spark学习之执行计划explain
Posted 柳小葱
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark学习之执行计划explain相关的知识,希望对你有一定的参考价值。
🐼今天我们来学习阅读spark的执行计划,在学习执行计划之前,我们需要了解spark中的代码是如何执行的,学习代码的执行过程有助于我们加深对spark的理解,对往期内容感兴趣的同学可以查看👇:
- hadoop专题: hadoop系列文章.
- spark专题: spark系列文章.
- flink专题: Flink系列文章.
🐰本文主要是讲解spark sql的代码,从本质上说,操作dataframe和sql,spark都将转换为相同的底层执行计划,那我们这里就以sql代码执行为例。
目录
1. spark代码处理流程
1.1 代码处理详细过程
流程图如下:
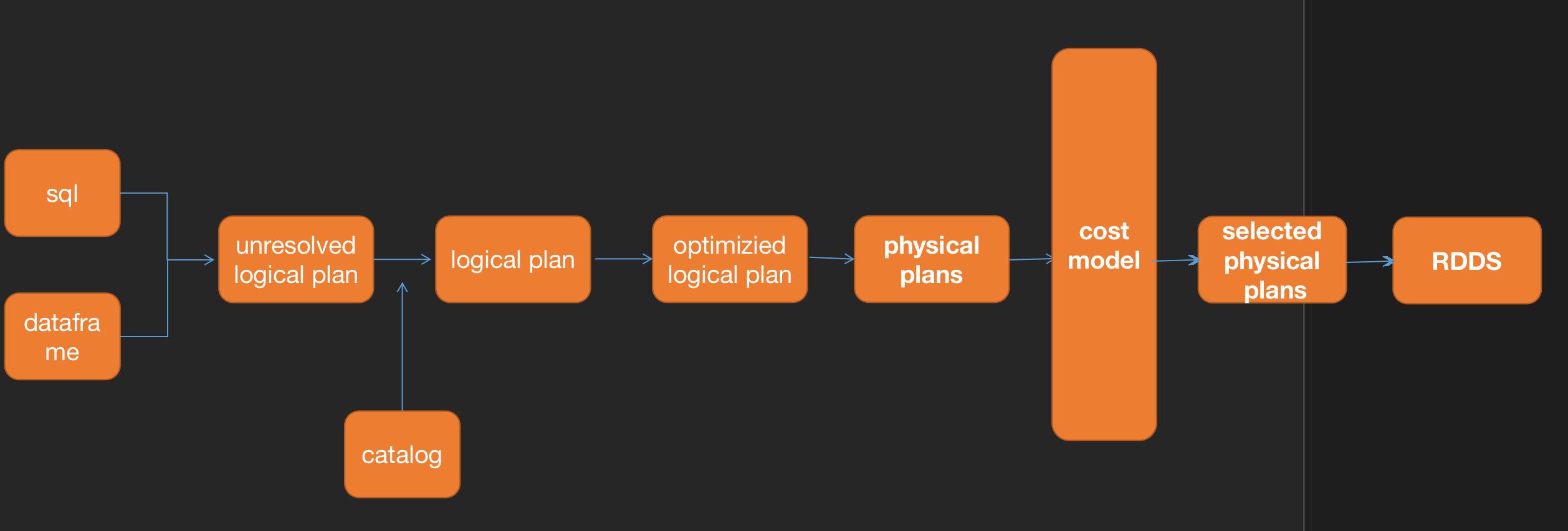
- 将sql语句转化为未决断的逻辑执行计划(未决断的意思就是只验证了sql语法的正确性,未验证表名列名的正确性)
- 使用catalog验证第一步中的表名列名信息,转化为逻辑执行计划(catalog描述了数据集的属性和数据集的位置)
- 接着对我们的sql语法进行优化,得到优化后的逻辑执行计划
- 优化后的逻辑执行计划转化为物理执行计划
- 根据合适CBO(代价选择)将物理执行计划转化为可以执行的代码
- 转化为rdd去执行任务
1.2 核心过程

- 分析
- 逻辑优化
- 生成物理执行计划
- 评估模型分析
- 代码生成
2. spark查看执行计划
2.1 explain的用法
下面介绍如何使用explain查询几种执行计划
- explain():只展示物理执行计划。(使用较多)
- explain(mode=“simple”):只展示物理执行计划。
- explain(mode=“extended”):展示物理执行计划和逻辑执行计划。
- explain(mode=“codegen”) :展示要 Codegen 生成的可执行 Java 代码。(使用较多)
- explain(mode=“cost”):展示优化后的逻辑执行计划以及相关的统计。
- explain(mode=“formatted”):以分隔的方式输出,它会输出更易读的物理执行计划,并展示每个节点的详细信息。
演示一下:我们这里有student表和score表,连接分组操作。
sqlway=spark.sql("""
select student.s_id,count(1)
from student
left join score
on student.s_id=score.s_id
group by student.s_id
""")
sqlway.explain(mode="extended")#展示物理执行计划和逻辑执行计划。
展示逻辑和物理执行计划结果如下:
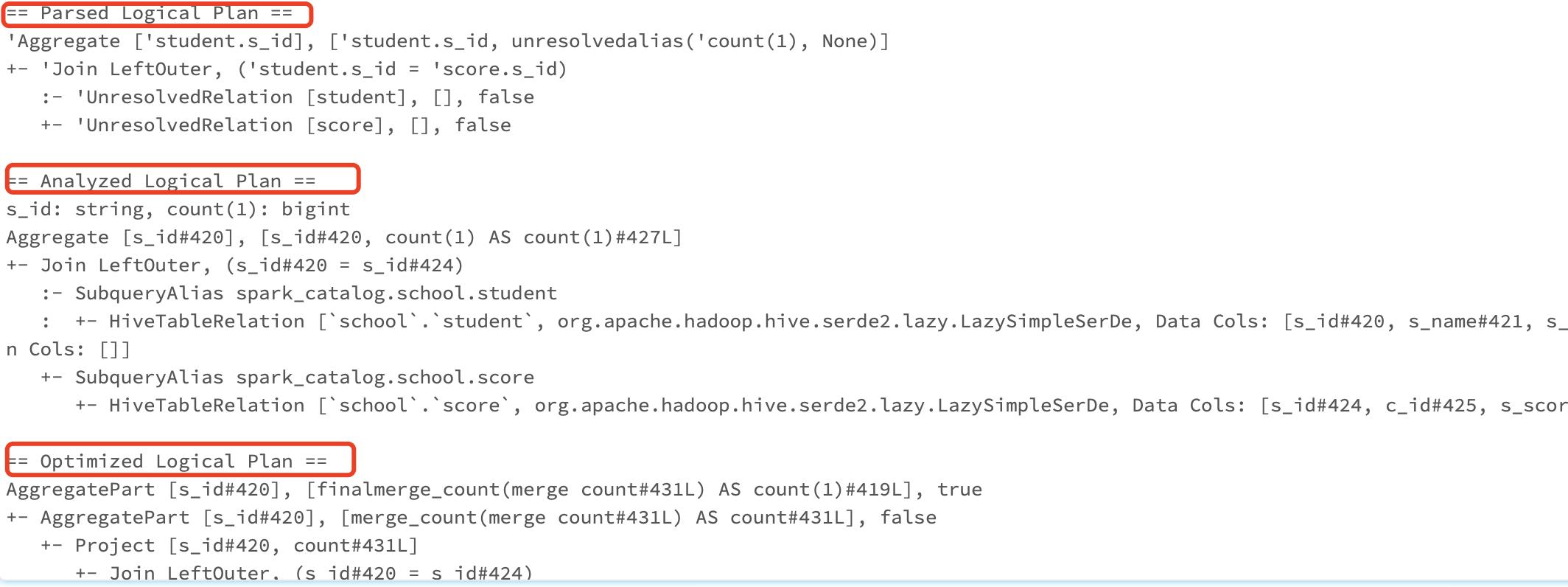
图片中的各个部分解释如下:
- Unresolved 逻辑执行计划:== Parsed Logical Plan ==
含义:Parser 组件检查 SQL 语法上是否有问题,然后生成 Unresolved(未决断)的逻辑计划,不检查表名、不检查列名。 - Resolved 逻辑执行计划:== Analyzed Logical Plan ==
含义:通过访问 Spark 中的 Catalog 存储库来解析验证语义、列名、类型、表名等。 - 优化后的逻辑执行计划:== Optimized Logical Plan ==
含义:Catalyst 优化器根据各种规则进行优化。 - 物理执行计划:== Physical Plan ==
含义:生成java代码执行
3. spark阅读执行计划
这一部分将通过第二部分中的代码产生的执行进行解读。
悄悄告诉你们,执行计划的阅读方式是从下往上阅读。
3.1 阅读 Parsed Logical Plan

这一部分显示的是未决断的逻辑执行计划。从下至上依次是查看表名,然后join,然后聚合。
3.2 阅读 Analyzed Logical Plan

这一部分,是加入了catalog验证表名和列名之后的执行计划,和上一部分的很像,但增加了表的相关信息,#号代表列的序号,L代表长整型整数。
3.3 阅读 Optimized Logical Plan
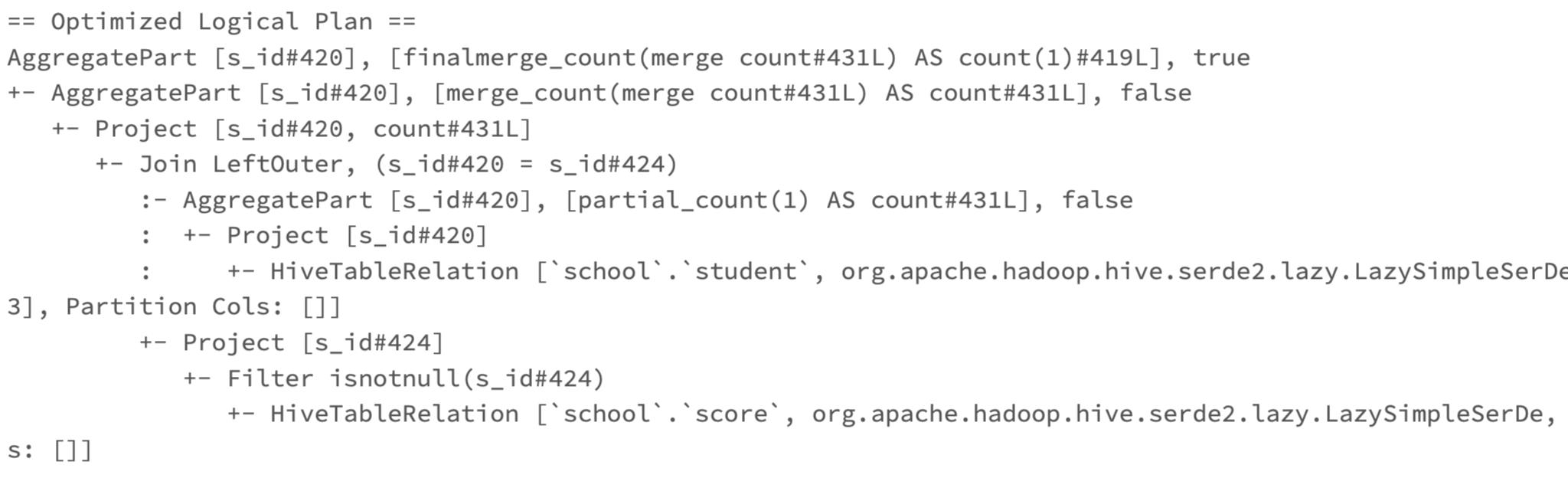
这一部分,是优化后的逻辑执行计划,加入了判断空值、自动过滤等功能,优化了逻辑执行过程。
3.4 阅读 Physical Plan
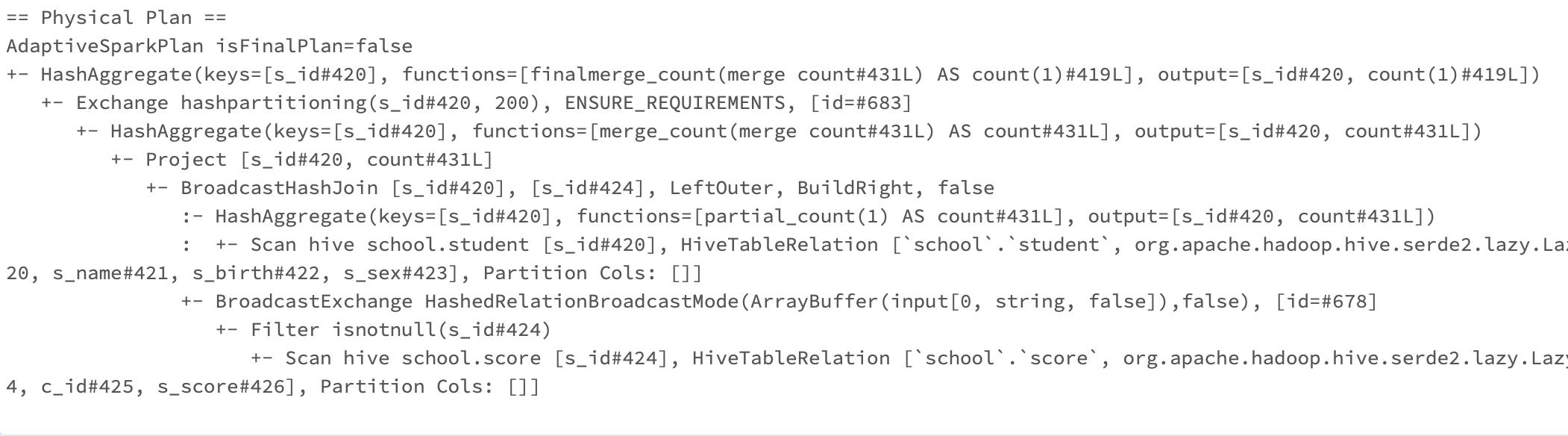
这一部分,介绍一些物理执行计划中的名词:
- HashAggregate:表示数据聚合,一般 HashAggregate 是成对出现,第一个HashAggregate 是将执行节点本地的数据进行局部聚合,另一个 HashAggregate 是将各个分区的数据进一步进行聚合计算。
- Exchange:表示shuffle,表示需要在集群上移动数据。很多时候HashAggregate 会以 Exchange 分隔开来。
- Project:表示 SQL 中的投影操作,就是选择列(例如:select name, age…)
- BroadcastHashJoin:表示通过基于广播方式进行 HashJoin。
- LocalTableScan :表示全表扫描本地的表。
根据这些,我们可以看出,物理执行计划会去寻找表所在的文件位置,取出所需要的列,规约(预聚合),广播,join的方式,聚合的列等等信息。
4. 总结
在这一部分中,我们对spark sql对运行原理和执行计划进行了说明,学习这一部分的主要原因是让我们更加了解spark的运行机制,为后面我们学习spark的优化做基础。
5. 参考资料
- 尚硅谷spark3.0
- spark权威指南
以上是关于spark学习之执行计划explain的主要内容,如果未能解决你的问题,请参考以下文章