阅读笔记联邦学习实战——联邦学习医疗健康应用案例
Posted HERODING23
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了阅读笔记联邦学习实战——联邦学习医疗健康应用案例相关的知识,希望对你有一定的参考价值。
联邦学习实战——联邦学习医疗健康应用案例
前言
FATE是微众银行开发的联邦学习平台,是全球首个工业级的联邦学习开源框架,在github上拥有近4000stars,可谓是相当有名气的,该平台为联邦学习提供了完整的生态和社区支持,为联邦学习初学者提供了很好的环境,否则利用python从零开发,那将会是一件非常痛苦的事情。本篇博客内容涉及《联邦学习实战》第十二章内容,使用的fate版本为1.6.0,fate的安装已经在这篇博客中介绍,有需要的朋友可以点击查阅。本章内容主要探讨联邦学习在医疗健康领域的应用。随着AI+医疗的深入,AI辅助技术可以为疾病提供更快速更准确的诊断和治疗。但是医疗领域也面临着数据隐私的困扰,联邦学习可以打破困境,提供一条解决方案。
1. 医疗健康数据概述
医疗健康数据一般是指收集分析得到的消费者的身体和临床数据。包括患者的电子病例、基因序列、医疗保险等数据,这些数据通常过于复杂(高度非结构化、异构、稀疏等特点),以至于使用传统的数据处理方法效果不佳。虽然医学影像研究人员已经通过收集生成了大型高质量数据集(UK Biobank),但是也仅有1400万个对象。
从数据安全角度出发,医疗数据有如下特点:
- 隐私性。
- 稀有性。
- 安全性。
- 复杂。
- 不平衡。
综上,医疗领域的数据孤岛问题是一个很棘手但极具价值的问题。联邦学习可以很好解决上述问题,对于医院自身数据不足的情况,应用横向联邦学习,当没家医院有相同患者的不同检测数据时,适用纵向联邦学习。
2. 联邦医疗大数据与脑卒中预测
脑卒与很多因素有关,包括性别、年龄、种族、不良的生活习惯,本节介绍如何联合多家医院对用户的诊断数据信息,在不泄露用户隐私的前提下,提升脑卒发病预测模型的效果,做到早识别、早预防。
2.1 联邦数据预处理
与集中式训练不同,在联邦学习的场景下,如果没有统一的数据处理标准,将导致各自构建的特征数据无法使用。因此,联邦学习规定各医院的特征输入一致,构建同一套数据标准形成的疾病标签集与特征集,在此特征标准上构建同一套模型。该技术可以不泄露数据的情况下整合多家医院的数据联合进行训练,可应用到重大慢性病的发病预测中。
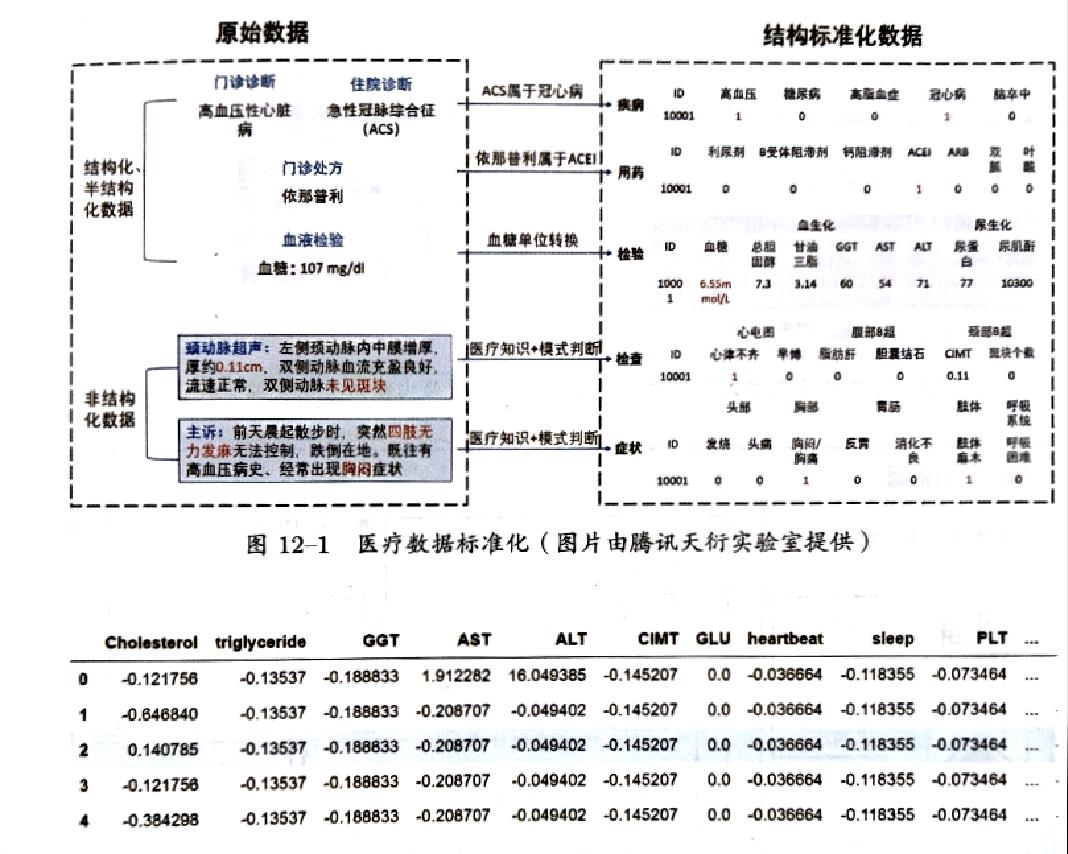
经过数据预处理和标准化处理的样本数据如图所示,包括对结构化、半结构化和非结构化数据的处理。
2.2 联邦学习脑卒中预测系统
整个系统主要由三大部件构成,分别是联邦服务端、联邦客户端、检测和可视化系统。
- 客户端:客户端数据分别存储于各个医院私有的云服务器中,并进行本地训练。
- 服务端:收集来自客户端的数据流,包括客户端ID,训练轮数,模型参数,本地性能等,服务端主要工作是管理数据,模型聚合,性能评估。
- 检测与可视化系统:包括监测客户端状态,收集客户端信息,记录客户端性能以及服务器汇总性能。
由于医疗数据的隐私性,故书中无法提供真实数据,只有部分代码讲解,这里博主也只对代码设计流程进行简单介绍。
- 客户端:每个参与方(即医院)利用自然语言处理,图像特征提取等人工智能技术清洗从医院收集得到的患者数据,并归一化形成结构化的医疗数据。这些数据均存储于每家医院的私有云中。将脑卒中问题转换为一个二分类问题,利用之前处理好的数据,预测患者患病概率。这里采用一个多层感知机作为预测模型。
class Net(nn.Module):
def __init__(input_size, output_size):
super(Net,self).__init__()
self.fc1 = nn.Linear(input_size, 50)
self.fc2 = nn.Linear(50, 10)
self.fc3 = nn.Linear(10, output_size)
nn.init.normal_(self.fc3.weight, mean=0, std=1)
def forward(self, x):
x = F.elu(self.fc1(x))
x = F.elu(self.fc2(x))
return F.log_softmax(self.fc3(x), dim=-1)
- 服务端:服务端主要负责设备管理、模型聚合和性能评估等,服务端会先挑选客户端,并分别下发模型到各个模型进行本地训练。接着接收每个客户端上传模型进行聚合和模型评估,以确认进行迭代还是终止。
- 检测与可视化系统:可视化小程序方便医生实时查看训练结果,包括患者性别比例、正负样本数量,还有一些患者的统计数据直方图。
3. 联邦学习在医疗影像中的应用
在医疗AI中,能给模型带来最有价值信息的通常是医学影像图片。目前,应用于临床的医学影像手段主要包括超声,X光,计算机断层扫描,核磁共振等。当前的医疗图像数据集通常只包括几百张相关数据,这些数据虽然可以通过数据增广等手段训练深度学习模型,但当其被用作真实医疗诊断时,可能会面临覆盖面不足等情况。
3.1 肺结节案例描述
肺结节是指肺内执行小于或者等于3cm的雷元星或者不规则形病灶,影像学表现为密度增高的阴影。不同密度肺结节,恶性概率不同,根据结节密度将肺结节分为三类:实性结节、部分实性结节和磨玻璃密度结节。
肺结节的发病原因也受到多种因素影响,有良性和恶性之分,恶性早期隐匿,如果不早期干预,其病程迅速、恶性度强、预后差,正确判断良恶性,有助于正确的治疗手段。
3.2 数据概述
本案例的目标是,通过给定用户的肺部CT数据集,识别用户患有恶性肺结节的概率。模型分为两个部分,分贝是肺结节检测模型和分类模型。
-
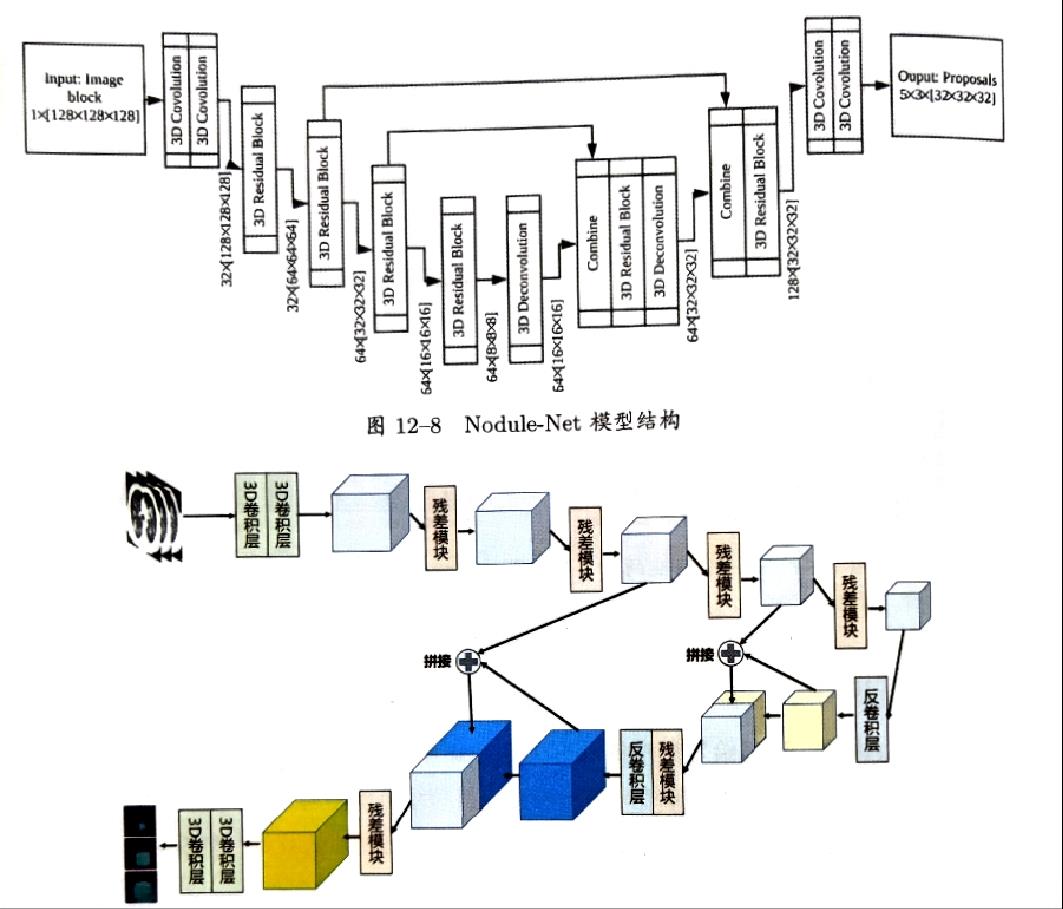
肺结节检测模型:针对3D医疗图片的识别问题,设计了一个三维的卷积神经网络用于检测肺结节的位置。整个网络结构主要由卷积层、残差结构体和反卷积层组成,模型将输出候选肺结节区域图片。
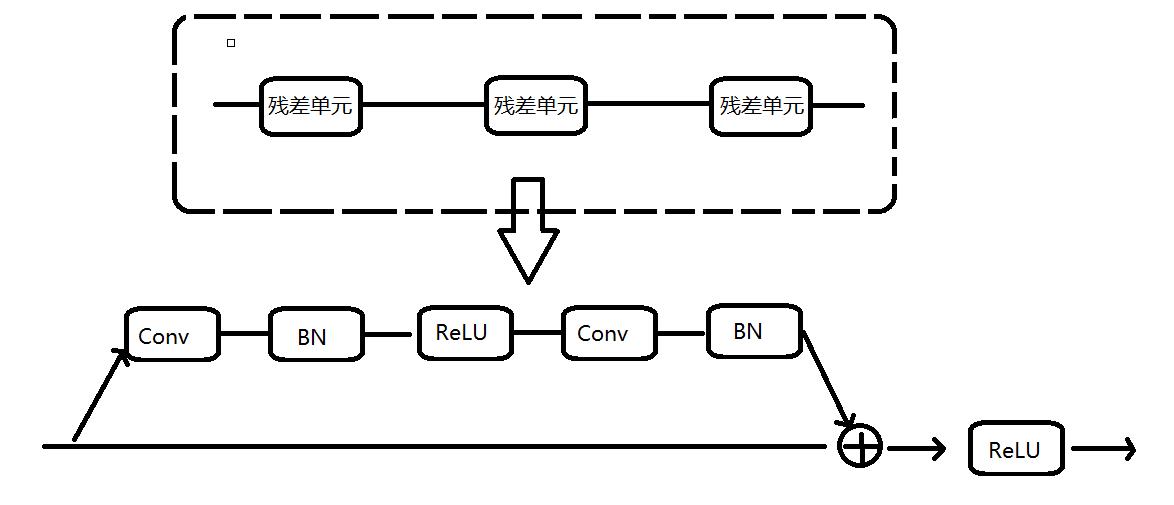
 残差模块是由三个残差单元组成的堆叠结构,如下图所示:
残差模块是由三个残差单元组成的堆叠结构,如下图所示:
-
分类模型:获取到候选的肺结节区域后,下一步判断当前用户得肺结节是良性还是恶性。为此,先将每个用户的CT图片得到的排名最高的5个候选结节区域图片分别重新带入肺结节检测模型中,取最后一个卷积层的输出作为每个候选区域的特征表示,将其带入全连接层中,得到恶性肺结节的概率,如图所示:
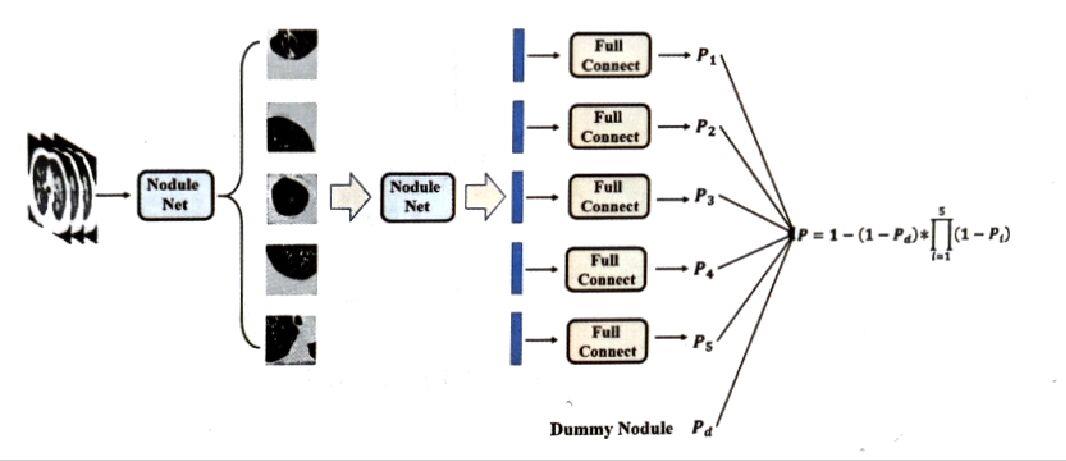 图中,第i个候选区对应的恶性肺结节概率为
p
i
p_i
pi,患有恶性肺结节的概率为:
图中,第i个候选区对应的恶性肺结节概率为
p
i
p_i
pi,患有恶性肺结节的概率为:
P = 1 − ( 1 − P d ) ∗ ∏ i = 1 5 ( 1 − P i ) P=1-(1-P_d)*\\prod_i=1^5(1-P_i) P=1−(1−Pd)∗i=1∏5(1−Pi)
这里引入的参数 P d P_d Pd称为假结节,目的是防止目标检测网络没能发现某些恶性结节而导致将一些良性特征归类为恶性肺结节的特征。
3.3 联邦学习的效果
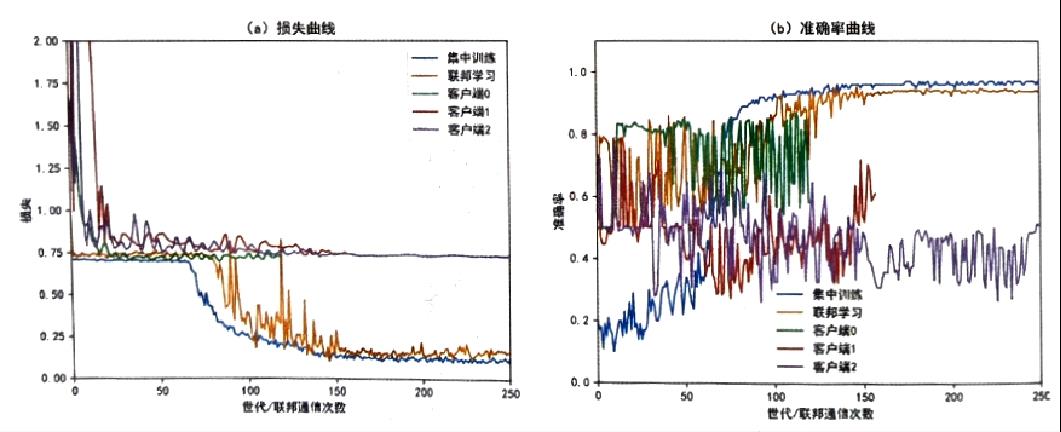
由图看出,联邦学习的性能无论是损失曲线还是准确率,都远胜与任何一家医院数据单独做到的水平,相对于集中式的机器学习训练,联邦学习还是稍显不稳定,但最终仍能收敛得到非常接近的损失及准确率。
阅读总结
通过本章内容的学习,较为深入了解了联邦学习在医学领域的应用,虽然总体实现的过程和普通的横向联邦学习过程无意,但是对于医疗数据的预处理,尤其是半结构化和非结构化数据的处理,给了我很深刻的印象。虽然本章内容涉及隐私,代码和数据无法公开,但是为日后医学领域数据的脱敏联邦应用,还是提供了很好的范本。
以上是关于阅读笔记联邦学习实战——联邦学习医疗健康应用案例的主要内容,如果未能解决你的问题,请参考以下文章