阅读笔记联邦学习实战——联邦学习智能用工案例
Posted HERODING23
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了阅读笔记联邦学习实战——联邦学习智能用工案例相关的知识,希望对你有一定的参考价值。
联邦学习实战——联邦学习智能用工案例
前言
s
FATE是微众银行开发的联邦学习平台,是全球首个工业级的联邦学习开源框架,在github上拥有近4000stars,可谓是相当有名气的,该平台为联邦学习提供了完整的生态和社区支持,为联邦学习初学者提供了很好的环境,否则利用python从零开发,那将会是一件非常痛苦的事情。本篇博客内容涉及《联邦学习实战》第十三章内容,使用的fate版本为1.6.0,fate的安装已经在这篇博客中介绍,有需要的朋友可以点击查阅。本章介绍如何利用联邦学习构建协同的正能用工解决方案,并在联邦学习的架构上,提出一种基于多人博弈游戏的联邦学习激励机制方案。
1. 智能用工简介
智能用工——一种由人工智能算法赋能的众包平台,它旨在为工作者个人工作管理移动应用程序,平台的AI引擎是一个数据驱动的实时多智体组织,该算法着重于工作者的公平待遇和人类监督的可解释性。
2. 智能用工平台
2.1 智能用工的架构设计
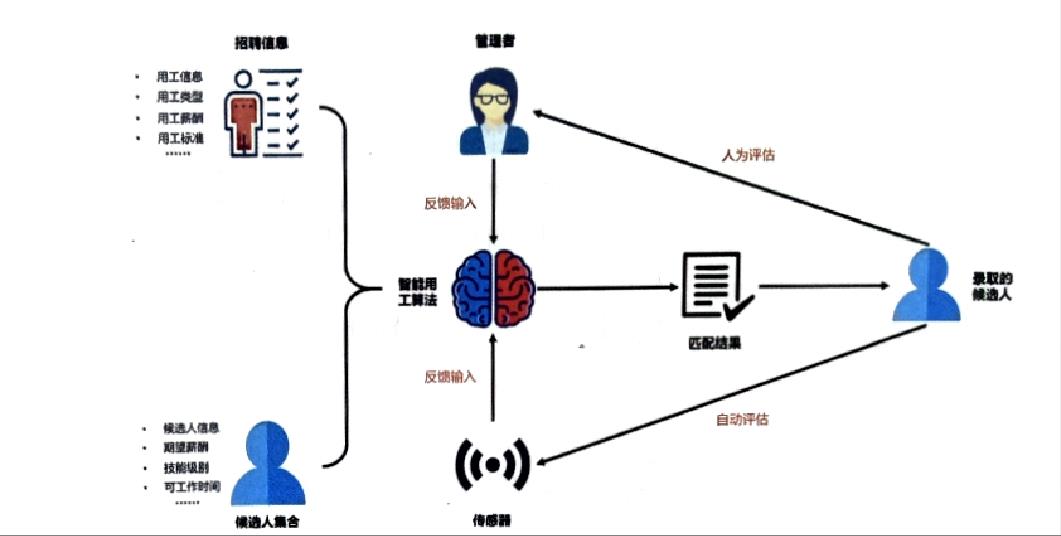
智能用工整体系统架构如下图所示,智能用工系统的AI引擎会根据已有的数据,生成一个初始的候选人录用列表,候选人的能力水平由两个方面反馈:对于定义明确的任务(是否按时上班,是否按时完成工作)可以通过传感器监控,对于定义不明确的任务,由管理者人工评估。
将管理者的评价与传感器监控结果作为输入提供给AL引擎,重新评估当前候选人是否胜任当前工作。
2.2 智能用工的算法设计
为了公平对待工作者,目标是确保能力和生产率相近的工作者长期获得公平的收入,即你的收入要和工作能力相匹配,这样一个目标可以转换为当任何工作者的收入与同类工作者相比时,将其遗憾降到最低。AI引擎采用排队系统的概念模拟工作者的遗憾,用
Y
i
(
t
)
Y_i(t)
Yi(t)表示工作者i在回合t的遗憾,满足下面的动态规划公式:
Y
i
(
t
+
1
)
=
m
a
x
[
0
,
Y
i
(
t
)
+
v
ˉ
(
t
−
1
)
−
v
i
(
t
)
]
Y_i(t+1)=max[0,Y_i(t)+\\barv(t-1)-v_i(t)]
Yi(t+1)=max[0,Yi(t)+vˉ(t−1)−vi(t)]
其中
v
i
(
t
)
v_i(t)
vi(t)是当前回合t中工作者i的收入,
v
ˉ
(
t
−
1
)
\\barv(t-1)
vˉ(t−1)是t-1回合i同类工作者的平均收入,从上式可知,i在t-1回合中,如果收入小于平均收入,它的遗憾值会增加,反之遗憾值减少。
参考李雅普诺夫优化技术,得到t回合工作者的遗憾分布为
l
2
l_2
l2-范数,
L
(
t
)
=
1
2
∑
i
=
1
N
Y
i
2
(
t
)
L(t)=\\frac12\\sum_i=1^NY_i^2(t)
L(t)=21∑i=1NYi2(t),因此工作者收入随时间波动可以表示为:
Δ
=
1
T
∑
t
=
0
T
−
1
[
L
(
t
+
1
)
−
L
(
t
)
]
\\Delta = \\frac1T\\sum_t=0^T-1[L(t+1)-L(t)]
Δ=T1t=0∑T−1[L(t+1)−L(t)]
通过最小化上式,该算法为工作者提供了两个公平维度:
- 在任何给定的任务分配周期中,具有相似能力和生产力的工作者从任务中获得公平收入。
- 工作者的遗憾随时间变化很小。
同时,参与业务的工作者的集体效用,可以被建模为
v
i
(
t
)
q
i
,
j
(
t
)
p
i
(
t
)
v_i(t)q_i,j(t)p_i(t)
vi(t)qi,j(t)pi(t),其中
q
i
,
j
(
t
)
q_i,j(t)
qi,j(t)和
p
i
(
t
)
p_i(t)
pi(t)分别是工作者i对于j类型任务的能力水平和他的生产率,我们的目标是将其最大化,联合目标函数为:
m
a
x
1
N
∑
t
=
0
T
−
1
∑
i
=
1
T
v
i
(
t
)
[
ρ
q
i
,
j
(
t
)
p
i
(
t
)
+
Y
i
(
t
)
]
max\\frac1N\\sum_t=0^T-1\\sum_i=1^Tv_i(t)[\\rho q_i,j(t)p_i(t)+Y_i(t)]
maxN1t=0∑T−1i=1∑Tvi(t)[ρqi,j(t)pi(t)+Yi(t)]
该目标函数满足:
∑
j
=
1
M
1
j
→
i
∈
(
0
,
1
)
,
q
i
,
j
(
t
)
⩾
θ
j
(
t
)
,
∀
i
,
j
,
t
.
\\sum_j=1^M1_j\\rightarrow i\\in (0,1),q_i,j(t)\\geqslant\\theta _j(t),\\forall i,j,t.
j=1∑M1j→i∈(0,1),qi,j(t)⩾θj(t),∀i,j,t.
在这里,
ρ
>
0
\\rho>0
ρ>0是一个控制变量,用于管理者向AI引擎发出信号,告知如何产生更高的收入与公平对待工作者之间进行权衡,
θ
j
(
t
)
\\theta _j(t)
θj(t)是工作者有资格执行某种任务所需的最低能力级别。下图是对AI引擎的概述。
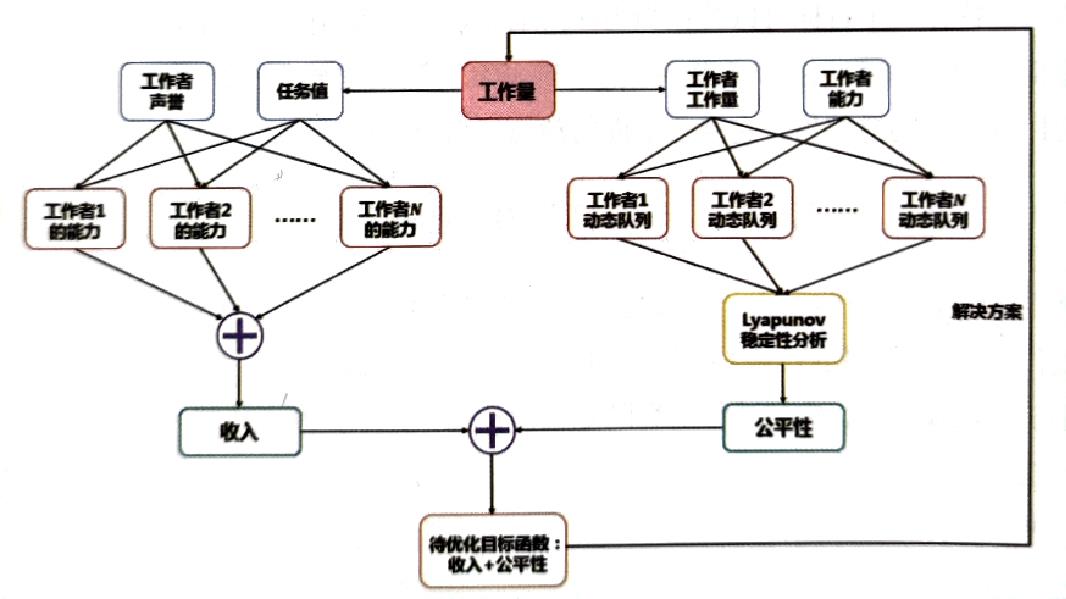
通过参考文献(见原文)开发出的索引排序,可以有效解决优化问题。工作者按照
[
ρ
q
i
,
j
(
t
)
p
i
(
t
)
+
Y
i
(
t
)
]
[\\rho q_i,j(t)p_i(t)+Y_i(t)]
[ρqi,j(t)pi(t)+Yi(t)]索引的降序排列,而任务按其“奖励时间等待时间”值的降序排列,将高级别工作分配给高级别员工,直到找不到更多的任务或更合适的员工为止。如果采用mergesort算法,时间复杂度为O(NlogN),支持大规模运算。
该算法的结果是将工作者的能力、生产率、遗憾、系统管理者偏好、任务奖励和等待时间等细粒度张量映射到任务分配计划中。
3. 利用横向联邦提升智能用工模型
智能用工系统成功的一个关键因素在于对新员工绩效的准确预测。尽管每个企业都可以使用本地存储的工作者数据,但是零散的机器学习模型可能无法提供令人满意的性能,而联邦学习可以在遵守隐私保护法规的同时,利用本地存储的工作者数据构建一个强大的聚合模型。
如下图,每个系统都记录了本地员工数据,这里采用横向联邦技术,在保证数据不出本地前提下,训练更好的模型来预测员工绩效。

4. 设计联邦激励机制
为了维持高质量数据所有方的长期参与,需要联邦学习系统提供适量的激励措施。设计有效、合理的激励机制,其中关键一点是了解参与方在不同激励机制下的决策行为。为此,提出了基于多人博弈游戏的联邦学习激励机制研究——FedGame,以研究联邦中的参与方在不同激励机制下的决策行为。FedGame允许人类玩家作为联邦参与方体验各种不同的联邦环境,并对其决策过程分析并可视化。
4.1 FedGame系统架构
FedGame架构如下所示,人类玩家和电脑玩家作为参与方加入到联邦学习中,在相同市场上竞争。
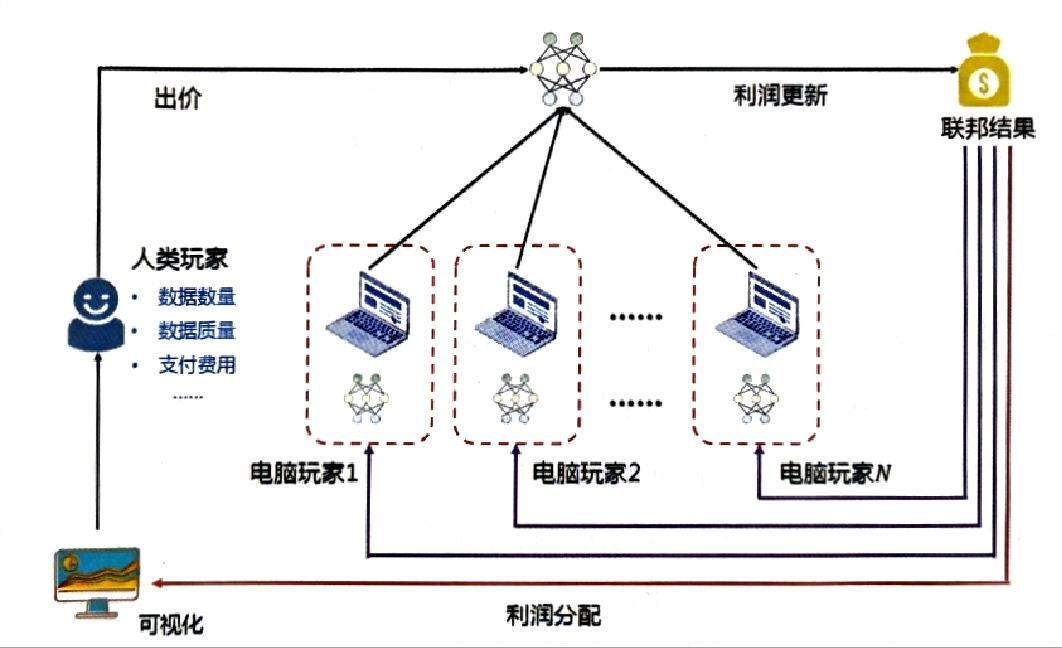
决策涉及资源数量、数据质量、数据数量和愿意支付金额等关键信息。每轮游戏在经过固定回合后结束,玩家的目标是在游戏结束之前尽可能多获得收益,为了激励参与方为联合训练提供高质量数据,并如实上报,游戏着重商业角度构建联邦学习环境。加入联邦的过程涉及三个不同阶段:投标,联邦模型训练,利润共享。FedGame支持以下几种激励机制:
- 线性:参与方在总收益中占据份额与其贡献数据的效用成正比。
- 均衡:联邦利润在所有参与方间平均分配。
- 个体:参与方在总收益中所占份额与其对联邦利润的边际贡献成正比。
- 工会:参与方i在总收益中所占的份额遵循工会博弈收益方案,并且如果i被移除,则与联邦模型的边际效应成正比。
- 夏普利益:根据参与方的夏普利益值分配联邦收益。
阅读总结
总的来说本章内容仍以知识了解为主,并不涉及代码,书中提到了一个很先进的思想, 联邦激励机制,任何一个联邦参与方如果没有利益,那也不会加入到联邦学习中。在我看来,联邦学习的目的,就是一群互不相识的参与方为了利益而进行联邦,无论利益是指更好的模型还是收益,在我阅读并总结的这篇博客中,就介绍了一种个性化隐私激励的联邦学习,它是来自于CCF A类的一篇文章,它很好的权衡了利益与隐私,帮助参与方获得个性化的最大利润,感兴趣的朋友可以阅读一下。
以上是关于阅读笔记联邦学习实战——联邦学习智能用工案例的主要内容,如果未能解决你的问题,请参考以下文章