大数据学习之路,yarn的介绍
Posted MC柱柱
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据学习之路,yarn的介绍相关的知识,希望对你有一定的参考价值。
yarn 资源调度分配
Mapreduce on yarn
yarn主要的模块
ResourceManager(RM)
yarn的资源控制框架的中心模块,负责集群中所有的资源的统一管理和分配。
ResourceScheduler(调度器)
根据各个应用程序的资源需求,进行分配。
Applications Manger(应用管理器)
负责监控或跟踪AM的执行状态。
NodeManger(名称节点,简称NM)
是ResourceManager每台机器上的代理,负责容器的管理,并监控他们的资源使用情况(CPU,内存,磁盘,网络等等)以及向RM提供这些资源的使用汇报
ApplicationMaster(AM)
yarn中每个应用都会启动一个AM,负责向RM去申请资源。请求NameNode启动container,并告诉container需要做什么。
container(容器)
这是一个虚拟的一个概念,yarn中所有应用都是在container之上运行的,包括applicatioMaster;
1.container是yarn中资源的抽象,它封装了某个节点上一定的资源(CPU,内存,磁盘,网络等)
2.container由AM向RM申请,由RM中的ResourceScheduler分配给AM
注:
1.运行AM的container
2.运行各类任务的container,由AM向RM申请的
MapReduce on yarn
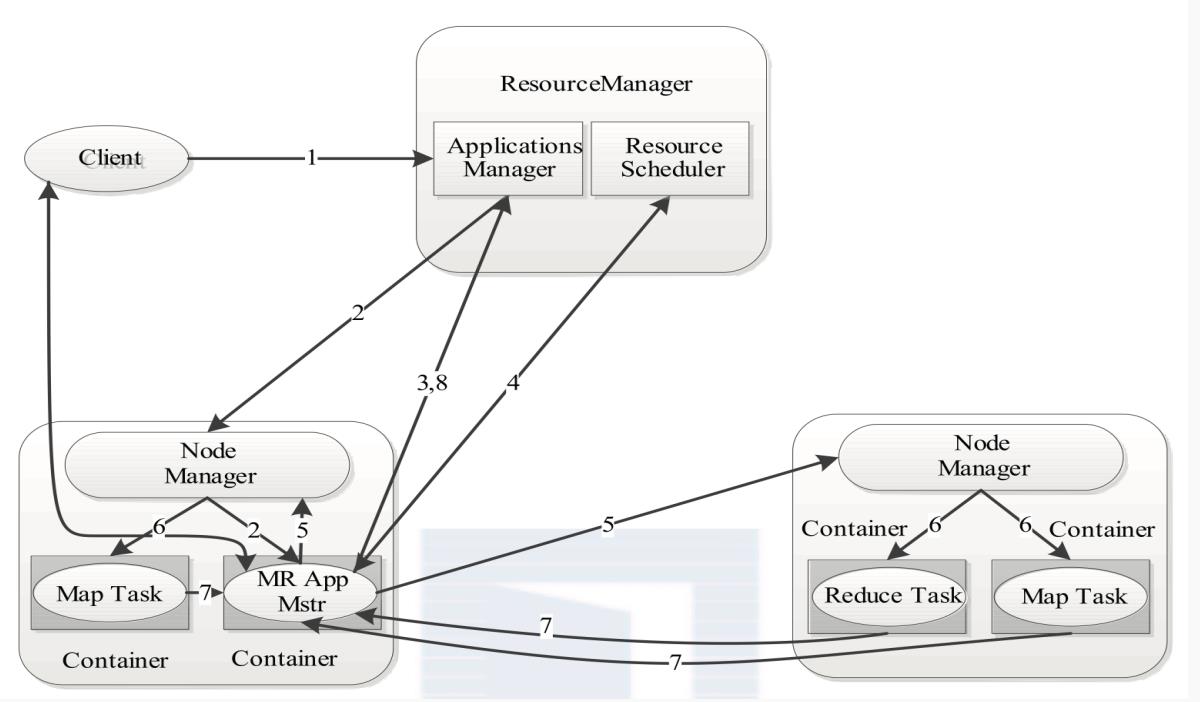
1.client向RM提交应用程序,其中包括AM主程序,启动AM的命令,用户的程序(wordcount)
2.RM为该应用分配第一个container,并与NameNode通信,要求NameNode在这个container中启动AM
3.AM首先向RM注册,这样用户可以通过RM来查看程序状态
4.AM通过RPC协议向ResourceScheduler申领资源
5.一旦AM申领到了资源,与NameNode通信,要求NameNode启动任务。
6.NameNode为任务设置好运行环境(环境变量,jar包等等),将这个任务的启动命令写到一个脚本中,并通过脚本触发启动任务(wc.sh hadoop jar share /…)
7.各个container的Task(Map Task,Reduce Task),通过RPC向AM进行进度和状态汇报,以便AM随时可以掌握任务的运行状态失败的时候,也会重启container任务。
8.应用程序运行完成后,AM向RM申请注销和关闭
总的来说:1-4步启动ApplicationMaster,领取资源;5-8步运行任务,直至任务完成。
MapReduce on yarn
Spark on yarn
引申出的其他面试题
1.AM在哪个进程所在的节点运行?
答:NM
2.AM要申请container吗?向谁申请的?要向RM申请的
答:
3.一个作业,第一个container容器运行什么
答:
理想情况下,我们应用对yarn资源的请求,应该立刻被满足,但是实际上,资源有限。特别是很忙的集群,比如说1-3点,1.05开始运行,1.40才实际上开始运行,任务很多,需要等待。
yarn中负责分配资源的就是Scheduler
调度本身就是一个大难题,很难找到完美的解决方案,所以yarn提供了三种调度器:
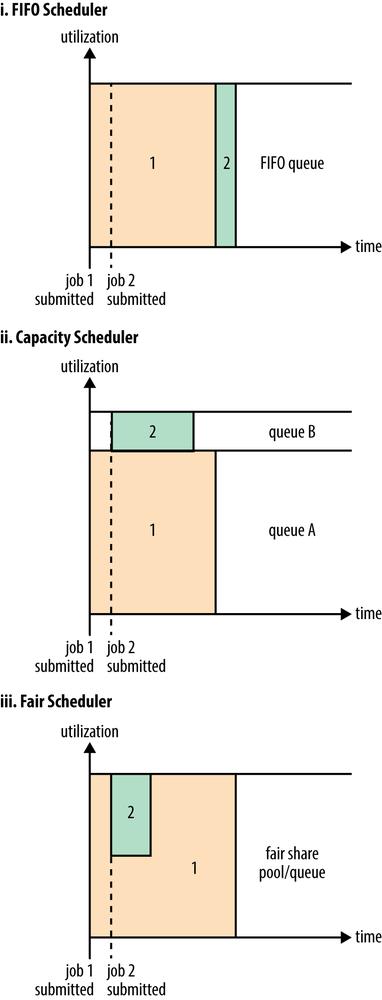
1.FIFO Scheduler
FIFO =first in first out 队列
这种调度器把应用按顺序排成一个队列,先进先出的队列,在进行资源分配的时候,先给队列中最头部的应用分配资源
问题:大的应用可能会占用所有的资源,造成阻塞,不适合集群
2.Capacity Scheduler
专门有一个队列来运行小任务,但是为小任务专门设置的队列会占用一定的集群资源,导致大任务的执行时间会落后于FIFO;
3.Fair Scheduler
不需要预先占用一定资源,动态调整,比如第一个是大任务,且只有这个大任务在运行,那么把所有资源都给它,然后第二个小任务提交了,Fair Scheduler就会分配一半资源给小任务,公平的共享资源,小任务跑完了,还是会把所有资源给到大任务。
MapReduce
主要运行的语言:java SQL
" easily writing applications"轻松编写应用程序
对于任何容错,如何进行RPC通信等,开发人员不再关注,关注我们业务逻辑就可以,这方面来讲,easily业务逻辑+MR框架自带的内置的组件=》分布式应用程序开发,但是呢 用MR来做开发,很麻烦,相较于Spark
MapReduce-适用/不适用场景
适用:离线、批处理
不适用:实时计算
Map:映射 把一个任务拆解成多个
Reduce:聚合 把拆解开的任务做最后的聚合操作
以上是关于大数据学习之路,yarn的介绍的主要内容,如果未能解决你的问题,请参考以下文章