集合中,如果目标存在则更新score(分值,排序用)ZREM key member 从有序集合删除指定成员ZINCRBY key increment member 如果成员存在则将其增加_increment_,否则将设置一个score为_increment_的成员ZRANGE key start end 返回升序排序后的指定范围的成员ZREVRANGE key start end 返回降序排序后的指定范围的成员ZRANGEBYSCORE key min max 返回所有符合score >= min和score <= max的成员 ZCARD key 返回有序集合的元素数量 ZSCORE key element 返回指定成员的SCORE值 ZREMRANGEBYSCORE key min max 删除符合 score >= min 和 score <= max 条件的所有成员。 使用体会:个人在觉得redis速度是不用说了(很快的),但是很消耗物理内存,算是redis的一个弊端吧,redis适合数据量比较小速度更新快的类型的网站,比如社区,不适合数据比较庞大的网站,比如论坛。以前用redis应用的一个论坛帖子上,但是因为数据量太大,消耗物理内存惊人而放弃了用 redis! 再说说TTSERVERTokyo Cabinet 是一个DBM的实现。这里的数据库由一系列key-value对的记录构成。key和value都可以是任意长度的字节序列,既可以是二进制也可以是字符串。这里没有数据类型和数据表的概念。当做为Hash表数据库使用时,每个key必须是不同的,因此无法存储两个key相同的值。提供了以下访问方法:提供key,value参数来存储,按 key删除记录,按key来读取记录,另外,遍历key也被支持,虽然顺序是任意的不能被保证。这些方法跟Unix标准的DBM,例如GDBM,NDBM 等等是相同的,但是比它们的性能要好得多(因此可以替代它们) 当按B+树来存储时,拥用相同key的记录也能被存储。像hash表一样的读取,存储,删除函数也都有提供。记录按照用户提供的比较函数来存储。可以采用顺序或倒序的游标来读取每一条记录。依照这个原理,向前的字符串匹配搜索和整数区间搜索也实现了。另外,B+树的事务也是可用的。对于定长的数组,记录按自然数来标记存储。不能存储key相同的两条或更多记录。另外,每条记录的长度受到限 制。读取方法和hash表的一样。 Tokyo Cabinet是用C写的,同时提供c,perl,ruby,java的API。Tokyo Cabinet在提供了POSIX和C99的平台上都可用,它以GNU Lesser Public License协议发布。tokyocabinet :一个key-value的DBM数据库,但是没有提供网络接口,以下称TC。tokyotyrant :是为TC写的网络接口,他支持memcache协议,也可以通过HTTP操作,以下称TT。 性能:Tokyo Cabinet 是日本人 平林干雄 开发的一款 DBM 数据库,Tokyo Cabinet基于GNU Lesser General Public License协议发布,采用C语言开发,它可以运行在任何支持C99和POSIX平台上使用。相比一般的DBM数据库有以下几个特点:空间小,效率高,性能高,可靠性高,多种开发语言的支持(现已提供C,Perl,Ruby,Java,Lua的API),支持64位操作系统。该数据库读写非常快,哈希模式写入100万条数据只需0.643秒,读取100万条数据只需0.773秒,是 Berkeley DB 等 DBM 的几倍。Tokyo Tyrant 加上 Tokyo Cabinet,构成了一款支持高并发的分布式持久存储系统,对任何原有Memcached客户端来讲,可以将Tokyo Tyrant看成是一个Memcached,但是,它的数据是可以持久存储的。这一点,跟新浪的Memcachedb性质一样。ttserver和memcache比较:ttserver是数据库,memcached是缓存。两者都是保存<key,value>形式的数据,通过key进行任何操作。ttserver可以将数据持久化保存,memcached全部是保存在内存中,memcached会自动删除过期数据,最长不超过30天。memcached在和一些api配合时,能自动进行数据的出入序列化,读取反序列化。ttserver有主从复制的功能,操作日志等,这完全是数据库才有的东西。据说memcached正在对整体架构做调整,到时候支持plugin机制.会把网络,事件处理,内存存储剥离开来.以后要做基于磁盘的key-value存储就可以写一个存储引擎就成了。memcached的二次开发又步入一个小高潮。
参考技术B
很遗憾的告诉你,暂时不行,不过如果你的value数据量不大的话存多份也没有关系,如果数据量很大可想点折中的办法,比如设置一个主要的mainKey-value,然后再存多个key1-mainKey,key2-mainKey,key3-mainKey,然后通过两次取值来获得value,这样效果也没有太大影响。
以上是关于java map key可以重复吗的主要内容,如果未能解决你的问题,请参考以下文章
java map key可以重复吗
java map的key可以重复吗
map的key可以重复吗
hashmap的key可以重复吗
java 有没有一个集合可以存放重复的key和value
Java中的Map允许有重复元素吗